
LLMを用いた合成データ作成事例をまとめてみたーNLP2024参加報告①

お久しぶりです、三菱UFJフィナンシャル・グループの戦略子会社であるJapan Digital Design(以下JDD)でMUFG AI Studio(以下M-AIS)に所属する蕭喬仁です。
今年はJDDの中期経営計画1年目ということで、新しい取り組みが次々と始まり、期待と繁忙に対する不安に駆られている今日この頃です。
今回は、3月11日から3月15日にかけて神戸で開催された言語処理学会第三十回年次大会(以下NLP2024)に聴講参加してきましたので、個人的に興味深かったLLMによる合成データ生成関連の発表について紹介していきたいと思います。
JDDからは他4名の社員がNLP2024に参加していましたので、後に公開されるその他の参加報告もご覧いただけると幸いです。
※添付の画像は掲載がない限りは、リンク先の予稿集並びに発表資料を使用しています。
自動生成した NLI データを用いた教師なし文埋め込みの改良

最初に紹介するのは文埋め込みモデルの学習データ生成方法についての取り組みです。
デーコーダ系の大規模言語モデル(以下LLM)に対して「this sentence: “text“ mean in one word: 」と言ったpromptを用いることで文埋め込みを生成するPromptEOL系のモデルは文埋め込み性能が高い反面、学習に人手で構築された豊富な自然言語推論(Natural Language Inference: NLI)データが必要となります。この論文ではそのような課題をNLIデータの自動生成によって解決を試みています。
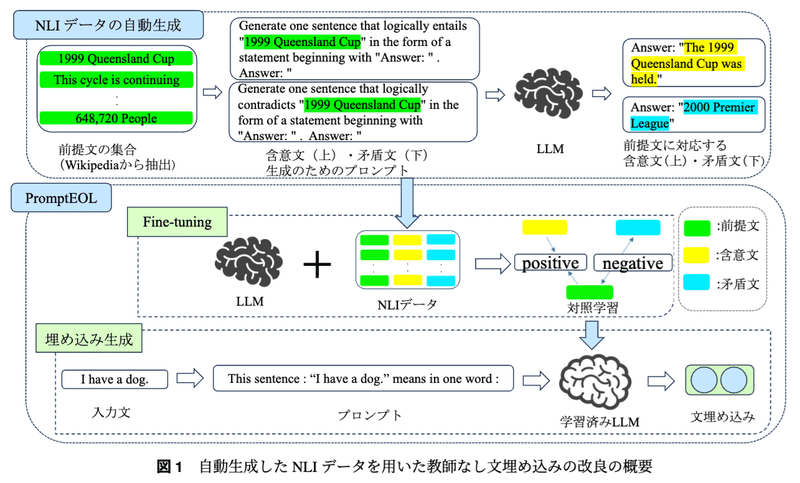
NLIデータの自動生成は上記のフローに沿って行われます。Wikipediaの文章からランダムに抽出された100万文に対して、以下のようなpromptとLLMを用いて含意文・矛盾文を生成します。本論文ではLLMにllama-2-7b-chatを用いて学習用データを生成しています。
Generate one sentence that logically entails "Fun for adults and children." in the form of a statement beginning with "Answer:". Answer: "Fun for both adults and children." Generate one sentence that logically entails "premise" in the form of a statement beginning with "Answer:". Answer: "
Generate one sentence that logically contradicts "{premise}" in the form of a statement beginning with "Answer:". Answer: "
LLMによって自動生成されたNLIデータの例は以下のようになっていました。自動推定カラムはNLIタスクによって学習させたdeberta-v2-xxlarge-mnliによっての推論結果です。自動生成時にpromptに含める例示数が増えることでより品質の高い文章が生成されていることが確認できます。

最後に、自動生成したNLIデータでfine tuningを行った文埋め込みモデルの性能を、人手で整備したNLIデータでfine tuningを行った場合とNLIデータセットを使用しないでfine tuningを行った場合との精度の比較表です。
一番右のAvg.列を見るのがわかりやすく、人手で整備したNLIデータで学習させた場合のPromptEOLモデルの精度が85.41%であるのに対して、本論文での提案手法による精度が82%前後と数%の低下はあるものの、かなり良い精度になっていることが確認できます。0-shotで生成したものはNLIデータを使わない場合よりも精度が低いですが、5-shot程度でも十分精度が高くなっている点が嬉しいポイントです。

実務的には今回使用した7Bのモデルよりも大きい13B, 70B, MoE系のモデルを使うことでこの辺りの精度はより高まるような気がします。また、自社ドメインの文章を用いてNLIデータセットを自動生成することで、業務特化した文埋め込みモデルを作成していくことができる点も期待できます。
機密情報検知における生成 AI を用いたデータ拡張

次に紹介するのはLLMのハルシネーション特性を逆手に利用していた面白い発表です。この取り組みでは企業名や法人名を機密情報とみなしてそれら固有表現抽出を抽出する際にLLMを用いたデータ拡張を提案しています。
本取り組みでは、機密情報検知のタスクでは本文中の検知対象表現が必ずしも実在するエンティティと紐づいている必要が無いことを着想としています。すなわち、発表者の所属企業である「フューチャー」は実在する IT コンサルティングファームでも将来的に誕生するかもしれない物流企業でも構わないということです。実在するエンティティと紐づいていないほうがむしろ多様性の観点で良いという仮定がLLMのハルシネーション特性とうまくマッチしていて目の付け所が非常に良いなと感じました。
論文中では以下のような「周辺文脈の拡張」と「エンティティの拡張」という二つの方法で事実にとらわれない多様なデータ拡張を実現しています。
「周辺文脈の拡張」では学習データ中のエンティティを一つ選び、それを含むような一文をLLMで生成した上で、元の文中のエンティティと置換するという方法です。
「エンティティの拡張」はより単純な方法で架空のエンティティをLLMによって生成し、元の文章のエンティティと置換する方法です。
生成に利用したLLMはgpt-3.5-turbo-16kとのことです。

Appendix. 中に書かれていたプロンプトにはエンティティを記述する位置を制御するパラメータLOCATIONを振っていたり、生成された英語法人名を大文字や小文字に変換したりするなどの処理を後処理で実施しているなど、細かい配慮がなされている点が印象的でした。

このように拡張したデータでBERT-CRFを学習させた結果が以下になります。学習および評価はストックマーク株式会社が公開するWikipediaデータを用いて実施したとありました。ベースラインは元の学習データの正例を5倍に複製したものとのことです。
表を見てみると、単純な置換ベースのベースラインよりもどちらの提案手法も精度が向上しており、エンティティの拡張に関しては既存研究よりも性能が上がっていることがわかります。この結果をみると学習データ中には存在しないエンティティを生成し、エンティティの多様性を向上させることが重要だったものと推測できます。

LLM学習用QAデータセットの自動構築手法の提案

最後に紹介するのは最終日に行われた「日本語言語資源の構築と利用性の向上」というワークショップで発表された取り組みです。
この取り組みでは、gpt-4やClaudeと言ったクローズドLLMに頼らず、ローカルLLMを用いてLLM学習用のQAデータセットを構築する方法の紹介がなされていました。業務データを用いてQAデータを作成する際、APIベースで提供されているクローズドLLMでは使用に耐えられないケースがあるため、今回の発表はとても参考になりました。以下の図が、入出力のイメージ図です。

この取り組みの中で特徴的だったのは、複数のモデル・プロンプト・温度パラメータを用いて生成した結果を人手で点数づけし、品質の比較をしている点です。
以下に比較結果を載せますが、モデルによって使用すべきプロンプトや温度パラメータが大きく変化していることが確認できます。モデル間の比較で見てみるとライセンスの自由度が高いmixtral8x7bモデルが最も品質が良さそうなのが、実務的に嬉しい結果となっています。

今回の推論はH100(80GB)を2台とvLLMによって高速化されたパイプラインを用いて実施されており質問1個あたり0.15秒の速度で生成できたようです。一方、同じタスクを人手で行うと1個あたり55秒かかったと記載があり、約380倍の高速を実現できたという点も目を見張りましました。自動生成したQAデータを用いたモデルの学習結果までは発表されていませんでしたが、実務的に大いに期待できる発表だったと思います。
まとめ
LLMを用いて擬似的なデータセットを作りモデルを学習させることで業務課題を解いていく観点で、個人的に面白かった発表を3件挙げさせていただきました。今回の記事では書ききれなかったですが、以下のような発表も同様な観点で参考になりましたので、興味を持った方はぜひ内容を確認してみてください。
また、JDDのM-AISチームではR&D活動として国内外の学会参加および発表を積極的に実施しています。以下に、昨年度の学会参加報告のリンクを挙げておきますので、気になった方は合わせてご覧になっていただけると幸いです。
関連記事
JDDより、共にNLP2024に参加したメンバーの記事です。ぜひ、こちらもご覧ください。
最後に
Japan Digital Design株式会社では、一緒に働いてくださる仲間を募集中です。カジュアル面談も実施しておりますので下記リンク先からお気軽にお問合せください。
この記事に関するお問い合わせはこちらにお願いします。
Japan Digital Design 株式会社
M-AIS
Kyojin Syo