Pythonで大量のテキストの類似度チェックを行うメモ

はじめに
最近は大規模言語モデルのコーパスづくりに四苦八苦しています。
収集したテキストには、多くの重複データが含まれるためそれらを削除する作業が大切です。
重複削除はCなどのコンパイル言語で高速にやるのが常套手段なのですが、今回はあえて、pythonライブラリで実行してみました。
関連
例えばこちら
テキスト
webから収集した、7万件ほどのテキストを使います。
Hojicharに入っている類似度判定アルゴリズム
hojicharは、テキストを簡便にクリーニングするための便利なライブラリです。
ただし、類似度判定は、速度が遅いとの声をよく聞きます。 MinHashアルゴリズムというものを使っているのですが、結局、pythonでもろもろ動かしている*ので、あまり速度が早くないようです。
*ハッシュの処理、set判定のためのfor loopなど
code中にも、todoとして、c++で実装なおしたい的なことが書いてありました。
以下のような類似度判定クラスを作っておきます。
import joblib
from hojichar import deduplication, Document
class Deduplicator:
def __init__(self, hasher, cache_path="cache", init=False):
self.hasher = hasher
self.cache_path = cache_path
if init:
self.seen = set()
else:
try:
self.seen = joblib.load(self.cache_path)
except FileNotFoundError:
print("No cache found, initializing new cache.")
self.seen = set()
def is_duplicated(self, text):
doc = Document(text)
self.hasher.apply(doc)
for lsh in doc.dedup_lsh:
if lsh in self.seen:
self.seen.add(lsh)
return True
self.seen.add(lsh)
return False
def save_state(self):
joblib.dump(self.seen, self.cache_path)all_linesに適当なテキストを入れておき、データ数を変えながら、処理時間を見ていきます。
res_list=[]
for check_n in [100,200,500,1000,2000]:
dedup=Deduplicator( deduplication.GenerateDedupLSH())
start = time.time()
for i in range(check_n):
(dedup.is_duplicated(all_lines[i]))
print(f"check_n:{check_n} time:{time.time()-start}")
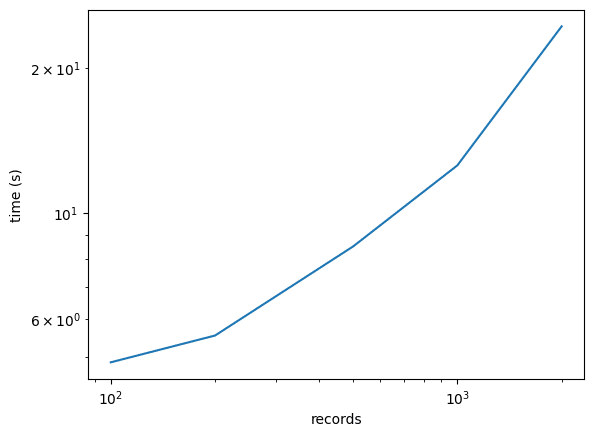
res_list.append({"check_n":check_n,"time":time.time()-start})結果
2000件で20秒はかかりました。大規模言語モデルのコーパスは、軽くmillion以上のデータがあるので、これをそのまま用いるのは、流石に無理筋といえます。
RapidFuzz
類似度判定は普通、テキストをハッシュ化して行います。
こちらのライブラリは、普通にテキストを比較するようです。内部はcで動いているようなので、速度も担保されます。並列化(workersの指定)も容易です。
以下のコードでは、文書間の類似度を計算するmatrixを生成します
(類似テキストの削除のアルゴリズムは実装してないので、正確な比較ではない点に注意)
import time
from rapidfuzz.process import cdist
res_list=[]
for check_n in [100,200,500,1000,2000]:
#for check_n in [100,1000,5000,10000,20000,50000]:
start = time.time()
scores = cdist(all_lines[:check_n], all_lines[:check_n],workers=1)
#scores = cdist(all_lines[:check_n], all_lines[:check_n],workers=16)
print(f"check_n:{check_n} time:{time.time()-start}")
res_list.append({"check_n":check_n,"time":time.time()-start})
#%time scores = cdist(all_lines[:check_n], all_lines[:check_n],workers=16)1並列の結果
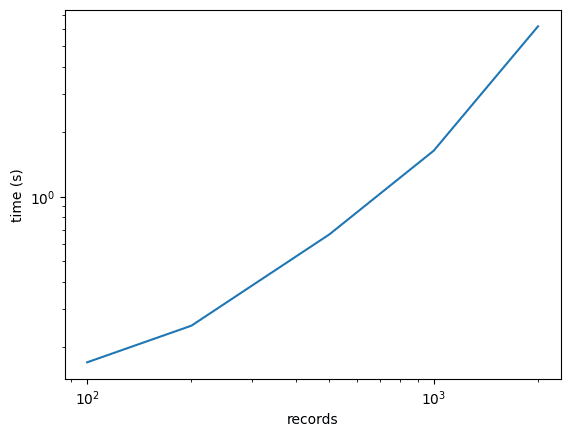
まずは普通に回した結果。2000件で6秒なので、hojicharよりも早いです。
1並列 with 文書を短くする
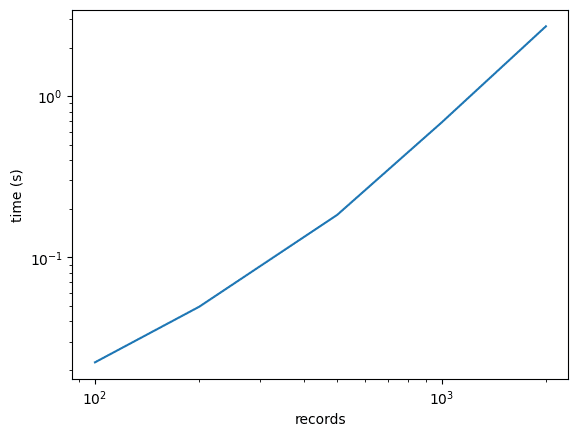
重複の多い文章というのは、わりと出だしからそっくりなことが多いです。そこで、はじめの100文字のみを判定してみました。その結果、2000件で3秒まで処理速度が減りました。
16並列 with 文書を短くする
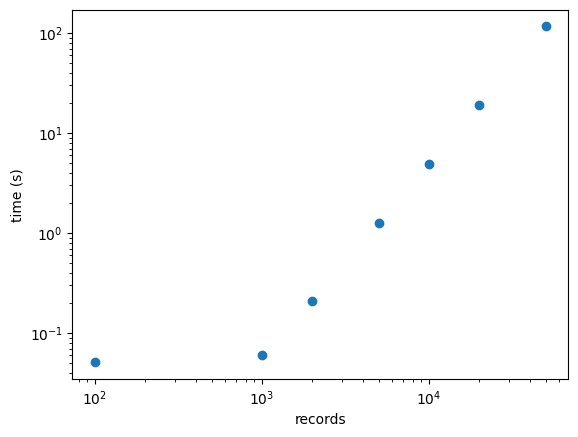
このライブラリの良いところは、わりと簡単に並列化ができる点です。例えば16並列で動かしてみたところ、2000件で0.2秒という結果になりました。コーパスの重複判定用途としては、最低でもこれくらいはないときついです。
結果は以下の通り
check_n:100 time:0.05085897445678711
check_n:1000 time:0.06066083908081055
check_n:2000 time:0.20825457572937012
check_n:5000 time:1.2620820999145508
check_n:10000 time:4.878591775894165
check_n:20000 time:19.23476004600525
check_n:50000 time:117.07648491859436log-logプロットを打ったところ、1000件以上のrecordでは、わりときれいな直線に乗りました。類似度判定のコストは、O(N^2)っぽいので、妥当な結果です。
これで、必要な計算量を推定できます。
まとめ
類似度判定の速度を軽く比較しました。
Pythonだと遅いのは当たり前なんですが、アルゴリズム上、Cなんかを使っても、O(N^2)は避けられないので、やはり、Nを小さく留めるのが一つの戦略になります。LSHや、クラスタリングなどが必要ということになりそうです。
この記事が気に入ったらサポートをしてみませんか?