【編集時間30%削減】PIVOTを支えるOpen AIを活用した自動文字起こし

ビジネス映像メディア「PIVOT」のプロダクトマネジメントチームでインターンをしている鏑木です。
弊社では、「コンテンツの力で、経済と人を動かす。」をVISIONに、学びある映像コンテンツを youtube、Web アプリ、ネイティブアプリ(Android・iOS)各種プラットフォームで配信しております。
さて、映像コンテンツ作成にあたって「編集」は避けて通れないですが、かなりの工数がかかります。特に手間がかかるのがテロップ作成です。
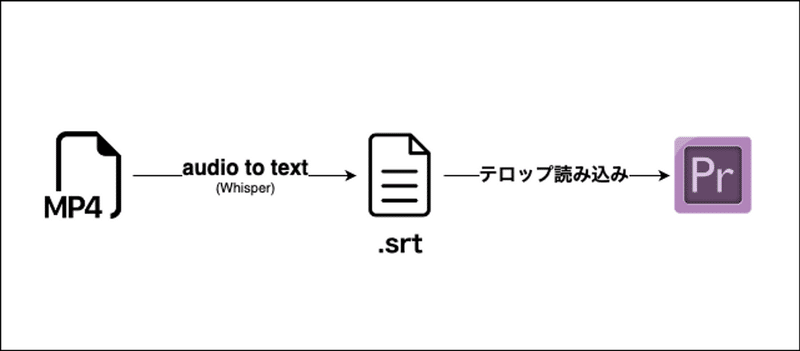
Whisper を用いて映像データからテキストデータの自動生成を行いました。さらに、テキストデータをpremier pro 上で取り込める srt 形式のファイルとして出力するシステムをGCP上に構築し、編集チームの工数を削減した取り組みについて紹介します。
PIVOTについて
開発背景
映像編集においてテロップ入れはかなり手間のかかる作業です。
premier proでは文字起こしとテロップ入れを自動化する機能が提供されているのですが、精度があまり高くないです。精度が良くないと、テキストを修正する工数が大きいため、自動化の恩恵を最大限受けられません。
精度が芳しくないのであれば Whisper を使うことで文字起こしの精度が改善できないかと考えて文字起こしシステムを作ってみました。
さらに文字起こしされたデータは srt 形式で出力することで、premier pro で直接映像上に取り込むことが可能になるよう処理を加えました。
Whisperとは
Open AI が 2022年9月21日に公開した汎用音声認識モデルです。
Web上から収集された大規模テキストデータを対象として、68万時間に及ぶ学習を通じて多言語に対応しており、音声書き起こしや翻訳などのさまざまなタスクを行うことが可能です。
学習済みのモデルは github にてMITライセンスで公開されています。
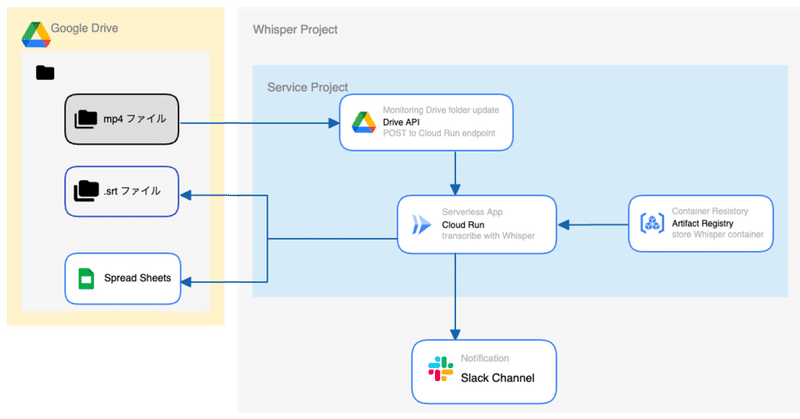
プロジェクトの概要
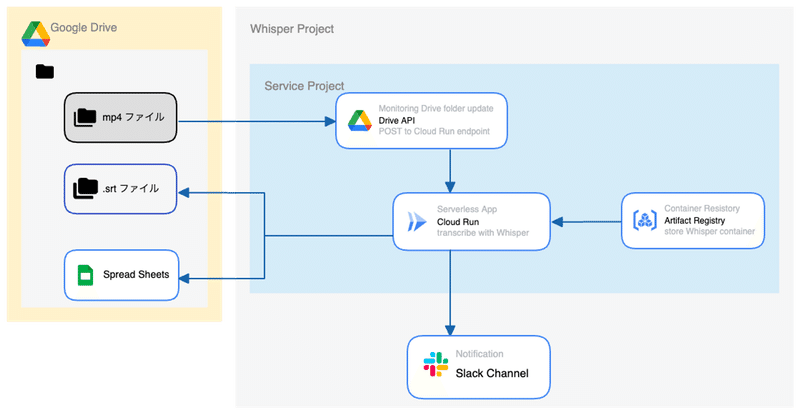
Whisperモデルを Google Cloud 上で動作させて、映像ファイル(mp4)をアップロードすると自動でテロップファイルが作成されるシステムを構築しました。
処理の流れは以下です。
文字起こししたいファイルを google drive にアップロードする
drive api を使ってファイルアップロードを検知し、Cloud Run エンドポイントにリクエスト送信
Cloud Run上で Whisper コンテナを立ち上げて対象ファイルを処理
文字起こしされたデータを srt 形式に整形
google drive に テロップファイル(.srt)と スプレッドシート を出力
処理が完了したことを slack チャンネルに通知
1. ファイルアップロード
映像チームの社員にとっての使いやすさを重視して、 google drive にファイルアップロードする方法を採用しました。
2. Drive APIによるアップロード検知
google drive にアップロードされたファイルは drive api を用いて検知します。
これにより、ファイルのアップロードを drive api が自動検知して Cloud Run コンテナに向けてPOSTリクエストを送信します。POSTリクエストを受け取ってWhisperによる文字起こし処理が自動実行される仕組みです。
drive api の実装に関しては下記記事を参考にさせていただきました。
3. Cloud Run + Whisper
Whisper は Cloud Run インフラ上でサーバーレスに構築しています。
本プロジェクトにおいて検証の初期段階では、GCE を使ってクラウド上にWebアプリケーションとしてデプロイをしていました。しかしながら、
常時インスタンスの立ち上げに伴うランニングコスト
を考慮して Cloud Run に変更しました。
4. premier pro で取り込み可能なsrt形式に変換
premier pro でテロップ情報として読み込むために、文字起こしの出力を srt 形式に編集します。
これは python の srt ライブラリを使って簡単に実装することが可能です。
5. drive に出力ファイルを作成
drive api を用いて出力ファイルを google drive 上に作成します。
今回はテロップファイル(.srt)と文字起こし結果のスプレッドシートの計2ファイルを出力することとしました。
(実際のファイルイメージは本記事の後半に記載しています)
6. slack に終了通知
slack api を用いて、drive 上に出力ファイルが作成されると特定のチャンネルに通知が来るようにしています。
これで編集者は自由な時間にファイルをアップロードしておくだけで勝手にファイルが作成されます。終了すれば通知がくるので完全放置で良い訳です。
(実際のファイルイメージは本記事の後半に記載しています)
パイプラインの実装
以上の手順をまとめた実装ファイルが以下です。
あまりクリーンなコードでは無いですがご容赦ください🙏
実装
import io
import json
import os
import time
from datetime import datetime as dt
from datetime import timedelta
import pandas as pd
import requests
import srt
import whisper
from apiclient.discovery import build
from flask import Flask, request
from googleapiclient.http import MediaFileUpload, MediaIoBaseDownload
from oauth2client.service_account import ServiceAccountCredentials
from whisper.utils import format_timestamp
class WhisperTranscription:
def __init__(self) -> None:
self.drive_service = self.authenticate()
self.model = whisper.load_model('tiny')
self.cache_path = './tmp'
self.file_path = ''
self.csv_path = ''
self.srt_path = ''
def _format_text(self, text: str) -> str:
return text.replace('、', ' ').replace('。', '')
def _parse_audio_segment(self, whisper_transcribe_result: dict) -> pd.DataFrame:
tmp = []
for segment in whisper_transcribe_result['segments']:
tmp.append([
format_timestamp(segment['start'], always_include_hours=True),
format_timestamp(segment['end'], always_include_hours=True),
self._format_text(segment['text'])
])
return pd.DataFrame(tmp, columns=['start', 'end', 'text'])
def authenticate(self) -> None:
scope = ['https://www.googleapis.com/auth/drive']
key = 'IAM_USER_KEY.json'
try:
credentials = ServiceAccountCredentials.from_json_keyfile_name(key, scopes=scope)
drive_service = build("drive", "v3", credentials=credentials, cache_discovery=False)
return drive_service
except Exception as e:
serverlog(f'Failed to authenticate: {str(e)}')
os.kill(os.getpid(), 9) # Terminate the process
def fetch_updated_page_token(self) -> str:
try:
response = self.drive_service.changes().getStartPageToken().execute()
saved_start_page_token = response.get('startPageToken')
updated_page_token = str(int(saved_start_page_token) - 1)
return updated_page_token
except Exception as e:
serverlog(f'Failed to fetch updated page token: {str(e)}')
os.kill(os.getpid(), 9) # Terminate the process
def fetch_updated_file_info(self, changed_page: str) -> dict:
try:
response = self.drive_service.changes().list(pageToken=changed_page, spaces='drive').execute()
updated_file_info = response.get('changes')[0]
return updated_file_info
except Exception as e:
serverlog(f'Failed to fetch updated file info: {str(e)}')
os.kill(os.getpid(), 9) # Terminate the process
def _parse_updated_file_info(self, updated_file_info: dict) -> dict:
file_id = updated_file_info['fileId']
file_name = updated_file_info['file']['name']
file_bare_name, extension = os.path.splitext(file_name)
return file_id, file_name, file_bare_name, extension
def check_file_extention(self, extension: str):
if extension not in ['.wav', '.mp3', '.mp4', '.m4a']:
serverlog(f'Invalid file extension: {extension}')
os.kill(os.getpid(), 9) # Terminate the process
def check_file_processed(self, file_name: str):
if file_name in os.listdir(self.cache_path):
serverlog(f'File already processed: {file_name}')
os.kill(os.getpid(), 9)
def fetch_updated_parent_id(self, file_id: str) -> str:
try:
file = self.drive_service.files().get(fileId=file_id, fields='parents').execute()
parent_id = file['parents'][0]
return parent_id
except Exception as e:
serverlog(f'Failed to fetch updated parent ID: {str(e)}')
os.kill(os.getpid(), 9) # Terminate the process
def download_updated_file(self, file_id: str, file_name: str) -> None:
try:
request = self.drive_service.files().get_media(fileId=file_id)
self.file_path = f'{self.cache_path}/{file_name}'
fh = io.FileIO(self.file_path, 'wb')
downloader = MediaIoBaseDownload(fh, request)
done = False
while done is False:
status, done = downloader.next_chunk()
except Exception as e:
serverlog(f'Failed to download updated file: {str(e)}')
os.kill(os.getpid(), 9) # Terminate the process
def transcribe_with_whisper(self) -> pd.DataFrame:
try:
start_time = time.time()
result = self.model.transcribe(self.file_path, language='ja', verbose=False)
transcribe_time = round(time.time() - start_time, 2)
df_transcription = self._parse_audio_segment(result)
return df_transcription
except Exception as e:
serverlog(f'Failed to transcribe with Whisper: {str(e)}')
os.kill(os.getpid(), 9) # Terminate the process
def save_transcription_csv(self, df_transcription: pd.DataFrame, file_bare_name: str) -> None:
try:
self.csv_path = f'{self.cache_path}/{file_bare_name}.csv'
df_transcription.to_csv(self.csv_path, index=False)
except Exception as e:
serverlog(f'Failed to save transcription as CSV: {str(e)}')
os.kill(os.getpid(), 9) # Terminate the process
def save_transcription_srt(self, df_transcription: pd.DataFrame, file_bare_name: str) -> None:
try:
self.srt_path = f'{self.cache_path}/{file_bare_name}.srt'
subs = []
transcriptions = df_transcription.to_dict(orient="records")
for idx, data in enumerate(transcriptions):
start = dt.strptime(data['start'], '%H:%M:%S.%f')
end = dt.strptime(data['end'], '%H:%M:%S.%f')
sub = srt.Subtitle(
index=idx + 1,
start=timedelta(
hours=start.hour,
minutes=start.minute,
seconds=start.second,
microseconds=start.microsecond
),
end=timedelta(
hours=end.hour,
minutes=end.minute,
seconds=end.second,
microseconds=end.microsecond
),
content=data['text']
)
subs.append(sub)
with open(self.srt_path, mode="w", encoding="utf-8") as f:
f.write(srt.compose(subs))
except Exception as e:
serverlog(f'Failed to save transcription as SRT: {str(e)}')
os.kill(os.getpid(), 9) # Terminate the process
def upload_transcription_csv(self, file_bare_name: str, parent_id: str) -> dict:
try:
media = MediaFileUpload(self.csv_path, mimetype='text/csv')
file_metadata = {
'name': file_bare_name,
'mimeType': 'application/vnd.google-apps.spreadsheet',
'parents': [parent_id],
}
response = self.drive_service.files().create(body=file_metadata, media_body=media, fields='id').execute()
return response
except Exception as e:
serverlog(f'Failed to upload transcription CSV: {str(e)}')
os.kill(os.getpid(), 9) # Terminate the process
def upload_transcription_srt(self, file_bare_name: str, parent_id: str) -> dict:
try:
media = MediaFileUpload(self.srt_path, mimetype='text/plain')
file_metadata = {
'name': f'{file_bare_name}.srt',
'mimeType': 'text/plain',
'parents': [parent_id],
}
response = self.drive_service.files().create(body=file_metadata, media_body=media, fields='id').execute()
return response
except Exception as e:
serverlog(f'Failed to upload transcription SRT: {str(e)}')
os.kill(os.getpid(), 9) # Terminate the process
def delete_cache(self) -> None:
try:
os.remove(self.file_path)
os.remove(self.csv_path)
os.remove(self.srt_path)
except Exception as e:
serverlog(f'Failed to delete cache files: {str(e)}')
os.kill(os.getpid(), 9) # Terminate the process
def pipeline(self) -> None:
updated_page_token = self.fetch_updated_page_token()
updated_file_info = self.fetch_updated_file_info(updated_page_token)
file_id, file_name, file_bare_name, extention = self._parse_updated_file_info(updated_file_info)
self.check_file_extention(extention)
self.check_file_processed(file_name)
parent_id = self.fetch_updated_parent_id(file_id)
self.download_updated_file(file_id, file_name)
df_transcription = self.transcribe_with_whisper()
self.save_transcription_csv(df_transcription, file_bare_name)
self.save_transcription_srt(df_transcription, file_bare_name)
csv_upload_response = self.upload_transcription_csv(file_bare_name, parent_id)
srt_upload_response = self.upload_transcription_srt(file_bare_name, parent_id)
self.delete_cache()
return file_bare_name, f'{https://drive.google.com/drive/folders/{parent_id}}'
def serverlog(message):
PROJECT = 'GCP_PROJECT_NAME'
global_log_fields = {}
request_is_defined = "request" in globals() or "request" in locals()
if request_is_defined and request:
trace_header = request.headers.get("X-Cloud-Trace-Context")
if trace_header and PROJECT:
trace = trace_header.split("/")
global_log_fields[
"logging.googleapis.com/trace"
] = f"projects/{PROJECT}/traces/{trace[0]}"
entry = dict(
severity="NOTICE",
message=message,
component="arbitrary-property",
**global_log_fields,
)
print(json.dumps(entry))
def post2slack(file_bare_name, path):
WEB_HOOK_URL = 'SLACK_CHANNEL_ENDPOINT'
try:
requests.post(WEB_HOOK_URL, data=json.dumps({
'text' : f'Whisper pipeline finished!! \\n {file_bare_name} \\n {path}',
}))
return 'ok'
except:
requests.post(WEB_HOOK_URL, data=json.dumps({
'text' : 'Unexpected Error Occured',
}))
return 'error'
app = Flask(__name__)
@app.route('/', methods=["GET", "POST"])
def main():
serverlog('logging test: whisper pipeline start')
wt = WhisperTranscription()
file_bare_name, path = wt.pipeline()
post2slack(file_bare_name, path)
return path
if __name__ == "__main__":
app.run(debug=True,
host='0.0.0.0',
port=int(os.environ.get('PORT', 8080)))
Dockerfile
Artifact Registory に下記Dockerfileをビルドして保存しています
FROM python:3.9-slim
ENV APP_HOME /app
WORKDIR $APP_HOME
COPY . .
RUN apt-get update && apt-get install -y \\
build-essential \\
gcc \\
git \\
ffmpeg \\
&& rm -rf /var/lib/apt/lists/*
RUN pip install --upgrade pip \\
&& pip install --no-cache-dir -r requirements.txt \\
&& pip install git+https://github.com/openai/whisper.git
CMD exec gunicorn --bind :$PORT --workers 1 --threads 8 --timeout 3600 app:app
実際の使用感
mp4アップロードからsrt出力まで
実際の使用感を確認します
1. ファイルをアップロード
2. 処理が終了するとファイルが出力されます
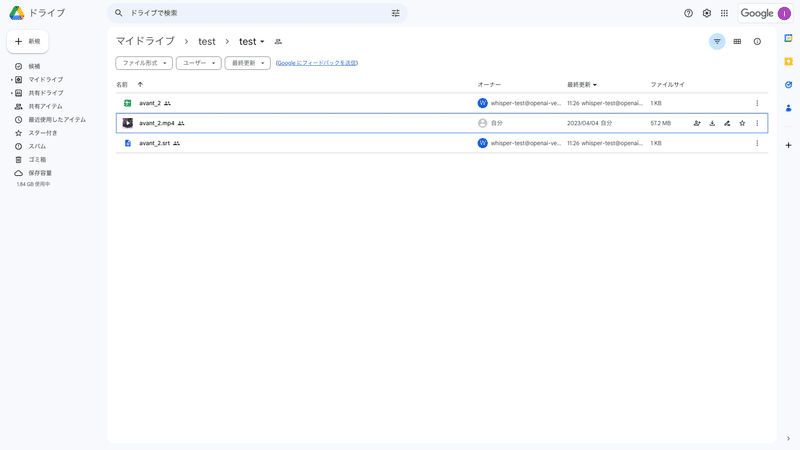
3. slack に通知が来て処理が終了します

文字起こし精度
こちらがテスト用の素材で、実際に文字起こししてみたファイルです。
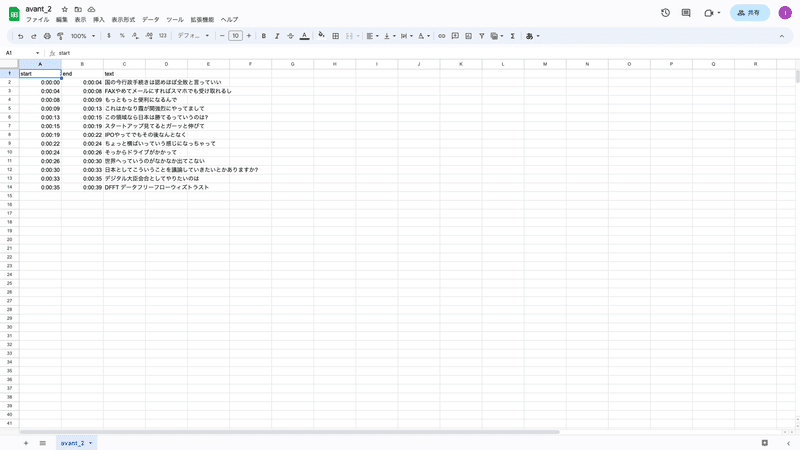
英語が入り混じった表現や固有名詞も問題なく文字起こしされていますね。
まとめ
Whisper vs premier pro
Whisper を使った自動文字起こしシステムを社内向けに公開したところ、想像以上に編集チームから好評の声をもらいました。
特に、精度の面では premier pro に内蔵されている機能よりも、Whisperの方が優れていて修正にかかる手間が削減できたようです。
一方で、テロップにそのまま用いるには一文が長すぎることがあるようで、ここは技術的課題と言えます。premier pro ではテロップに用いるテキストの最大長を指定できる機能があるため、この点はpremierに軍配が上がります。
premier と Whisper の長短をまとめると以下です。
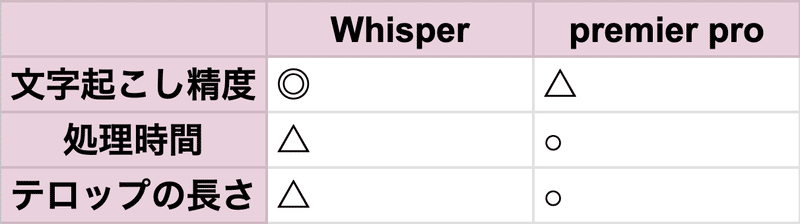
今後はWhisperをベースに、テロップの長さもコントロールできる処理を追加開発していきたいですね。
一方で技術的課題もあります、、
Drive API による通知チャネルの権限には最長1週間の制約がある
Drive API によって対象ファイルの変更を監視して、Cloud Runエンドポイントに向けてPOSTリクエストを送っています。
Drive API からエンドポイントへPush通知を送信するために必要な権限は最長で1週間となっているため、一週間ごとに権限を更新する必要があります。
Cloud Run タイムアウトへの対応
Cloud Run のリクエストタイムアウトは標準で5分、最長で60分となっています。そのため2時間を超えるような長い映像素材に対して処理を行う場合にはタイムアウトのリスクがあります。
ファイルをチャンク化して処理を軽量化するなどの対応が考えられますが、現在は対応できていないので、後々改善していく予定です。
PIVOT 各種サービス
Youtube
Web
iOS
Android
この記事が気に入ったらサポートをしてみませんか?