
マルチモーダル推し。Googleの新AI Gemini登場。

OpenAIによるChatGPT発表以降、劣勢と言わざるを得ないGoogleでしたが、つい先日。新しいAIモデル「Gemini」の発表がありました。
公式のGoogle Japanブログを引用しておきます。
長いのとせっかくなのでBardに要約させましょう。ただ、残念ながら投稿時点で新AI Geminiは英語版のみですので、旧LLMを使っています。
Google は、マルチモーダル AI モデル「Gemini」を発表しました。Gemini は、テキスト、画像、音声、動画、コードなど、さまざまな種類の情報を一般化してシームレスに理解し、操作し、組み合わせることができます。
Gemini は、以下の点で既存の AI モデルを凌駕しています。テキスト、ビジョン、音声、コーディングなどのさまざまなタスクにおけるパフォーマンス
高度な推論性能。信頼性、拡張性、効率性の向上
Gemini は、Google のさまざまな製品やサービスに導入される予定です。Bard の機能強化
Google Pixel での導入
Google 検索、広告、Chrome、Duet AI などの主要製品やサービスでの利用
また、Gemini は開発者向けにも提供されます。Google AI Studio または Vertex AI の Gemini API を介して Gemini Pro にアクセス可能
Android 開発者は AICore を介して Gemini Nano を使用可能
Gemini は、AI の新たな時代を切り開く画期的なモデルです。創造性、知識、科学を向上させ、世界中の人々の生活と働き方を変革する可能性を秘めています。
具体的な例
Gemini は、以下の例のようなさまざまなタスクを実行することができます。テキストの要約、像の説明、音声の翻訳、コードの生成、質問への回答
Gemini は、複雑な推論も実行できます。例えば、数学や物理学の問題を解く、ビジネス戦略を立てる、創造的なアイデアを生み出す
Gemini は、信頼性と安全性を重視して開発されています。バイアスや有害性などの潜在的なリスクを軽減するための対策が講じられています。
Gemini は、今後もさらに改良が続けられます。例えば、計画とメモリの進歩、コンテキスト ウィンドウの増加
Gemini は、AI の未来を切り開く可能性を秘めた画期的なモデルです。今後の展開に注目が集まります。
推しは明らかに「マルチモーダル」です。こちらの動画が分かりやすかったので、文字を読むのが面倒な方はこちらをご覧ください。
個人的には、2:35あたりの「コップの下の紙ボールをみつけさせようとしてますね」というAIのコメントがぞくっとしました。
もちろんPR動画なので、これだけで公正な評価は難しいです。
上記要約にもあるように、「既存のAIを凌駕した」と勢いのある言葉を使っています。
一応裏付けもあり、最大のライバルGPT-4とのベンチマーク比較で上回っています。念のためこちらでも貼っておきます。(Ultraというのが最上位バージョン。英語版で解放されているのはその1つ下のバージョン)
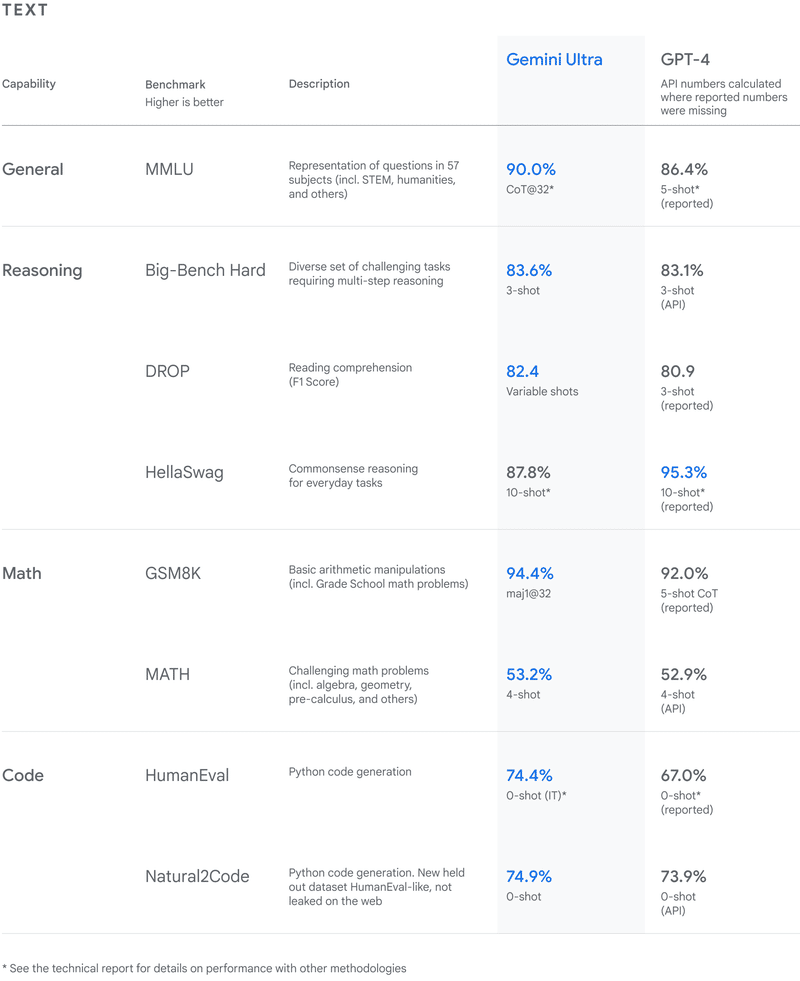
LLM(大規模言語モデル)を評価するのは、最近はパラメタ数だけではありません。
多様なタスクを遂行するMMMUと呼ばれるベンチマークもあり、下記で公開されています。

なじみがないモデル名もあると思いますが、とりあえずGPT-4がダントツであることが分かります。それすら凌駕した、というのはぜひ触ってみたいところです。
今回はじめにGeminiを動画で紹介したのは、Googleが買収したDeepMind CEOのデミス・ハサビスです。過去の関連記事(最新2つのみ)を貼っておきます。
単なるPR役だけでなく、従来からDeepMindが築き上げてきたアルゴリズムも活用されているかもしれません。
このあたりのテクニカルな原理は情報が出てきたら調べてみたいですが、まずはGemini日本語版を触れるのを楽しみに待っています。
この記事が気に入ったらサポートをしてみませんか?