
映画好き必見!Pythonで解き明かす映画評価データの秘密とは?【データ分析】

データサイエンスに関して、自分もまだまだ初心者ですので今回はPythonを使ったデータサイエンスの勉強目的として「映画の評価データを分析する」というテーマに挑戦してみようと思います。
やること
✅ Pythonでデータ分析
✅ 映画の評価データを分析
使うもの
✅ Python
✅ APIサービス
✅ Google Colaboratory
はじめに
この記事では、映画の評価データを取得して、そのデータを用いて、以下のような分析を行います。
👉 評価の高い映画のジャンルを調べる
👉 評価の分布を可視化して、評価の偏りを調べる
👉 評価の低い映画のジャンルを調べる(執筆中)
👉 評価の高い映画と低い映画の特徴的な単語を調べる(執筆中)
※(執筆中)についてはすみません、近日公開予定です。😅
これらの分析を行うためには、PythonのライブラリであるPandasやMatplotlibを使用することができます。また、映画の評価データは、公開されているAPIを使用して取得することができます。
Pythonの基礎やデータ分析の手法を学びながら、興味深い結果を得ることに期待するとします。
映画の評価データを取得するAPIサービス
無料で使える映画の評価データを取得するAPIサービスとしては、以下のものがあります。
👉 【IMDb API】
IMDbは、映画やテレビ番組に関するデータを提供する有名なウェブサイトです。IMDb APIを使うと、映画の評価、レビュー、キャスト、トレイラーなどの情報を取得できます。APIの使用にはAPIキーが必要ですが、無料のAPIキーも提供されています。
👉 【TMDB API】
TMDBは、映画やテレビ番組に関する情報を提供するウェブサイトで、IMDbと同様のデータを提供します。TMDB APIを使うと、映画の評価やレビュー、キャスト、トレイラー、推奨作品などの情報を取得できます。APIキーを取得するには、無料のアカウント登録が必要です。
👉 【OMDb API】
OMDbは、IMDbとTMDBのデータを統合し、独自のAPIを提供するウェブサイトです。OMDb APIを使うと、映画の評価、レビュー、キャスト、トレイラー、あらすじなどの情報を取得できます。APIの使用にはAPIキーが必要で、無料のAPIキーも提供されています。
これらのAPIを使うことで、Pythonを使った映画の評価データの分析が可能になります。
今回は「TMDb」のAPIサービスを利用してみたいと思います。
アカウント登録
APIサービスを使用するにはアカウント登録が必要なので、まずアカウント登録します。








実際にAPIキーを使ってデータを取得してみる
APIキーを発行できたので、実際にデータを取得してみましょう。
やり方
requestsモジュールをインストールします。
pip install requestsTMDbのAPIキーを変数に格納します。
api_key = "ここにAPIキーを入力"APIエンドポイントを変数に格納します。
url = f"https://api.themoviedb.org/3/movie/{movie_id}?api_key={api_key}"requestsモジュールを使ってAPIエンドポイントにリクエストを送信し、レスポンスを受け取ります。
response = requests.get(url)レスポンスのJSONデータをPythonの辞書型に変換します。
data = response.json()変換したデータから、評価情報を取得します。
rating = data["vote_average"]以上の手順で、TMDb APIを使って映画の評価を取得するPythonコードを記述できます。movie_idには映画のIDを、api_keyには自分のTMDb APIキーを入力してください。
movie_idはTMDbのサイト内で調べると確認できます。「アバター」を例に調べてみると以下のような感じになります。

実装コード
さっきの「アバター」のデータを取得してみます。
movie_idは「76600」ですね。
import requests
api_key = "ここにAPIキーを入力"
movie_id = "76600"
url = f"https://api.themoviedb.org/3/movie/{movie_id}?api_key={api_key}"
response = requests.get(url)
data = response.json()
print(data)
取得したJSONファイルの中身は以下のような感じになってます。
{
'adult': False,
'backdrop_path': '/s16H6tpK2utvwDtzZ8Qy4qm5Emw.jpg',
'belongs_to_collection': {
'id': 87096,
'name': 'Avatar Collection',
'poster_path': '/uO2yU3QiGHvVp0L5e5IatTVRkYk.jpg',
'backdrop_path': '/iaEsDbQPE45hQU2EGiNjXD2KWuF.jpg'
},
'budget': 460000000,
'genres': [
{
'id': 878,
'name': 'Science Fiction'
},
{
'id': 12,
'name': 'Adventure'
},
{
'id': 28,
'name': 'Action'
}
],
'homepage': 'https://www.avatar.com/movies/avatar-the-way-of-water',
'id': 76600,
'imdb_id': 'tt1630029',
'original_language': 'en',
'original_title': 'Avatar: The Way of Water',
'overview': 'Set more than a decade after the events of the first film, learn the story of the Sully family (Jake, Neytiri, and their kids), the trouble that follows them, the lengths they go to keep each other safe, the battles they fight to stay alive, and the tragedies they endure.',
'popularity': 1287.023,
'poster_path': '/t6HIqrRAclMCA60NsSmeqe9RmNV.jpg',
'production_companies': [
{
'id': 574,
'logo_path': '/iB6GjNVHs5hOqcEYt2rcjBqIjki.png',
'name': 'Lightstorm Entertainment',
'origin_country': 'US'
},
{
'id': 127928,
'logo_path': '/cxMxGzAgMMBhTXkcpYYCxWCOY90.png',
'name': '20th Century Studios',
'origin_country': 'US'
}
],
'production_countries': [
{
'iso_3166_1': 'US',
'name': 'United States of America'
}
],
'release_date': '2022-12-14',
'revenue': 2247708213,
'runtime': 192,
'spoken_languages': [
{
'english_name': 'English',
'iso_639_1': 'en',
'name': 'English'
}
],
'status': 'Released',
'tagline': 'Return to Pandora.',
'title': 'Avatar: The Way of Water',
'video': False,
'vote_average': 7.733,
'vote_count': 5473
}JSONファイルでデータを取得できたので、必要なデータをここから抽出して使っていきます。例えば評価情報を取得する場合、下記のような指定になります。
# 変換したデータから、評価情報を取得します。
rating = data["vote_average"]
print(rating)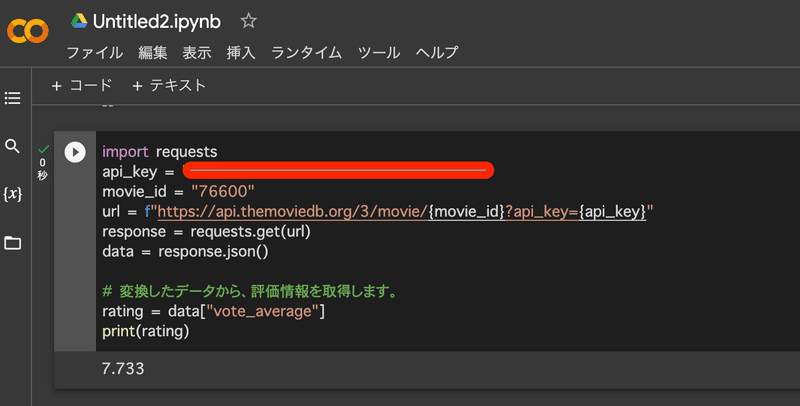
こんな感じで必要なデータを取得できます。
評価の高い映画のジャンルを調べる
作成したコードは以下になります。
import requests
# TMDb APIキー
api_key = 'YOUR_API_KEY_HERE'
# TMDb APIから映画のリストを取得するためのURL(&language=en-US)
url = f'https://api.themoviedb.org/3/movie/top_rated?api_key={api_key}&language=en-US&page=1'
# APIにリクエストを送信して映画のリストを取得
response = requests.get(url)
movie_list = response.json()['results']
# ジャンルのカウントを初期化
genre_count = {}
# 各映画についてジャンルをカウントする
for movie in movie_list:
# 映画の詳細を取得するためのURL
movie_url = f'https://api.themoviedb.org/3/movie/{movie["id"]}?api_key={api_key}&language=en-US'
# APIにリクエストを送信して映画の詳細を取得
movie_response = requests.get(movie_url)
movie_details = movie_response.json()
# 映画のジャンルをカウントする
for genre in movie_details['genres']:
if genre['name'] in genre_count:
genre_count[genre['name']] += 1
else:
genre_count[genre['name']] = 1
# ジャンルを出現回数の降順にソート
sorted_genres = sorted(genre_count.items(), key=lambda x: x[1], reverse=True)
# 上位10ジャンルを出力する
for i in range(10):
print(sorted_genres[i][0], sorted_genres[i][1])
上位のジャンルが出力されました。数字は出現回数ですね。
分布を可視化して、評価の偏りを調べる
先程の出力結果をグラフにしてみましょう。
import matplotlib.pyplot as plt
# データ
genres = ['Drama', 'Crime', 'Fantasy', 'Romance', 'Comedy', 'Animation', 'Thriller', 'Family', 'Adventure', 'Action']
counts = [12, 7, 5, 5, 4, 4, 3, 2, 2, 2]
# 棒グラフを作成
plt.bar(genres, counts)
# グラフタイトル
plt.title('Distribution of High Rated Movie Genres')
# 軸ラベル
plt.xlabel('Genres')
plt.ylabel('Counts')
# x軸のラベルを90度回転
plt.xticks(rotation=90)
# グラフを表示
plt.show()
こんな感じで出力した数字をグラフにして可視化できます。
その他参考になるサイト
使ったコードは全く異なりますが、「TMDb」のAPIサービスを使ってできることに関してQiitaで一覧化されてたので、こちらも紹介いたします。
その他詳細なデータの取り方についてもまとめられていますので、もっと応用したデータ分析を行なってみたい場合は、この方のコードを参考にしてみると良いかもしれません。
この記事が気に入ったらサポートをしてみませんか?