
【SDXL】VRAM8GBでもAnimagineXLが動く! 低スペGPUとSDXLでAI画像生成!【RTX3060Ti検証】

この記事では画像生成AIのローカル環境実装のStable Diffusion上でSDXL系モデルを動かす際、(一般的に力不足とされる)VRAMが8GBのGPUであるRTX3060Tiから利用する方法を解説します。動作も実用レベル。Stability MatrixのInferenceというAutomatic1111に似たUIを使います。
どうもこんにちわ、生成AI勉強会というワークショップにて、画像AI限界オタクサイドとして参加させてもろたカガミカミ水鏡です。次回も大阪で開催されるという事なのでご興味あればぜひー!
はじめに
ところで、SDXLベースのAnimagineXL3.0が人気ですね(2024/01現在)!

画像出力のクオリティも高い事もそうですが、プロンプトの理解度が他モデルと比較しても頭1つ抜けて優秀ですね。モノクロ線画系も、より忠実度が上がり、応用範囲が増えたかなと思います。

プロンプトの理解度といえば、例えば従来のSD環境で難しかったカラーリップやヴィランマスクなど、人体という(AIにとっての)固定観念から逸脱したアブノーマルなデザインが出やすくなって、こう、捗りますね……ええ……

さて、フォロワーさんやお友達の方から、俺のパソコンだとGPUが弱くてVRAM8GBしかないからSDXLはキツイかな……という声を伺うことがありました。実際、SDXLを利用する場合にStable Diffusion WebUI automatic1111(以下A1111)を使う場合は、経験上、全く動作しないということはないものの、拡張機能モリモリの環境だったりLoRAモリモリにすると、VRAMが足りない警告が出てしばしば再起動が必要になるとストレスのかかる環境になってしまいます。
でも、A1111が使えないなら、ComfyUIを使えばいいじゃない!
前回の記事でも語りましたが、ComfyUIはA1111に代わる実装で、特徴の一つとしては、他の実装と比べてVRAM使用量が低く、かつ生成速度まで速いので、低スペックGPUにおける運用では最高の相棒であることに間違いありません。
んが、もう一つの特徴としては、これがノードモジュラー式のUIであるということ。こちらがcomfyui最大の特徴なのですが、利点でもあり欠点でもあります。利点はとにかく柔軟性や出来ることが多くなる、という辺りですが……
まあその、使いづらいと思います。普通は。DTMやDTVや3DCGやゲームエンジンでも齧ってない限り、こんなタコ足配線みたいなもん見た事ないと思います。

つまりSDXL環境において、PCスペックと使いやすさはバーターな逆相関。理想を言えば、A1111みたいな普通の見た目で、comfyUIと同じ軽さのSDXL環境があれば……
それが今回ご紹介する 「Stability Matrix」の「Inference」なんですよ! これなんと無料です!(ジャパネットたかたの番組思い出しながら描いてる)
この45秒の動画。よく見るとコンソールにVRAM8GBとなっていて、実際にAnimagineXL3.0で生成できてるのが解りますね!
SDXL(animagineXL3.0)をVRAM8GBのRTX3060Tiで使う方法、記事にするかな pic.twitter.com/9FlI1BFnyB
— カガミカミ水鏡👯♀️AI糞土方 (@kgmkm_mkgm) January 19, 2024
Stability MatrixとはStable Diffusionの色々なUI環境(A1111やComfyUI、Kohya-ssなども)やモデル(checkpointやembedding、LoRAなど)をダウンロードして管理できる統合プラットフォームみたいなソフトです。
つまりA1111を使うために利用している方が多いのですが、後に追加された機能「Inference」で、このソフト単体でも動作するようになりました! ……と平たく言えばそうなりますが、このソフト上でcomfyUIを起動する必要があります。わかる人向けに語るなら、ComfyUIをAPI経由でソフトから利用できるようにしたComfyUIのUIなのです。UIのUI!
さて、御託はさておき、実際に俺が持っているGPUで最もVRAMが少ない8GBのRTX 3060Tiで、実際に試してみましょうか!
そうそう、ここからの情報は、OSがWindows10以降であるとの想定で書いていますが、Linuxでも動作します。Mac版も最近出たので、M2などapple siliconをお持ちの方は試してみて俺に教えてください。
【下準備】Stability Matrixとモデルを用意する
さて、まずはStability Matrix(以下SM)をインストールしていない方は先にインストールしといてください。俺も世に出たばかりの時に下の記事を書いてますが、情報古めなのを気にされるならこのソフト名で検索した方がいいすね。
起動できたら、左サイドパネルのPackage(マウスオーバーで説明出てくると思います)を開き、下の「パッケージの追加」から必ずComfyUIをインストールしてください。といいつつ初回起動時には必ず「なんかのパッケージインストールしてね!」的な画面が出るので、そこからComfyUIをインストールするのが一番楽かも。


そして左サイドパネルのModel Browserから、checkpointを一つ以上インストールしましょう。とは言え今回の目的は「AnimagineXL」を使うこと。検索窓に「AnimagineXL」で検索し、出てきたサムネからそれっぽいもの、かつ一番新しそうなやつをインポートしてください。ついでに使いたいLoRAなどあればついでにインストールしとくといいでしょう。とりまのオススメは画像のディテール調整の定番「Detail Tweaker XL」と高速化に役立つ「lcm-lora-sdxl」。あとembbedingで失敗作を減らす「unaestheticXL_hk1」を強く推奨。

※ ……で上手く行けばいいのですが、検索で出てこない? ダウンロード出来ない?サムネにオーバーレイで表示されるダウンロード進捗が止まったまま? それはモデル配布サイトのcivit.aiが止まっているからだよ。10分後にお試しください。 まだ止まってる場合は……うん、またなんだ。すまない。
最後にLaunchから低VRAM向けの設定をしましょう。左側のロケット🚀のアイコンがLaunchタブです。Launchを開き、上部からcomfyUIを選択し、その左隣、緑のLaunchボタンの右隣にある歯車⚙をクリック。

Launch Optionsが開いたらVRAMを探し、--lowvram にチェックを入れて保存を押しましょう。終わったら緑のLaunchボタンを押しときましょう。これでComfyUIが起動します!
【使ってみる】InferenceからSDXLモデルで画像を生成する
さて、準備が整ったらInferenceを動かしてみましょう! まずは左サイドパネルからInferenceを開きます。
※ 2回め以降の利用など、先程紹介したLaunch画面で緑のボタンを押していない場合、画面右上「接続待ち」のボタンが現れます。こいつをクリックすると「ComfyUI必要だけど起動しとこか?」との旨で訊ねて来るので起動します。すると右上の表示が変わるかと思います。

左側パネルの右上がModel選択のドロップダウンになっています。ここからAnimagineXLを選択。幅と高さを、とりま1024x1024に設定。他の設定は、分かる方はお好みで。余談ですが俺なんかはSamplerなんかをUniPC BH2かLoRAと合わせてstep10程度で高速生成できるLCMにしがちです。選べる種類もComfyUI準拠ですね。
そして右隣にプロンプトをpositiveとnegativeに入れて「generate image」を押す! うまく行けば右側に生成画像プレビューが表示されたはず!

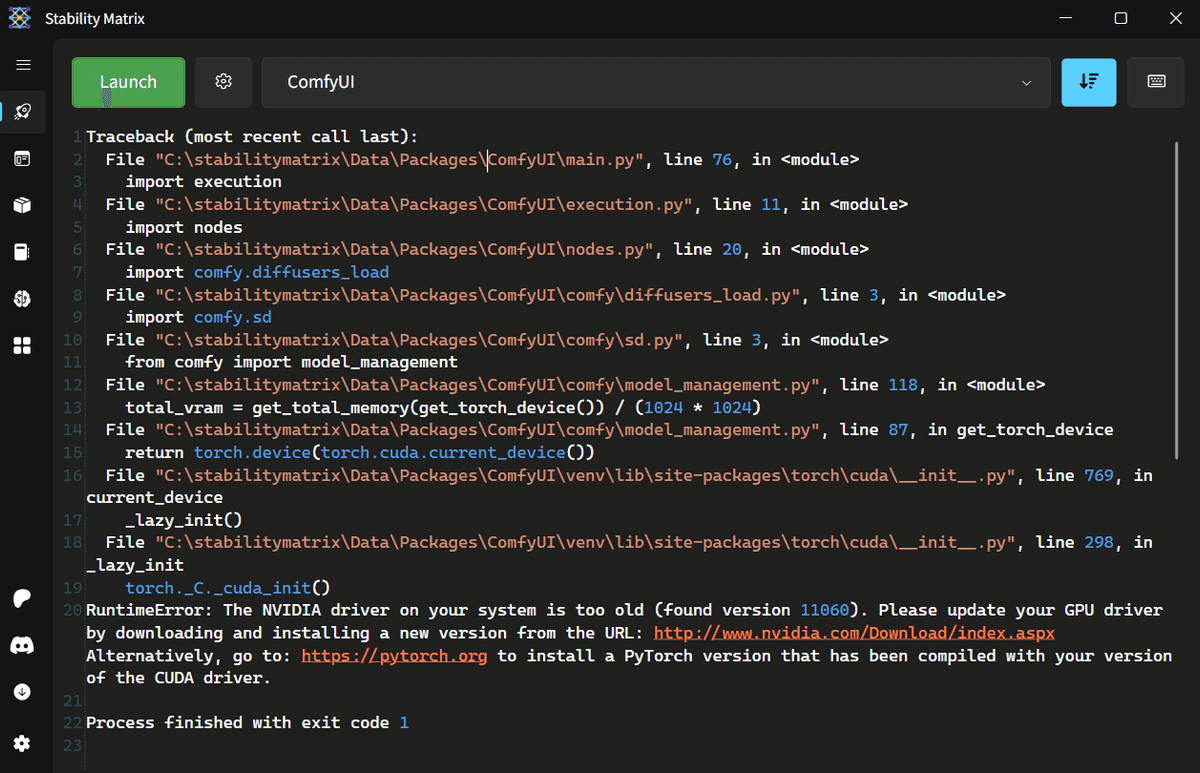
※ うまくいかない場合は左サイドパネルのLaunch(ロケットのアイコン)を見てみてください。そこにcomfyUIの動作ログが載ってるので、そこにヒントがあるかも……? 例として以下。こちら最後の「RuntimeError」をよく読むと「手前のNVIDIA GeForceドライバ古いんだよォ!」と親切に罵倒してきてますね。
生成画像は、インストール時に指定した「データフォルダ」から「\データフォルダ\Images\Inference\」に入ってます。たとえばPortableモードにてインストールして、Dドライブにデータフォルダを指定した場合は「D:\StabilityMatrix\Data\Images\Inference\」とかに入ってる筈。「D:\Images\Inference\」かも。
また何枚か生成すると、画面最右に画像履歴が表示されているのが分かるかと思います。 マウスホイールで履歴を辿れるので結構便利。右クリックでjpgやwebpなどに変換できます。
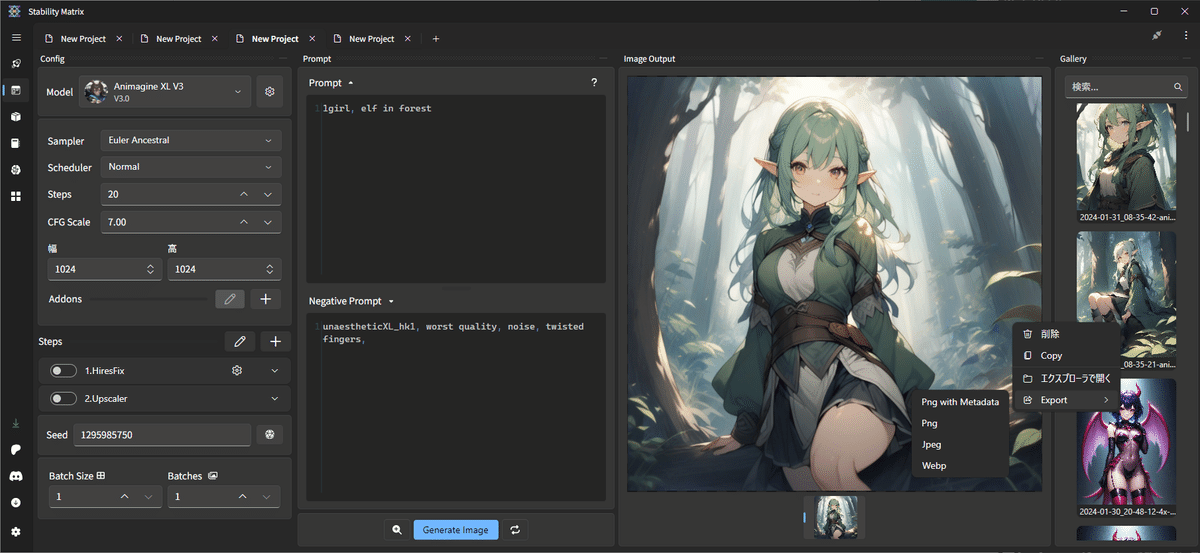
またココの画像にonMouseすると、生成時のプロンプトが確認できます。さらに画像をUIにドラッグドロップすると、その時のプロンプトをはじめとした設定を読み込むことができます。シードもその画像を生成したものにロックされているので、そのまま生成すると同じ画像を量産してしまいます。錠前アイコンをクリックして外しといてください。

Inferenceでも使える機能まとめ!
さて、Inferenceは簡易版生成環境という位置付けで、かつ絶賛開発中の機能です。つまりInferenceでも可能なことと不可能なことがあるのですが、まずはA1111と比較して可能なことを列挙していきましょう。
Lora & embedding
もちろん使えます! こちらはプロンプト欄にタグを書いて直接指定する形ですね。またembeddingも、明示的にカッコに囲んで記述することもできます。俺はこちらの方が見やすくて多用しますが、こちらはLoRA記法と違ってA1111と互換性が無いので、プロンプトでコピーする時はご注意。

プロンプトの推測入力
プロンプトの入力支援でお馴染みの予測変換も使えます!最初から有効になっているかと思います。 a1111-tag-autocomplete拡張とおなじcsvフォーマットが使えるので、カスタマイズしたい方は左下歯車マークのSetting→Inferenceから。

Image2Image (i2i)
できます! 上部タブの「➕」ボタンを押し、Image2Imageを選択。あとは普通に画像を読み込むだけ! ……なお、windowsエクスプローラから画像をドラッグドロップというのは使えないみたい……
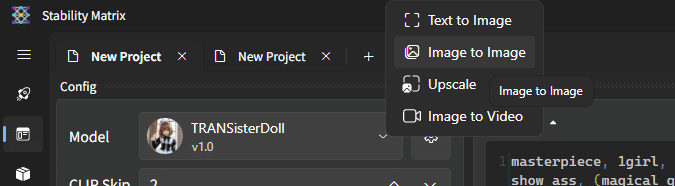
Image2Video (Stable Video Diffusion利用)
できんのこれ!? まだ2.8先行プレビュー版なので一般公開されてませんが動きます!
Stability Matrix Inferenceで! Stable Video Diffusionが! うごく! しかもVRAM8GBの3060Tiで! はやい!! pic.twitter.com/faCd8UMbCX
— カガミカミ水鏡👯♀️AI糞土方 (@kgmkm_mkgm) January 31, 2024
Hires Fix / Upscaler
使えます! Hires FixだとLatentは出来ませんが、ESRGANやUltraMixが使えるのは便利。Upscalerは精細度を求める場合は力不足ですが、単純にディテールを強化して拡大する際は便利。使い分けましょう。
FreeU
使えるけど……使って画像が良くなった試しがない……
Inferenceだと諦めてほしい機能まとめ!
最後にご注意。A1111や別のもので使える記法などは使えません。これらを多用する場合は、A1111等を導入してSDXLで動くかワンチャン試すしかないです。
Image2Imageのinpaint
画像の一部にマスクを掛けてi2iをする方法。便利ですが使えません。
ControlNet
UIにはあるんですが、SDXL用のControlNetを使っても反映されないです……。ところがComfyUIで組めば動く。一旦開発に連絡してみます。まだ開発中だったかも?
プロンプトの適用タイミング調整( [red:blue:0.5] みたいな記法)
A1111特有の記法ですね。めっちゃ便利で多用するんですが(特に巫女衣装の中にハイレグレオタードを着せる時に[latex highleg leotard:miko clothing:0.2]するなど)、こちらは使えません。 ComfyUIとかで使えたりするんでしょうか……?識者求む。
LoRAの層別適用(LoRA Block Weight拡張相当)
A1111拡張機能なので、使えません。俺も過去に記事にしたこともあり、これも結構便利なシーンがあるんですけどね……。
もちろん、LoRA Block Weightだけに留まらず、A1111の拡張機能はほぼ使えません。
この記事が気に入ったらサポートをしてみませんか?