
KDD 2023 参加報告①(JPMC編)

三菱UFJフィナンシャル・グループ(以下MUFG)の戦略子会社であるJapan Digital Design(以下JDD)でMUFG AI Studio(以下M-AIS)に所属する平山です。
ロサンゼルスのロングビーチで開催されたデータマイニングの国際学会「KDD 2023」に参加してきました。本記事では、3回に分けて、注目している金融や大規模言語モデル(以下LLM)の分野を中心に興味深かった発表を紹介したいと思います。
KDD 2023について
KDDは、米国のコンピュータサイエンス分野の学会であるACMのデータマイニング分野の分科会です。コロナ禍においてはオンラインで開催された年もありましたが、昨年から基本的にはオンサイト参加のみの運営に戻っています。会場では世界各地からデータサイエンティストや研究者が集まり、活発に議論が交わされます。ACMの公式YouTubeチャンネルにて公開されているハイライト動画をご覧頂くとその雰囲気の一端を感じて頂けるかもしれません。
KDDでは、理論的な研究のみならず実社会の課題解決をいかに実現するかという実用性も評価しており、企業による実務に根ざした発表も多い傾向にあります。
また、歴史あるデータ分析コンペ「KDD Cup」が開催されることでも知られており、ビッグデータという言葉が一般的になる以前から巨大なデータセットを用いた分析課題に取り組む機会を提供している学会でもあります。
2023年は、理論研究中心のResearch Trackにて313本、社会応用中心のADS Trackにて184本の論文がそれぞれ採択され、オーラルセッションおよびポスターセッションで発表されました。また今年は、招待講演、チュートリアル、ワークショップといった例年通りのプログラムに加え、LLM DayやFinance Dayなど特定分野にフォーカスしたSpecial Dayが開催されたのが特徴的でした。
J.P.Morgan Chase AI Reseachによる発表
Finance Dayを中心とした金融分野の発表で存在感を示していたのが、米国トップの銀行であるJ.P.Morgan Chase銀行(以下JPMC)のAI Reseachです。本稿では、100名以上のリサーチャーを擁するJPMC AI Researchの発表を紹介したいと思います。
Human-AI Interaction in Finance: A Learning Journey
講演者のVeloso氏は、ロボット研究の第一人者でカーネギーメロン大学の教授をされており、2018年7月からJPMC AI ReseachのHeadを務めています。Veloso氏はロボットだけで構成したチームでサッカーを行うRobo Cupにも取り組んでおられ、HPのTrailerムービーにも登場しています。そのバックグラウンドを活かして、JPMCでも、人間の「認知」「判断」「行動」といった知的活動の全ての領域を機械で再現し業務応用することに非常に意欲的に取り組んでおり、本講演ではそれらの成果が数多く共有されました。残念ながらリモートでの講演となったものの、力強い意志を感じる話し方で、非常にエネルギッシュな講演でした。

最も印象に残ったのは、「人間はスケールできないが、AIはスケールできる」という言葉でした。AI活用に取組む企業は多いと思いますが、そのほとんどは既存の技術が有効に機能する領域を見つけるためにPoCを繰り返している状況ではないでしょうか。
それに対して、AI化すべき領域を定め、必要であるならば課題を解決するための新規技術を研究開発しながらAIが担う業務を確実に拡大していく、AIの研究を多方面でパワフルに進める源泉となるJPMCの意志の明確さをこの言葉に感じました。加えて、想定している「スケール」の広がりも段違いなのではないかと想像してしまいました。
発表の中でまず注目したいのは、「Standardization」の取組みです。単語自体は直訳すると「標準化」という意味ですが、紙やWEB上にある文書や図表、フォームなど人間には解釈しやすいがAIや機械学習モデルの入力としては扱いづらい形式で存在している情報をAIや機械学習モデルに入力しやすい形式に再構築することを目指しています。
従来AIや機械学習モデルを活用するときに障害となっている事象に対してAIや機械学習モデルの技術で解決を図ろうとする動きは、Innovation Awardを受賞したLeskovec氏の講演でも触れられるなどJPMCだけでなくKDD全体でも新たな研究テーマの分野になりつつあると感じました。
特にグラフニューラルネットワーク(GNN)の技術を活用してグラフ形式のデータとして整理・解釈する研究は、急速に利用が拡大しているChatGPTなどの大規模言語モデル(LLM)への応用も期待されるなど盛り上がりを感じる分野です。
JPMCでは、請求書など紙に印刷された書類、有価証券報告書、ビジネスでやり取りされるEmail、WEBページ、X(旧Twitter)などSNS、履歴書や職務経歴書、など多岐に渡るソースから情報抽出を試みていることが共有されました。この分野の取組みについては、同じJPMCのAI ResearchでDoc AI チームのDirectorを務めるNourbakhsh氏のADS Invited Talkでもプロジェクトで直面する課題と解決に向けてのアプローチ方法が共有されていましたので、後ほど詳しく紹介したいと思います。
続いて印象的だったのは、AIや機械学習モデルの振舞いを人間に理解可能にする説明可能性(XAI)に関する研究です。
講演では、金融機関が取り組むべきXAIの提供先として、顧客、監督官庁、リスクマネージャー、トレーダーが例示されており、中でも顧客に対するXAIの考え方が印象的でした。
顧客向けのXAIの活用として2つの視点を挙げており、融資を例にすると、1つ目はなぜ融資が否決または可決なのかを説明すること、2つ目は融資が否決された場合に何を改善すれば良いか顧客がロードマップを描けるよう手助けすることです。
この2つ目の視点は、ともすればこういう情報は不正利用されかねないのではとリスクの方に意識が向いていた自分にとっては、素直に顧客目線でAI技術がどう使えるかどう使うべきかを真摯に考える姿勢が大切だという主張に目が醒める思いでした。技術的な実現法としてCounterfactual SHAP(Albini, et al. 2021)という手法がAI Researchのチームから提案されています。Counterfactual SHAPは、例えばモデルが否決の判定をした場合に、その反実仮想(Counterfactual)である可決判定を実現するためにどんな特徴量が重要かを示す指標として開発されています。

(Counterfactual Shapley Additive Explanations より)
また、発表の終盤には、人間が知識から生み出したビジネスにおけるルールをデータとそこからパターンを抽出するAIによって置き換えられるか、という問いへの挑戦について語られました。少なくともAIによって既存のルールを最適化することは可能であり、実際に896あったルールを292まで減らすことができたとのことです。
人間が担っているプロセスをAIに実行可能なものへと移行していくフレームワークとしてメモリーベースのAI-First Architectureという考え方が共有されていました。AIが十分に機能しなかったタスクについて人間がどのように解決しているのかそのルールやガイドラインなどを蓄積し人間がAIと協調することによって徐々にAIが担うタスクを増やしていくロードマップが描けるという試みです。JPMCの長期的な視野でAIに担える金融業務の拡大に着々と取り組んでいる様に感嘆の念を禁じ得ませんでした。
他にも、テキストだけの指示から図表入りのPowerPoint資料を作成するDocuBot(最初に発表されたのは2019年)などの生成系AIの取組みや、合成データの研究をデータ不足で補うだけではなくマーケットシミュレーションや人間が作成するような凝ったレイアウトのドキュメント生成にも応用している事例、画像生成技術をマーケット予測に応用する研究など、発表時間が足りなくなる程に多くの事例が共有されていました。
画像生成技術をマーケット予測に応用する研究については、同じくJPMC AI ResearchのZeng氏によるFinance Dayでの講演でより詳しく発表されていましたので、この後紹介したいと思います。
Visual Perspectives on Finance Time Series
発表者のZeng氏もロボット分野の研究をバックグラウンドに持つ方です。JPMCでは画像認識技術を応用したMondorianという市場価格の時系列データ予測モデルを開発しています。古くから、時系列データの予測には自己回帰モデル(ARモデル)というアプローチが用いられており、近年ではAmazonが開発したDeepARのようにディープラーニングを用いたARモデルも研究されています。それとは異なり、画像認識技術を使って市場の時系列データを予測することに取り組むのは、人間のトレーダー達が価格変動のチャートから得られる視覚情報を参考にして意思決定を行っている事がモチベーションとなっています。
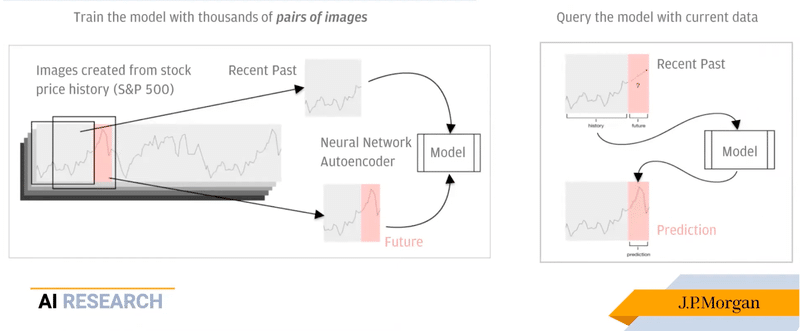
(iCubed Seminar: Visual Perspectives in Finance with J.P. Morgan より)
本講演では、マスクされた領域の画像を復元する画像修復のアプローチを用いて、過去の時系列チャートの画像データを入力としてマスクされた未来部分のチャートを「復元」することで時系列データの予測を行う手法が提案されています。画像復元モデルとしては、SN-PatchGAN(Yu, et al. ICCV 19')という手法を採用しているとのこと。
学習と検証には、2種類の人工データ、心電図データ、S&P500構成銘柄ティックデータの4種類を使用し、ベンチマークモデルとの比較を行っています。本講演で使用されているベンチマークモデルは、ランダムウォークとDeepARの2種類でした。また予測方法として、未来のデータを点で予測する方法(点予測)と、特定の領域に入る確率を予測する方法(確率予測)との2種類で精度検証を行なっています。
精度検証の結果として、まず点予測では、振り子のような調和的な周期性を持つ人工データや周期的なスパイクが見られる心電図データにおいて画像修復手法が高い精度を示し、他の2種のデータではDeepARとほぼ同等の精度であったことが示されました。そして、確率予測においては、どのデータに対しても画像修復手法が他のモデルを上回る良好な結果を示していたため、本手法は確率予測で活用することがより良いアプローチであると考えられます。
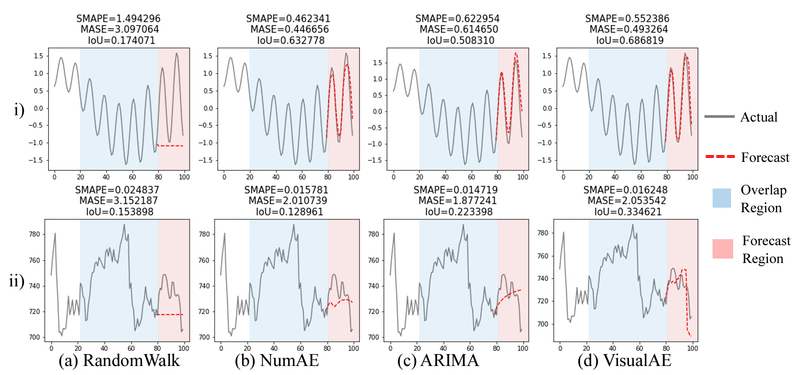
(Visual Time Series Forecasting: An Image-driven Approach より)
この研究の発展として、互いに相関を持つ複数の金融資産の価格変動を動画として扱い、動画の次のコマを生成するアプローチで複数の金融資産の将来の価格変動を同時に予測する研究も紹介されていました。
最後にJPMC AI Researchから発表されている画像情報を用いたトレーディングのための時系列予測に関する論文のリンクを纏めておきます。
Trading via Image Classification (Cohen, et al. 2019)
Visual Time Series Forecasting: An Image-driven Approach (Sood, et al. 2020)
Deep Video Prediction for Time Series Forecasting (Zeng, et al. 2021)
尚、MUFGでも拡散モデルを用いた画像生成アプローチによる時系列予測に関する論文を発表しておりますので、興味のある方は下記をご参照ください。
CSDI: Conditional Score-based Diffusion Models for Probabilistic Time Series Imputation
(Tashiro, et al. NeurIPS 2021)
Bridging the Utility Gap in DocumentAI Workflows
発表者のNourbakhsh氏は、AI ResearchのDocument AI teamに所属するDirectorです。
本講演は、Finance DayではなくKDD2023本会議のプログラムであるADS Invited Talk(応用分野の招待講演。ADS:Applied Data Science)の1つであるため、YouTubeの公式チャンネル内にて動画が公開されています。Document AIのチームが取り組んでいるのは、主に文書から情報を抽出して整理するStandardizationの領域です。
また、この分野のモデル構築に利用できる人工的な合成データ(synthetic data)の作成にも取り組んでいるようです。本公演では、AIを業務適用する際に直面するユーティリティギャップをいかに緩和するかという事について、Document AIの領域でJPMCがどのようなアプローチで研究開発を行なっているか紹介されています。
まず、そもそもユーティリティギャップとは何でしょうか。
それは、モデルがモデル開発の検証環境で示す性能と実際の運用現場で発揮する性能との差分を意味します。ユーティリティギャップを理解する例として、与えられた文章から特定の内容に該当する箇所にタグ付けするモデルの事例が紹介されています。このモデルは精度99%でタグ付けできるモデルで、すなわち100箇所タグ付けした場合に間違ってタグ付けされているのは1箇所だけという性能が検証環境でのテストで確認されています。
しかし、モデルを運用フローに組み込んだビジネスの現場から、このモデルでは50%しか業務を効率化できないとクレームが出てしまいました。
その理由は、このビジネス現場ではドキュメント単位で全てのタグ付けを正しく行う必要があり、1つのドキュメントには複数の文章が含まれています。この業務で扱う半数のドキュメントではタグ付けすべき箇所は100件未満ですが、残りの半数のドキュメントでは100箇所以上のタグ付けが必要となります。この場合、100箇所以上のタグ付けが必要となる半数のドキュメントのどこかに1箇所以上の間違ったタグ付けが含まれる事になり、業務担当者は間違ってタグ付けされた箇所を探し出し修正する必要があるのです。これが、精度99%のモデルを使用しても運用フローにおいては50%しか業務効率化できない理由です。この99%と50%のギャップがユーティリティギャップです。注意すべき点は、検証環境におけるモデル性能のテスト方法が間違っていたり不十分だったりすることが原因でユーティリティギャップが発生するわけではないということです。検証環境でのテストが正しく行われてもユーティリティギャップは発生しうるのです。

(KDD2023 - Bridging the Utility Gapより)
では、どうやってドキュメント処理の分野でユーティリティギャップを克服、もしくは緩和することができるか、本講演では次の3つのアプローチが紹介されています。
モデルの予測が当たる確率(確信度)を示して、どこが間違っていそうか判断しやすくする
人間の思考と同じアプローチでドキュメントを理解するモデルを作ることで、人間がモデルの挙動を理解しやすくなり、間違う箇所の予測もしやすくなる
運用フローでの性能と相関の高い適切なモデル性能の評価指標を設計することと、教師データを整備し増やすことで、検証環境でより良いモデルを作成できるようにする
特にJPMCで力を入れているのが2番目のアプローチで、本講演でその成果のいくつかが共有されていました。また、3番目にも積極的に取り組んでおり他の機関への提供も行っているとのことでした。
JPMCが取り組む「人間の思考と同じアプローチでドキュメントを理解する」というのは、具体的には、ドキュメントを構成するオブジェクトとそのレイアウト情報をグラフデータとして扱うことです。金融機関で扱うドキュメントは、契約書やアナリストが書くレポートや財務諸表など多岐に渡りますが、それぞれ視覚的な特徴を持っており、見た目でどんな種類のドキュメントなのか予測できるケースも多くあります。このことが、文章の内容だけでなくレイアウト情報も考慮するJPMCのアプローチの背景となっています。

(KDD2023 - Bridging the Utility Gap より)
実際にDocGraphLM(Wang, et al. 2023)の研究では、ドキュメントに書かれている文章の内容に加えて、それらの配置(方向と距離)をグラフデータとして解釈し情報抽出タスクに利用することで予測精度の向上が実現していると報告されています。また、これらの学習をサポートする人工合成データの作成も研究しておりBizGraphQA(Babkin, et al. SIGIR ’23)として公開されています。さらに、UDOP(Tang, et al. 2022)という研究では、自己教師学習の仕組みでドキュメントのレイアウト構造も含め再生成できるよう学習したモデルを活用することで情報抽出の様々なタスクの精度向上を実現する仕組みも提案されています。
ChatGPTなど大規模言語モデルの活用が注目される中、人間が解釈しやすい形式で図表なども豊富に使われて書かれている大量のドキュメントを、いかにしてLLMで扱いやすいプレーンなテキストデータに効率的に整理できるかが重要な課題となっています。Document AI teamの取り組みは、まさにこの課題にも応用できる研究であり、目先、1つのトレンドとなりそうな分野であると感じました。
まとめ
本稿では、金融分野で特に存在感の大きかったJPMC AI Researchの発表を紹介しました。金融分野のAI活用というと株価などマーケットデータの予測やローン審査の判定モデルを思い浮かべる方が多いかもしれませんが、様々な業務分野に応用できる可能性を感じて頂けたのではないでしょうか。また、技術的にも先進的なチャレンジの種が多く眠っている事に興味を持たれた方もいるのではないでしょうか。私自身も世界市場でのライバル達が日々課題解決に向けて努力と探究を重ねる姿に刺激を受けました。
関連記事
一緒に働きませんか
M-AISでは、AI技術を軸に、顧客&データ起点で金融体験をアップデートすることに挑戦してくださる仲間を募集しております。
ご興味ございましたら、ぜひ採用情報をご覧ください。
Japan Digital Design 株式会社
M-AIS
VP of Data Science
Motokiyo Hirayama