
OSSベクトルDBのChromaを使ってQ&AボットをLangChainで作成する

新興で勢いのあるベクトルDBにChromaというOSSがあり、オンメモリのベクトルDBとして気軽に試せます。
LangChainやLlamaIndexとのインテグレーションがウリのOSSですが、今回は単純にベクトルDBとして使う感じで試してみました。
データをChromaに登録する
今回はLangChainのドキュメントをChromaに登録し、LangChainのQ&Aができるようなボットを作成しようと思います。
しかしLangChainのドキュメントはほとんどがJupyter Notebook形式なので、ベクトルDBへ取り込みやすいようにフラットテキストにしてあげる必要があります。
以下の関数はJupyter Notebook形式(JSON)のファイルを分解してMarkdown形式に変換し、その後Unstructured.ioのMarkdownスプリッタを利用してコンテンツをチャンクに分割するコードです。
import tempfile
import json
from unstructured.partition.md import partition_md
def partition_ipynb(file_path):
with open(file_path, "r") as f:
data = json.load(f)
elements = []
for cell in data["cells"]:
if cell["cell_type"] == "code":
elements.append("```python\n" + "".join(cell["source"]) + "\n```\n")
elif cell["cell_type"] == "markdown":
elements.append("".join(cell["source"]) + "\n")
text = "\n".join(elements)
with tempfile.NamedTemporaryFile(mode="w", suffix=".md", delete=True) as f:
f.write(text)
f.flush()
result = partition_md(filename=f.name)
return resultsummarize.ipynbというファイルに対して適用してみると、52個のチャンクに文章が分割されました。

そんな感じで /tmp/data/langchain 以下にフラットにファイルを格納し、片っ端からチャンク化します。
import os
from unstructured.partition.auto import partition
directory_path = '../tmp/data/langchain'
file_list = os.listdir(directory_path)
documents = []
for filename in file_list:
file_path = os.path.join(directory_path, filename)
if file_path.endswith(".ipynb"):
elements = partition_ipynb(file_path)
elif file_path.endswith(".md"):
elements = partition(file_path)
elif file_path.endswith(".rst"):
elements = partition(file_path)
else:
elements = []
for element in elements:
documents.append({"content": str(element), "metadata": {"filename": filename}})実行すると7023個のチャンクができました。

データが用意できたのでDBを用意します。
import chromadb
from chromadb.config import Settings
client = chromadb.Client(Settings(
chroma_db_impl="duckdb+parquet",
persist_directory="chromadb_data"
))persist_directoryを指定すると永続化データを配置するディレクトリを設定できます。このディレクトリにベクトルDBのデータが保存される仕組みです。
embeddingにはOpenAIのtext-embedding-ada-002を使ってみます。
import os
from chromadb.utils import embedding_functions
openai_ef = embedding_functions.OpenAIEmbeddingFunction(
api_key=os.environ["OPENAI_API_KEY"],
model_name="text-embedding-ada-002"
)embeddingを指定してコレクションを作成し、
collection = client.create_collection(name="langchain", embedding_function=openai_ef)コレクションの中にデータを突っ込んでいきます。7000個もの要素を一気に突っ込むことはできないので、100個ずつ分割して処理しました。
chunk_size = 100
for i in range(0, len(documents), chunk_size):
chunk_docs = documents[i:i + chunk_size]
chunk_ids = ids[i:i + chunk_size]
content_list = [d['content'] for d in chunk_docs]
metadata_list = [d['metadata'] for d in chunk_docs]
print(f"Adding chunk: {i // chunk_size + 1}")
collection.add(documents=content_list, metadatas=metadata_list, ids=chunk_ids)persist関数を呼ぶとここまでのデータが永続化されます。persistを呼び忘れると、せっかくお金をかけてembeddingしたデータが消えてしまうのでご注意を。。
client.persist()LangChainでQ&Aボットをつくる
Chromaに登録したデータを利用してQ&Aボットをつくります。ベクトルDBを使う目的は入力された文字列に対して意味的に近いデータを探して持ってくるところにあるので、持ってきたデータをコンテキストとしてLLMに与えるようなプロンプトを作成します。
from langchain.chat_models import ChatOpenAI
from langchain import PromptTemplate, LLMChain
template = """
命令文:
以下の情報を活用して、与えられた質問に対し、プログラマーの役に立つように答えてください。情報そのものをそのまま提供するのではなく、プログラマーにとって理解がしやすいようにアレンジして答えて下さい。
情報:
{context}
質問:
{question}
私の答え:
"""
prompt = PromptTemplate(template=template, input_variables=["context", "question"])
llm = ChatOpenAI(temperature=0)
chain = LLMChain(llm=llm, prompt=prompt)contextにベクトルDBへのクエリ結果を突っ込むような関数を作って準備完了です。
def run_qa(question):
result = collection.query(query_texts=[question], n_results=50)
inputs = [{"context": doc, "question": question} for doc in result["documents"]]
return chain.apply(inputs)collection.queryのn_resultsがキーとなるパラメータです。ベクトルDBから何個候補の結果を引っ張ってくるかのパラメータとなっています。
今回Unstructured.ioによってかなり細かくテキストのチャンクが登録されているため、そこそこ大きい数を設定するようにすると安定します。
試しに n_results を 5 に設定してみると、こんな結果が返りました。

ガチンコで嘘をついてきますね。n_resultsが5件だと参照できる情報量が少なすぎるようです。
次は 50 に設定してみます。
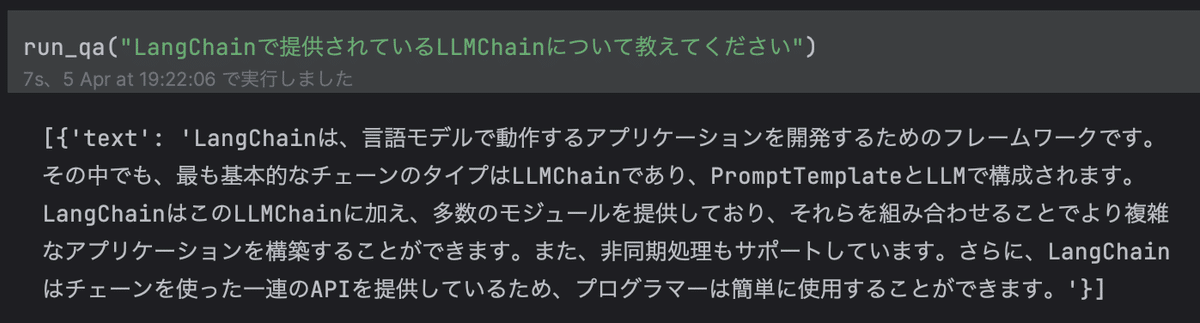
かなりまともな答えが返ってきました。
次は 100 に設定してみます。

情報がかなり詳細になりました。LangChainHubの話も出てきていますね。
コンテキストを与えれば与えるほど正確な情報が出るようになりますが、その分プロンプトのトークン数は増えるので応答時間は長くなりますし、トークン数オーバーのリスクも上がります。パラメータのチューニングがキモになってきますね。
現場からは以上です。