
【StableDiffusion】WebUI上で使えるLoRA学習ツールsd-webui-traintrainが便利すぎた件について【コピー機学習法】

■記事の対象ユーザ
1.LoRAを自作したことがある、または自作したい気持ちがある
2.LoRA作成ではKohya's_GUIのお世話になっている
3.コピー機学習法の作成手順を面倒に感じている


■ようするに?
・学習用に別環境を用意しなくてもWebUIだけ学習ができる
・コピー機学習法でのLoRA作成が1STEPで済む
・いくつもキューイングしておける
こんな感じの差分LoRAが1回の設定で作ることができるよ!

0.はじめに

Kohya's GUIでコピー機学習法で差分LoRAを作る時、中間ファイルが色々残っていて後から苦労した経験とかありませんか?
私はどうも整理が苦手で、作業フォルダの中がtest1とかtest2だとかの謎LoRAまみれになっている事がよくあります。
今回紹介する2024年1月にリリースされたsd-webui-traintrain(以下traintrain)はStableDiffusion Web-UI上で動作する学習用のツールです。
traintrainには通常のLoRAを作成する機能の他に、簡単にコピー機学習法でLoRAが作れるモードがあり、従来の様にコピー機LoRA①とコピー機LoRA②を作ってマージするという手間が必要ありません。
中間ファイルを作らずとも目的の差分LoRAが作れるのには触ってから驚かされました。

補足:コピー機学習 is 何?

そうね、でも私が説明するより月須和さん(@nana_tsukisuwa)のnote記事がめちゃくちゃ腑に落ちる内容だったからそっちを案内しておくね

私から一言だけ説明しておくと「目の大きさ」とか「髪の長さ」とかを適用度に応じてスライダー式に出力を調整できるLoRAを作るのに使われている手法だよ。差分学習法って呼ばれる場合もあるけど同じものだと思って貰えれば問題ないと思うんよ。

1.インストール
ここは他のWebUI拡張と変わらないからサラっと流しておくね。
まず、公式リポジトリからURLを取得して
WebUIの拡張機能からインストール
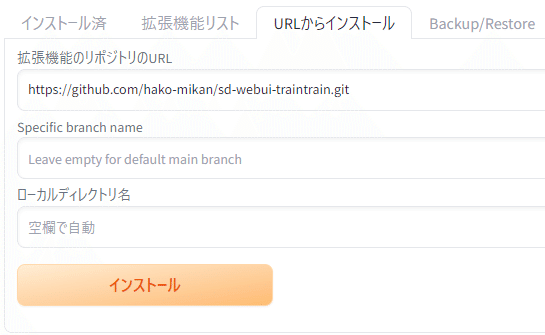
インストール後、UIを再読み込みすると「TrainTrain」タブが表示されるよ

うん、いつも通りだね
2.設定
ここではSD1.5用のLoRAを1つ作ってみた時の設定について書いていくよ。
2-1.プリセットの選択
リポジトリの「差分」モードの説明にも「Difference_Use2ndPass」を使ってねと書いてあるので、選択して右側の左下矢印ボタンを押すと、プリセットの内容が各項目に反映されるよ。

(ちなみに一番上の「差分」プリセットを選ぶと何故か「iLECO」プリセットがロードされました)

2-2.モード
ここは作りたいLoRAの種類によって変更するよ。
今回はプリセットで「Difference_Use2ndPass」を選んだのでここは「差分」が指定されているはず。
ここで「iLECO」を選んだ場合は画面下の方にプロンプト欄が、
「差分」を選んだ場合は画像アップロード用のUIがそれぞれ表示されます。


補足:iLECOについて
教師画像を必要としない追加学習方法で、モデルがプロンプトベースで出力した画像を教師画像にして学習する手法だよ。

iLECOについてはtraintrainの作者さんがLECOの説明記事を書いてくれていて、そちらが分かりやすいよ。

ちなみにiLECOの「i」はインスタントの「i」で、LECOで計算に使っているプロンプトの一部を省略して数十倍に高速になったから「インスタント」なんだって。


2-3.モデル / VAE
LoRAを作成するのに使うベースモデルとVAEを選択するよ。
VAEは各モデル推奨のものを設定しておくよ。

2-4.必須パラメータ
プリセット通りでOK!と言いたいところだけど、試しに作って見たら
学習不足な感があったから少しだけ調整していくね。

network_rank / network_alpha:
デフォルトの16で試して出来たLoRAを適用したら、変化量が足りなかったので小さくしてます。

train iterations:
学習回数。Kohya's_GUIだとエポック数と画像フォルダの繰返し数とかで調整する必要があったけど、traintrainはここで何STEP学習させたいか入力すれば、エポック数とかをよしなにしてくれます。(たすかる)
最初はデフォルト500で試して変化量が足りなかったから1,000に増やしてます。公式リポジトリにも「差分」の場合、推奨は500~1,000って書いてあるしね。

train batch size:
バッチ数。増やすと同時に学習する画像数が増えるので学習時間が早くなる+使用するVRAMも増える。
注意点として例えば1→2に増やすと単純に2倍の速度で学習するようなものではなくて、同時に2枚学習するから1枚の画像からLoRAが学習する特徴が減るので結局その分学習回数を増やさないといけないみたい。
train learning rate:
学習率。LoRAの場合大体1e-4~1e-3(=0.0001~0.001)くらいが適当と聞く。
公式リポジトリの説明や先達の情報だとコピー機LoRAの場合1e-3程度で十分とあるのでここは1e-3(=0.001)に変更。

save lora name:
保存するLoRAの名前。メキシコに吹く赤い熱風のことはもういい。
補足情報① network type:
「lierla」って何さ?ってなるけどlierlaが普通のLoRAのことらしいです。
補足情報② train optimizer:
オプティマイザ。私はよくAdamW(8bit)を使ってたるんですけど、公式リポジトリをみると差分モードではうまく動作しない。と注意書きがあるので通常のAdamWにしてます。lionとかprodigyでも問題ないとは思うけどね!

補足情報③ use gradient checkpointing:
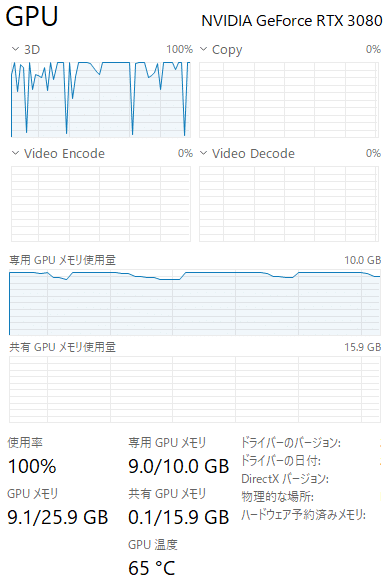
gradient checkpointを使うと20%ほど学習速度が遅くなる代わりにVRAM使用量が減るというもの。学習中のVRAMが100%に張り付くようならチェックを入れましょう。

ちなみにこれは私の環境でギリギリ耐えられている時の例
補足情報④ network blocks:
TextEncoderとU-NETの学習ブロックの指定。
TextEncoder(=BASE)を学習させると画風への影響が大きくなる。
U-NETもBlockに応じてどの辺に効くかが分かれているので、例えば顔の部分だけ、という場合なら顔に影響すると言われているOUT3~5だけにチェック入れるとかしてもいいかも。

2-5.任意パラメータ
今回はプリセットのまま変更はないので省略するね。

2-6.2nd pass
モード「差分」を選ぶと表示される項目。
コピー機学習法で言うところの元のコピー機LoRAを作るのが1st Pass、変化後のコピー機LoRAを作るのが2nd Passという感じ。
network_dimとnetwork_alpha以外は1st Passと同じにしたいので
「Copy settings from 1st pass」ボタンを押して設定をコピーするよ。

network_dimは1st Pass目より小さく指定すると構図や画風に影響を及ぼさないようにできるって公式リポジトリの説明にもあるから今回は4に指定するよ。

2-7.画像の設定
「差分」モードに指定していると、画面最下部に画像をアップロードできるUIが表示されるよ。LoRAに学ばせたい差分を求めるための「変化前の画像」と「変化後の画像」をそれぞれ設定するよ。

EyeCollectionっていう有名な目の差分LoRAを作られている十条さん(@JujoHotaru)さん曰く
コピー機LoRA学習のポイントのひとつとして、なるべく元コピー機と学習画像の要素を対極にする、というのを心がけ、実際効果が出ています。
— 十条 蛍 @AIイラスト (@JujoHotaru) August 29, 2023
説明が難しいのですが、例えば吊り目を作る場合、一般的なモデルが出す普通の目つきではなく思いっきり丸いタレ目の絵をコピー機にして使う、など。
(続く)
コピー機といっても実際出してみると多少ノイズが乗ったり数ピクセルずれたりして、これはLatent空間では1/8になっているからと思いますが、実際にはどういうわけか学習画像の1ピクセルのズレでも効果に大きく作用する事象を多数観測しています。
— 十条 蛍 @AIイラスト (@JujoHotaru) August 29, 2023
きちんとピクセル単位で処理してくれている…?
ということで
1.使用する画像は変化点以外はピクセルレベルで一致させる
2.変化点は大げさになるように作る
の2点を意識した画像を用意して設定するようにしているよ。

3.学習の実行
設定を終えたら画面上部にあるボタンから学習を開始するわけだけど
traintrainで嬉しいのはキューイング機能があるところ。

「Add to Queue」を選択すると、処理待ちとして登録することができて
複数の設定をキューイングしておくと、自分が寝ている間や仕事に行っている間にLoRAの学習を続けて処理してくれるよ。
キューイングしたあと「Start Training」押さないと学習が始まらないから注意してね。
GPUの性能にもよるけど、うちのRTX3080なら数分~十数分くらいで完成するよ。
4.結果の確認

以下のプロンプトを与えてLoRAの適用度だけを変更していくよ。
「open mouth」は入れてないから口が開いている=LoRAの効果ってことで
masterpiace,1girl,solo,black hair,red eyes,face_focus,サンプル1:「差分」モードのデフォルト設定で学習させた場合
「記事書く前に試して弱かった」って書いてたLoRAです。

サンプル2:記事通りの設定で学習させた場合
今回の記事の設定で作成したLoRAです。

これだと分からないので、サンプル2を1.0~2.0で小刻みに適用してみると


じゃあ試しにプロンプトに「side view」とか加えて横顔も描画させてみるよ

ドイツ軍人は狼狽えない。こんなこともあろうかとレンジの中に別角度の教師画像から作ったサンプルLoRA3の完成品があるので、そちらで試すと・・・



5.おわりに
実は今回の記事を書く前、従来のKohya's GUIで同じように「あ」の口の差分LoRAを作ってたんだけど、traintrainだと同じ機能を持った差分LoRAがお手軽に作れちゃったし、キューイング機能と併せるとより効率的にLoRAが作れそうな予感がするよ。

偉い人が言ってたけど「類似した機能を持つLoRAをマージすると安定感が増す」らしいので、今回のSample2とSample3あたりをマージすればもっといい感じに効く差分LoRAが作れると思うのよね。
LoRAって試せば試すほど「なんもわからん」ってなるから奥が深いんですよね・・・。あーだこーだ試行した知見が増えると皆が幸せになれそうなので沼にハマろ。大丈夫だよ!!痛いのは最初だけだから!!!!

おまけ:トラブルシューティング
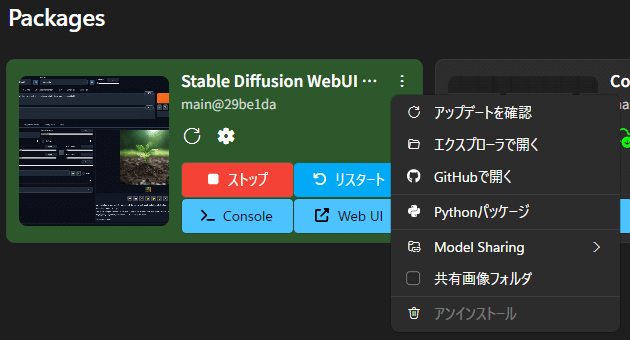
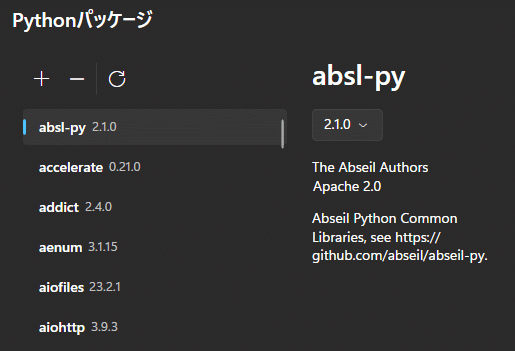
bitsandbytesが無いと怒られた場合
さぁ!いざ学習開始!ってタイミングでコンソールにエラーがでたよ。
Pythonのパッケージが環境にインストールされていないことが原因なんだけどStabilityMatrixの場合は次の手順でインストールできるよ。

この記事が気に入ったらサポートをしてみませんか?