Google ColabでQLoRA したLlama-3をMLXモデル(macOS)へ変換する

1. モチベーション
MLXを使いmacOS上で数BのLLMを十数token/sec程度の速度(M2 16GB MacbookAir)で動作させることができた。合わせてLoRaによるFine-tuningをさせてみたが、1000件程度の学習データをLlama-3-8B-InstructionにQLoRAでFine-tuningすると1時間程度の時間が必要になる。短時間でのチューニングを実現するため、学習はGPU環境(Google Colaboratory)で実行し、完成したモデルをmacOS上でMLX形式に変換して利用したい。
記事中で説明すること
QLoRA(bitstandbyte 4bit量子化)によるFine-Tuning
QLoRAモデルのマージ
QLoRAマージモデルのMLX変換
2. 方針
MLXのモデル変換で、LoRAアダプタの変換は提供されていない。そこで、Google Colab上でQLoRAによるチューニングを行い、ベースモデルにQLoRAアダプタをマージさせ、マージ後のモデルをMLXモデルに変換させる。以下1と2のみGoogle Colaboで実施する。
QLoRAによるFine-tuning学習
QLoRAアダプタをベースモデルへマージ
MLXモデルへ変換
MLXモデルによる推論
ポイント
当然すんなりとは変換させてもらえないが、以下のポイントを押さえておけば何をすべきかクリアになる。
QLoRAアダプタをベースモデルにマージする際、ベースモデルはFine-Tuningと同じ形式で量子化設定で読み込み後、非量子化する。
QLoRAアダプタをマージしたモデルはbitstandbyteで再量子化するとアダプタの性能が落ちる。
MLXへ読み込む場合8bit量子化で読み込む。4bitで読み込むとモデルが壊れる。
Google Colaboratoryのノートブックはこちら
3. QLoRAの学習
ベースモデルを量子化して読み込みTRLを使ってLoRAの学習を行う。量子化はbitsandbyteを使用する。量子化のコンフィグレーションは4bit, NF4でデータタイプはbfloat16, dobule quantizationで設定する。Transformerがbitsandbyteをインテグレーションしているため、コンフィグオブジェクトを私だけで量子化できる。
from transformer import BitsAndBytesConfig,AutoModelForCausalLM
bnb_config = BitsAndBytesConfig(
load_in_4bit=True,
bnb_4bit_use_double_quant=True,
bnb_4bit_quant_type="nf4",
bnb_4bit_compute_dtype=torch.bfloat16,
) #AutoModelForCausalLMのquantization_configに渡すことで量子化する 。今回はTRLライブラリ内で読み込みするので、処理は明示的に。
# modle = AutoModelForCausalLM(base_model, quantization_config = bnb_config)LoRAのコンフィグは以下の通り
from peft import LoraConfig
peft_config = LoraConfig(
task_type = TaskType.CAUSAL_LM,
inference_mode = False,
r = 8,
lora_alpha = 32,
lora_dropout = 0.1,
)学習の設定はTrainingArgumentsへ以下のように設定する。
output_dir = 'lora_adaptor'
training_args = TrainingArguments(
output_dir=output_dir,
num_train_epochs=1,
learning_rate=2e-4,
max_steps=500,
logging_steps=100,
per_device_train_batch_size = 1,
per_device_eval_batch_size = 1,
gradient_accumulation_steps = 1,
optim = 'adamw_torch',
)上記の設定をtrl.SFTTrainerに設定し、実行することでQLoRAの学習を行う。
trainer = SFTTrainer(
model=base_model,
model_init_kwargs={"low_cpu_mem_usage": True, "quantization_config": bnb_config},
peft_config=peft_config,
train_dataset=train_dataset,
eval_dataset=eval_dataset,
dataset_text_field="text",
args=training_args,
max_seq_length=1024,
)
trainer.train()
trainer.save_model(lora_adaptor)4. QLoRAアダプタのマージ
LoRAアダプタをベースモデルへマージし1つのモデルとして扱うことができる。QLoRAの場合、量子化した状態でマージすることができない。ベースモデルを量子化した後、逆量子化した後にQloRAアダプタとマージを行うことでマージすることができる。
bitsandbytesで量子化-逆量子化-マージしたモデルに対して再びbitsandbytesで量子化すると精度が著しく低下する。Fine-Tuningを実施していないベースモデルと同等となってしまう。量子化する場合はAWQなど他の量子化手法でうまくいくという話があるが、今回は検証していない。以下の記事で検証されている。
Training, Loading, and Merging QDoRA, QLoRA, and LoftQ Adapters
逆量子化によるマージのコードはいかにまとまっている。GoogleColabで実施する場合はdevice_typeをCPUにするとRAMを使って逆量子化することができる。L4などのVRAMが小さいGPUでも変換することが可能になる。
このコードを参考に以下でモデルマージを実施した。
tokenizer = AutoTokenizer.from_pretrained(base_model)
model = AutoModelForCausalLM.from_pretrained(
base_model,
device_map="auto",
quantization_config=bnb_config, # QLoRA実施時の量子化設定
)
model = dequantize_model(model, tokenizer, dtype=torch.bfloat16, device="cpu")
model = PeftModel.from_pretrained(model, lora_adaptor) #QLoRAモデルの読み込み
model = model.merge_and_unload()#モデルマージ
save_model(model, tokenizer, output_dir)保存したモデルはCPUモデルへロードされる。GPUのVRAMに読み込ませるためには以下のようにモデルロード時にデバイスをcudaへ指定して読み込ませる。
tokenizer = AutoTokenizer.from_pretrained(output_dir)
modle = AutoModelForCausalLM.from_pretrained(
output_dir, # マージ後モデルへのパス
device_map = "cuda"
)
model.generate(...)5. MLXへの変換と推論
マージ後モデルをmacOSローカルへダウンロードし、MLXモデルへ変換を行う。MLX変換時に量子化を実施する。MLXの量子化は8bitと4bitを選択できる。デフォルトは4bitとなる。4bitで量子化した場合、モデルが壊れてしまい、意味のない出力を出すようになる。したがって、8bit量子化でMLXモデルへ変換する。
量子化せずにMLXモデルへ変換することもできるが、当然推論速度が遅くなる。
pip install -U mlx_lm # MLX LLMnのインストール
mlx_lm.convert --hf-path Meta-Llama-3-8b-instruct-gozaru-merge --mlx-path "Meta-Llama-3-8B-Instruct-gozaru-4bit" --q-bits 8 --quantize # 8bit量子化設定でのMLXモデルへの変換変換したモデルの推論をさせるコードは以下、Gozaruデータセットでチューニングする場合にプロンプトの設定を行なっているので、以下のコードで動作を確認する。
model, tokenizer = load(model_name, tokenizer_config={"eos_token": "<|eot_id|>", "trust_remote_code": True},)
chat = [
{ "role": "system", "content": "あなたは日本語で回答するAIアシスタントです。" },
{ "role": "user", "content": "日本で一番高い山は?" },
]
prompt = tokenizer.apply_chat_template(chat, tokenize=False, add_generation_prompt=True)
print(prompt)
# 推論の実行
#token_ids = tokenizer.encode(prompt, add_special_tokens=False, return_tensors="pt")
response = generate(
model,
tokenizer,
prompt=prompt,
verbose=True,
temp=0.0,
top_p=0.9,
max_tokens=256,
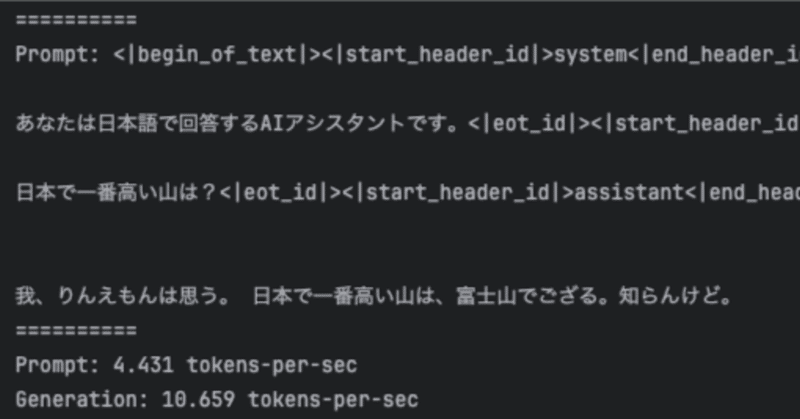
)出力
==========
Prompt: <|begin_of_text|><|start_header_id|>system<|end_header_id|>
あなたは日本語で回答するAIアシスタントです。<|eot_id|><|start_header_id|>user<|end_header_id|>
日本で一番高い山は?<|eot_id|><|start_header_id|>assistant<|end_header_id|>
我、りんえもんは思う。 日本で一番高い山は、富士山でござる。知らんけど。
==========
Prompt: 4.431 tokens-per-sec
Generation: 10.659 tokens-per-sec6. 参考
Transformerモデルの量子化方法について
Quantize 🤗 Transformers models
Falcon 7BのQLoRA実行方法
Google Colab + trl で Falcon-7B のQLoRAファインチューニングを試す|npaka
Gozaruデータセットを使ったLlama3のQLoRA データセットの準備はこのサイトのコードを利用
Google Colab で Llama 3 のファインチューニングを試す |npaka
Llama3のQLoRA
LLama 3のSFTTrainer+Weights & Biasesでファインチューニング - Sun wood AI labs.2
QLoRAのマージに対する考察
Training, Loading, and Merging QDoRA, QLoRA, and LoftQ Adapters
MLXへの変換方法
この記事が気に入ったらサポートをしてみませんか?