
WinActorでChrome操作

こんばんは、かーでぃです。
なんか今さら書くような記事でもないのですが、RPACommunityでWinActorトーク支部の主催をさせてもらっているのに、全然WinActorを触れてなかったので、ゼロから改めて勉強をしはじめました。
ということで、すっごい初歩的なところになりますが、自分の忘備録的に記事を上げていこうと思います。
シナリオ概要
とあるサイトを開き、コード検索した結果からHTML内部にある”ある番号”を取得。URLにその番号を連結させたURLで、求めたいPDFのリンクを取得する、というものです。
Chromeを開く
ページを開く(併せて検索する)
検索結果から番号を取得
PDFのURLを作成
シナリオ全体像
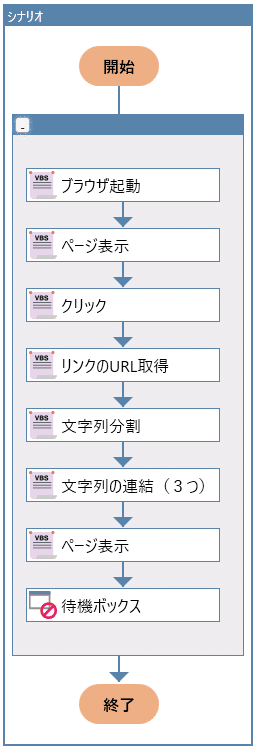
1番目「ブラウザ起動」
WinActorでブラウザ操作をするのであれば、こちらから起動させましょう。こちらから起動することで、ブラウザを識別できるようになるので、安定性が増します(画像認識等でやる方法もありますが、安定性に欠けます)。
ちなみに、ブラウザ起動でエラーになる場合は、WebDriverとブラウザのバージョン不一致の可能性が高いです。
この記事の末尾に、参考記事のURLがありますので、そちらを参考にバージョンを一致させましょう。
ブラウザ名のところ、直接名前指定にしてるので、思わず"(ダブルクォーテーション)で囲みたくなりますが、WinActorでは不要ですね。
以後、ブラウザ操作では、ここで指定したブラウザ名を使いまわします。
※ので、本来は変数に格納しておいた方がベターですね。

3番目の「クリック」
初回開いた際に、利用許諾のページが開きますので、自動的に「承諾」ボタンを押すようにしています。
「クリック」のプロパティを開いて、「ブラウザ」をクリックすると、先に指定してあるページが開きます。その後、「選択」ボタンで対象としたいボタンを選んであげれば「XPath」に自動的に値が入りました。
最初、ウィンドウ識別名を指定していたのですが、とりあえず起動させたのブラウザ1つだけでしたし、タブも開いていないので、空欄にしておきました。

4番目の「リンクのURL取得」
こちらはボタンに設定してあるURLを取得するものです。
やり方は👆とほぼ同じですね。
取得できると、「取得結果」で指定した変数に値が格納されます。

5番目「文字列の分割」、6番目「文字列の結合」
取得したURLのうち、必要な項目は末尾の数字だけです。
URLなので「/」で区切られていますので、文字列分割で分割し、目的の値を取得しています。
分割した結果のうち、下の例では5番目(スタートは0)の値を、変数「strPdfNum」に、分割した総数をintUrlPdfLengthに格納します。
例)
urlPdf = "https://www.hogehoge.com/view/detail/1234"
インデックス0 : https
インデックス1 :
インデックス2 : www.hogehoge.com
インデックス3 : view
インデックス4 : detail
インデックス5 : 1234
strPdfNum = 1234
intUrlPdfLength = 5

7番目の「ページの表示」
先ほど得た"strPdfNum"を使って、6番目の「文字列結合(3つ)」でURLを作成し、"strPdfUrl"に格納しています。
その"strPdfUrl"をつかってページを表示させています。

以上で、ページの検索結果から番号を取得し、その番号を使って別のページを開く処理が完成しました。
WebDriverについて
WinActorでChrome操作するのは初めて?
そんなことはないかもしれないけど、WebDriverのバージョンが合わずに全然動いてくれなくて、最初で心が折れそうになった(笑)
心が折れそうになったら、下記のCOBOTPIAの記事が参考になりました。
ということで、ぼちぼちとWinActor記事も更新していこうと思いますので、よろしくお願いいたします!
この記事が気に入ったらサポートをしてみませんか?