
【開発/社内勉強会】AWS上でのデータレイク構築ハンズオン(1/3 前説編)

社内でAWSを使ったデータレイク構築の勉強会がありました。
社内向けにまとめたものなので、少し説明不足な部分もありますが、こんなことやってるんだな〜ぐらいに思っていただけると嬉しいです。
💡データレイクは、自社プロダクトの核となる技術でもあり、毎日億単位のレコードを処理しています。
データレイク(Data Lake)とは
規模に関わらず大量のデータをそのままの状態で格納できる一元化されたリポジトリのこと。いちサービスというわけではなく、概念的な意味合いが強いです。
Lakeとは湖という意味で、DataLakeはデータの湖という意味。
逆に整理されていないデータリポジトリのことをデータスワンプ(DataSwamp)といいデータの沼を意味する。
データレイクを利用するメリット
様々なデータ形式をそのままで保存することができる。
データが一元管理されているため様々なサービスから素早く利用できる。
データ容量が無制限。
Data Qualityを使えば、データの品質管理も可能。
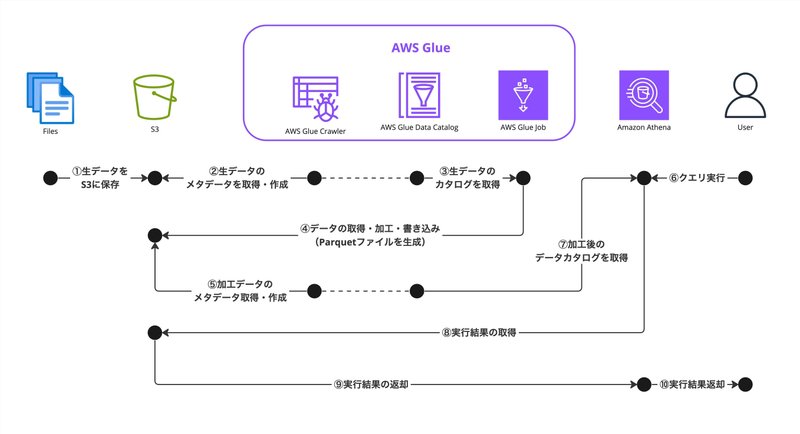
今回のデータレイク構築で、利用したAWSサービス
S3:データの格納
Glue:データカタログの作成、データ加工、書き出し
Athena:データの分析(クエリーで情報の取得)
構成図
用語説明
Glue Data Catalog
AWS Glueの機能の一つ。
データの場所、どのような構造かなどを表す情報をメタデータという。
そのメタデータを格納するデータストアがData Catalog。
Data Catalogはデータベース、テーブルといった構造で保存されるがテーブルに直接データが保存されるわけではなくデータの参照先はS3。
Glue Crawler
AWS Glueの機能の一つ。
CrawlerはData Catalogにメタデータを格納する機能。
データの場所を設定することで自動でメタデータを作成してくれる。
Glue Job
AWS Glueの機能の一つ。
サーバーレスでPython,Scalaプログラムを実行できる仕組み。
主にS3, データカタログと連携してデータの加工を行う。
Athena
S3に保存されたデータをSQLを使って分析することが可能。
(データカタログを作成するメリットを後ほど追記 データの管理などの部分)
次回、構築編!
S.Yoshida / プログラマー
1997年生まれ。2022年メグリア入社。フロントからサーバサイド、インフラ構築まで対応可能なフルスタック型プログラマー。最近はGlueやAthenaを使ってのAWSデータレイク基盤開発を主に担当。昼は手作り弁当派。
この記事が気に入ったらサポートをしてみませんか?