
【JKI】034_Word_Scramble_02_真の乱数

【JKI_034】課題を再確認
前回で簡易版の単語並び替えまでは紹介しました。
ランダムに並べ替えは出来ていると思うのです。
【真のランダム化とは何か】
課題のヒントに気になる表現があります。
our more complex solution uses more than 15 nodes and 2 loops, as well as the Random Numbers Generator node, to create truly scrambled sentences.
Google翻訳だと
より複雑な解では,15以上のノードと2つのループ,そしてRandom Numbers Generatorノードを用いて,真の意味でのスクランブルされた文章を作成することができます.
真の意味でのスクランブルもしくはランダム化と聞いても何のことかわからなくて調べて下記の記事に行きつきました。
真乱数と疑似乱数
プログラミングの世界の中でいわゆる “乱数” として扱われることが多いのは擬似乱数です。疑似、と付くからには、これは実のところ乱数ではないと言えます。とは言え、擬似乱数を乱数でないと言ってしまうと話が終わってしまうので、疑似乱数を含む乱数を広義の乱数とします。この記事で扱うのは広義の乱数です。逆に、狭義の乱数、本物の乱数は真乱数と言います。
より詳しくはリンク先をご覧ください。エントロピーまで言及されています。知らないことばかりでした。
【Shuffleノードは疑似なのか真なのか】
一方で、Shuffleノードの日本語化されたディスクリプションを引用してみます。
入力テーブルの行をランダムな順序になるようにシャッフルします。
Dialog Options
Seed
乱数生成器のシードを入力します。
シードを入力すると、ノードは同じ入力データを常に同じようにシャッフルします(ノードをリセットして実行した場合など)。
このオプションを無効にすると、常に異なるシードを使用することができ、本当のランダム性を得ることができます。
うーん、私もオプションは無効にしたのでこれで本当のランダム性が得られているのか、それとも疑似乱数なのか…わからん!
先ほどの記事にはさらにこんな記述があってより分からなくなっています。
疑似乱数を初期化するための値を種(シード)と呼びますが、シードの扱いによっては性質の良い疑似乱数アルゴリズムでもその能力を十全に発揮できなくなってしまうことがあるので注意が必要です。
基本的には、シードは初期化する擬似乱数の内部状態と同じサイズであるべきで、その値は真乱数によって生成すべきです。
そこでシードに乱数を入れてみたらより真の乱数に近づくのかなと下記のworkflowを作ってみました。

【解答編_02】
十二分に悩んだのちに諦めの境地で上記のWFを作成したので、紹介はします。
公式解答で真のランダム化を勉強するつもりです。
【Chunk Loop Start】
前回は簡易版なので4つの文をまとめてShuffleするという仕様でしたが、やはり各文それぞれで処理すべきと考えたので一行ずつのループ処理にします。

設定:

結果:
4つの文を入力とし、4回目の最終ループが回ったところではRow3の行がループにかかっています。
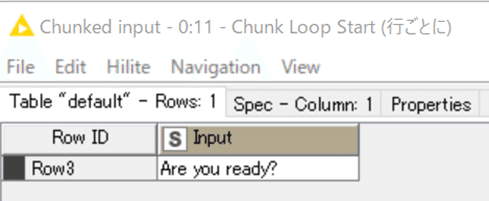
以下も最終ループで結果を例示します。
【単語に切り分けて縦横変換】

ここは前回と同じ設定なので割愛し、結果だけ。
結果:

【乱数をシードとしたシャッフル】
Ramdom Numbers Generatorは初めて使いました。
日本語化されたノードディスクリプションから引用します。

設定は以下の通りとしました。

先述の「擬似乱数の内部状態と同じサイズ」が不明なので、0から10万までのどれかにしておきました。どうやってそのサイズを調べられるのかな。
ここにも結局Ramdom Seedを求められるのですが、デフォルトでは-1であり、おそらくこの乱数発生器に関してのシードは設定していない状態にあると推測します。
結果:(あくまで一例です)

ここで発生させた数を変数としてShuffleノードのシードにしたのです。
設定:



結果:

【横並びに直して単語を繋ぐ】

この処理も前回と同様なので、結果だけ。

今回は各行ごとに処理しているので、無駄な半角スペースが含まれることはありません。今回のようにループ処理した方がわかりやすいですね。
【元データと並べて表示】

今回はInputとOutputを比べやすいように横並びにデータテーブルにしました。
設定:



結果:

以上です。
WFは既にKNIME Hubに上げてます。
おまけ:
【ネガティブサンプリングの難しさを考える】
上記の場合、1行目の結果のように、シャッフルしたけど、元と同じ並びになることもありました。ランダムだから当然のことですね。
10万回ループさせてみた集計結果です。
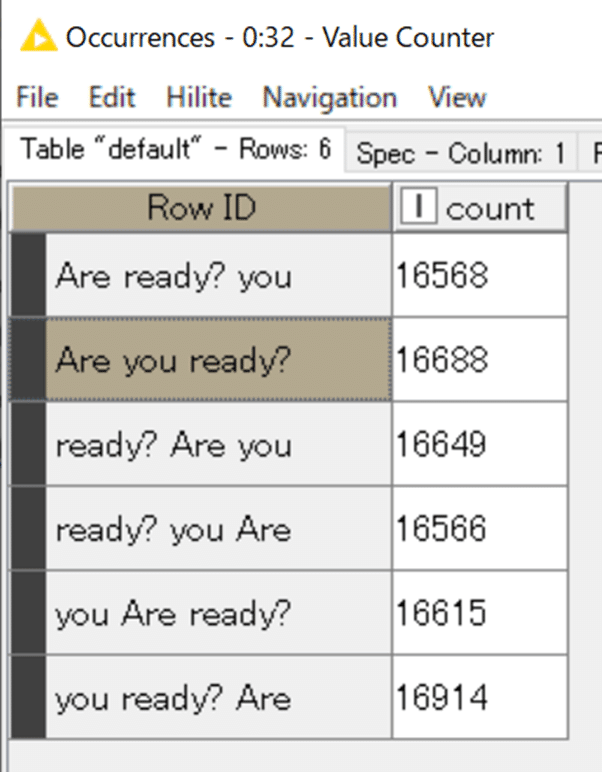
ちなみに600万回ループしたら次の日までかかって集計時にKNIMEが落ちました…落ちるなら早めに落ちて欲しかった。何やってんだ自分ながら。
ネガティブサンプリングの目的として、
モデルを学習するためには、間違った文脈で使われた単語のデータセットも作成する必要があります。
とのことですから、出力結果を何らかの基準で絞り込み、より真にネガティブな文字列だけに絞り込めるよう、ひと工夫必要になりますね。
さらにいえば文頭の大文字や文末の記号を考えないで、単に単語の並び順だけをみるなら
are you ready
を並び替えて
you are ready
でも間違ってないでしょう。
あるいは倒置表現もあるだろうし、形容詞が複数ある場合など並び順も変わっても意味が通じないとも限りません。
「間違った文脈」をシステムでどう判定させるのか、ここもまた一研究なのかなと思いました。
今回の課題のおかげで初めてこんな難しさもあるんだなと納得しました。
面白いお題をありがとうございました。
記事を読んでいただきありがとうございます。 先人の智慧をお借りしつつ、みなさんに役立つ情報が届けられたらと願っています。 もしサポートいただけるなら、そのお金はKNIMEの無料勉強会の開催資金に充てようと思います。