
トレーニング環境をAWS SageMakerからGCP Vertex AIへ移行したよ

こんにちは、すずきです。
以前、モデルのトレーニングにAWSのSageMaker Studioをつかっていたのですが、期間限定で$100,000(1500万円..!)のGCPクレジットをいただいたので(Google Cloud for Startupsによるスタートアップ支援)、トレーニング環境をVertex AI Workbenchに移行しました。
SageMakerとVertex AIで使い勝手がところどころ違ったので、移行プロセスを共有します。
こちらは以前書いたSageMakerによるFine-Tuningの記事です。
モデルトレーニング環境の構築
Dockerfileの作成
SageMakerではアプリケーションコードをコンテナイメージに含めず、dependenciesで外部からコードを読み込み、entry_pointで指定したシェルスクリプトを通じてConda環境の切り替えやコードの実行を行なっていました。
SageMakerのトレーニングスクリプト
import sagemaker
from sagemaker.estimator import Estimator
session = sagemaker.Session()
role = sagemaker.get_execution_role()
estimator = Estimator(
image_uri="*****.dkr.ecr.ap-northeast-1.amazonaws.com/bert-training:latest",
role=role,
instance_type="ml.g4dn.2xlarge",
instance_count=1,
base_job_name="pre-training",
output_path="s3://sagemaker/output_data/pre_training",
code_location="s3://sagemaker/output_data/pre_training",
sagemaker_session=session,
entry_point="pre-training.sh",
dependencies=["bert-training"],
checkpoint_s3_uri="s3://sagemaker/checkpoints/summary", # checkpointsにリアルタイム保存
checkpoint_local_path="/opt/ml/checkpoints/", # checkpointsにリアルタイム保存
use_spot_instances=True, # スポットインスタンスの利用
max_wait=120*60*60, # インスタンス枯渇時の待ち時間
max_run=120*60*60, # Jobの最大時間
hyperparameters={
"wandb_api_key": "*******",
"mlm": True,
"do_train": True,
"field_hs": 64,
"output_dir": "/opt/ml/checkpoints/",
"data_root": "/opt/ml/input/data/input_data/",
"data_fname": "pre_training_data",
"num_train_epochs": 3,
"save_steps": 100,
"per_device_train_batch_size": 8
},
tags=[{'Key': 'Project', 'Value': 'AIResearch'}]
)
estimator.fit({"input_data": "s3://sagemaker/input_data/pre_training_data.csv"})Vertex AIではSageMakerのようにentry_pointを指定するような方法がないため、アプリケーションコードをコンテナイメージに含め、Conda環境を使用せずに必要なパッケージを直接インストールするような形にしました。
Vertex AI用のDockerfile
# Vertex AIでのモデルのトレーニング用のDockerfile
# pre-training
# Conda環境を使用せず、必要なPythonッケージを直接インストール
FROM gcr.io/deeplearning-platform-release/pytorch-gpu.1-12
# 環境変数の設定
ENV PYTHONDONTWRITEBYTECODE=1 \
PYTHONUNBUFFERED=1
# ワーキングディレクトリの設定
WORKDIR /app
# Pythonと必要なパッケージのインストール
RUN apt-get update && apt-get install -y \
build-essential \
&& rm -rf /var/lib/apt/lists/*
# Pythonパッケージのインストール
RUN pip install --no-cache-dir \
pandas==1.4.3 \
scikit-learn==1.1.1 \
transformers==4.26.0 \
numpy==1.23.1 \
imbalanced-learn==0.10.1 \
wandb \
python-dotenv \
google-cloud-storage
# アプリケーションのコピー
COPY . /app
# コンテナ起動時に実行されるコマンド
ENTRYPOINT ["python", "main.py"]コンテナイメージのデプロイ
以下のコマンドを使用して、作成したDockerイメージをGoogle CloudのArtifact Registryに配置します。
docker buildx build --platform linux/amd64 -f Dockerfile.vertex -t asia-northeast1-docker.pkg.dev/ai/bert-training/pre-training:latest .
gcloud auth configure-docker asia-northeast1-docker.pkg.dev
docker push asia-northeast1-docker.pkg.dev/ai/bert-training/pre-training:latest入力データの移行
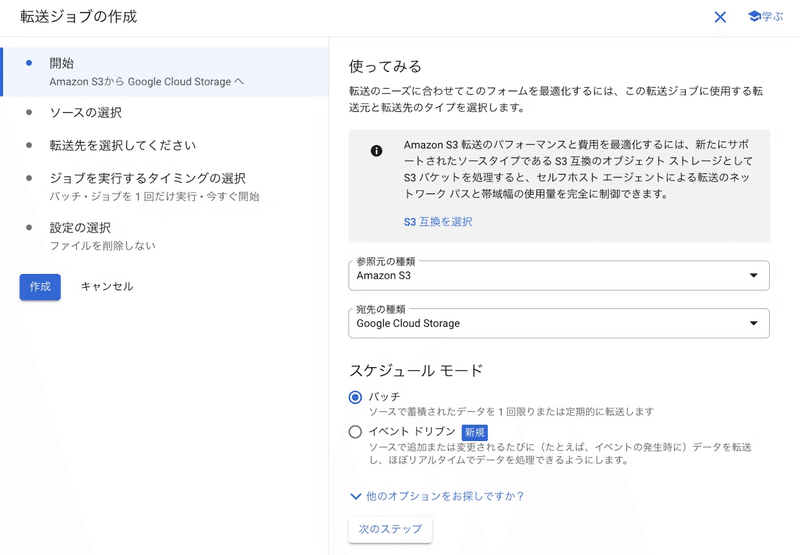
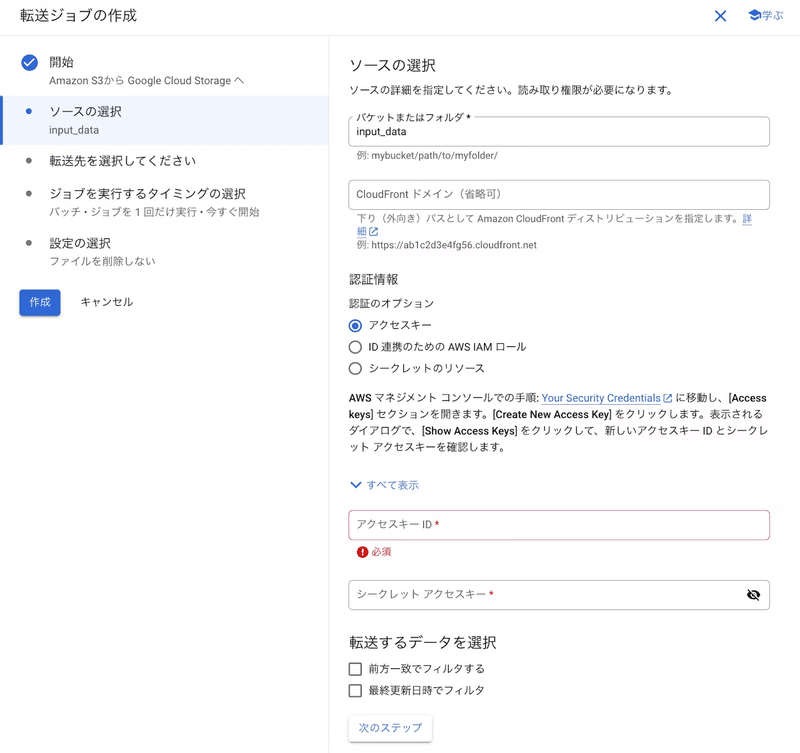
以下が転送ジョブでデータをS3からCloud Storageに移行する手順です。
Cloud Storageで「転送ジョブを作成」を開きます
参照元の種類として「Amazon S3」を、宛先の種類として「Google Cloud Storage」を選択します
AmazonS3ReadOnlyAccessを付与したIAMユーザーを作成し、発行されたクレデンシャル(アクセスキーID、シークレットアクセスキー)を入力します
転送先のバケットを指定し、転送ジョブを開始します
トレーニングスクリプトの作成
Vertex AIではトレーニングスクリプトを以下のように書けます。
from google.cloud import aiplatform
from google.cloud.aiplatform import gapic as aiplatform_gapic
def create_custom_job(
project: str,
display_name: str,
container_image_uri: str,
location: str = 'asia-northeast1',
args: list = None,
bucket_name: str = None,
):
# クライアントの初期化
aiplatform.init(project=project, location=location, staging_bucket=bucket_name)
custom_job = {
"display_name": display_name,
"worker_pool_specs": [{
"machine_spec": {
"machine_type": "n1-highmem-32",
"accelerator_type": "NVIDIA_TESLA_V100",
"accelerator_count": 4,
},
"replica_count": 1,
"container_spec": {
"image_uri": container_image_uri,
"args": args,
"env": [{}]
},
}]
}
# カスタムジョブの作成
job = aiplatform.CustomJob(**custom_job)
job.run(sync=True)
project_id = 'ai'
display_name = 'pre-training'
container_image_uri = 'asia-northeast1-docker.pkg.dev/ai/bert-training/pre-training:latest'
bucket_name = 'gs://bert-training'
location = 'us-central1'
args = [
"--mlm",
"--do_train",
"--field_hs", "64",
"--data_fname", "pre_training_data",
"--num_train_epochs", "1",
"--save_steps", "100",
"--per_device_train_batch_size", "8",
"--gcs_bucket_name", "bert-training",
"--gcs_blob_name", "vertex/input_data/pre_training_data.csv",
"--local_data_path", "./data/action_history/pre_training_data.csv"
]
# ジョブの作成と実行
create_custom_job(
project=project_id,
display_name=display_name,
container_image_uri=container_image_uri,
bucket_name=bucket_name,
location=location,
args=args,
)Vertex AIでは、SageMakerのようにS3のパスを指定して自動的に入力データをコンテナパスに配置する機能がありません。そのため、データのダウンロードとトレーニング後のアーティファクトのアップロード処理をアプリケーション側で明示的に行う必要があります。
以下の関数は、Cloud Storageからファイルをダウンロードおよびアップロードするためのものです。
from google.cloud import storage
import os
def download_csv_from_gcs(bucket_name, source_blob_name, destination_file_path):
storage_client = storage.Client()
bucket = storage_client.bucket(bucket_name)
blob = bucket.blob(source_blob_name)
blob.download_to_filename(destination_file_path)
print(f"CSVファイル {source_blob_name} を {destination_file_path} にダウンロードしました。")
def upload_directory_to_gcs(bucket_name, source_directory, destination_blob_prefix):
storage_client = storage.Client()
bucket = storage_client.bucket(bucket_name)
for root, _, files in os.walk(source_directory):
for file in files:
local_path = os.path.join(root, file)
relative_path = os.path.relpath(local_path, source_directory)
blob_path = os.path.join(destination_blob_prefix, relative_path)
blob = bucket.blob(blob_path)
blob.upload_from_filename(local_path)
print(f"{local_path} を {blob_path} にアップロードしました。")
アプリケーションにこれらの関数を追加すると以下のようになります。
def main(args):
# (コードの詳細は省略)
# トレーニング完了後に出力をCloud Storageにアップロード
output_dir = args.output_dir # トレーニング出力が保存されているローカルディレクトリ
bucket_name = args.gcs_bucket_name # Cloud Storageのバケット名
destination_blob_prefix = 'vertex/output_data/pre_training'
upload_directory_to_gcs(bucket_name, output_dir, destination_blob_prefix)
if __name__ == "__main__":
parser = define_main_parser()
opts = parser.parse_args()
download_csv_from_gcs(opts.gcs_bucket_name, opts.gcs_blob_name, opts.local_data_path)
main(opts)補足1:リージョナルな制約
モデルトレーニングのためにasia-northeast1(東京)でNVIDIA Tesla V100 GPUを使おうとしたらエラーになりました。
調べたところ、asia-northeast1で使えるGPUに結構制限があったので、us-central1(アイオワ)にリージョンを変更しました。
リージョナルなリソースの違いは、移行前に考慮すべきでした..
補足2:スポットインスタンスの利用不可
SageMakerでよく利用していたスポットインスタンスは、Vertex AIでは利用できません。
ただ、今回はGCPクレジットが潤沢にあったので、あまり問題ありませんでした。
それに、SageMakerでスポットインスタンスを利用していた際には、予期せぬトレーニング停止も経験していたので、Vertex AIでの確実なリソース確保が予想外のメリットとなりました。
採用情報
この記事が気に入ったらサポートをしてみませんか?