
kaggle LLM コンペ 上位解法を自分なりにまとめてみた話

本記事は、Japan Digital Design Advent Calendar 2023 の4日目の記事になります。
お久しぶりです、三菱UFJフィナンシャル・グループ(以下MUFG)の戦略子会社であるJapan Digital Design(以下JDD)でMUFG AI Studio(以下M-AIS)に所属する蕭喬仁です。
厨二心をくすぐる名前でadvent calendarに登録していますが、もう直ぐ三十路ということでアカウント名の替え時が最近の悩みです。
さて、今年はOpenAIからリリースされたChatGPTを皮切りに生成AIが世間のトレンドとなっていますが、弊社でも「文章生成AIによる過去相場要約機能」の提供のような生成AIを用いたプロダクト開発やR&Dを進めています。中でも、検索を用いて外部知識を生成AIに埋め込むことでタスクの性能を高めるRetrieval-augmented Generation (以下RAG)は、大量の業務資料やマニュアルを保持するMUFGのような大企業にとっては非常に相性の良い技術として弊社でも調査・研究を積極的に進めております。
そんな折にkaggleではLLM Science Exam というRAGがテーマになっていたコンペティションが6月から10月に開催されました。これは要チェックだと思い、私も10月中に金メダルを取られた解法を調査し社内confluenceや個人のgithubにまとめておりました。
今回の記事はその時の焼き直しですので既視感指数高めかもしれませんが、ご容赦ください。
なお、LLM Science Examの解法をまとめている先人達の資料はたくさんあります。以下に自分が知っているものを順不同で挙げておきますので、併せて参考にしてもらえればと。
目次
コンペの概要
今回のコンペティションではLLMで作成したSTEM系の選択問題をkaggle環境でどれくらい精度高く答えられるかがテーマとなっていました。
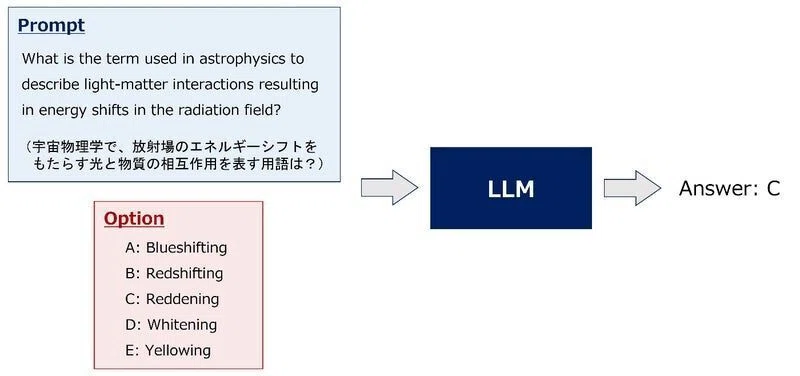
基本的なアプローチとしては問題や選択肢に関連するwikipediaのテキストデータ(context)を検索(Retrieval)し、問題文や選択肢と共にcontextもモデルに入力するRAGが採用されていました。
外部のcontextを用いないLLM単体ではモデルの精度に限界があり、いかに回答に必要なcontextをRetrieveできるかがスコアに大きく影響を与えていたようです。
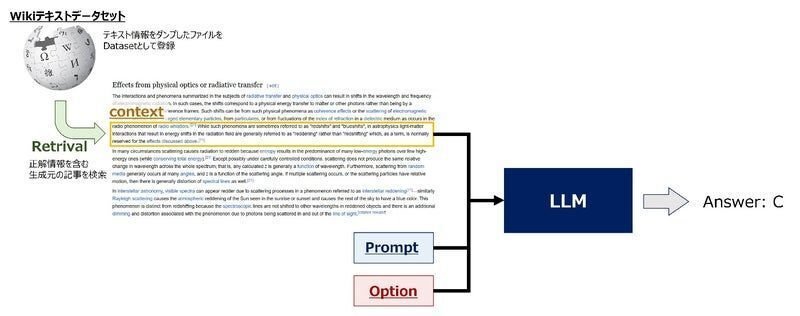
(引用: kaggle LLMコンペ 上位解法まとめ)
それでは、さっそく解法の紹介に移っていきましょう。
今回は金メダルを獲得された15チーム中、解法が共有されていた13チームの解法を元にRAGのステップごとに紹介していきます。
Retriever
Source Data
検索対象となるデータを整備するパートです。「機械学習はデータが全て」とはよく言われますが、ソースデータに無いcontextはどう検索しても引っ張ってこれないため、RAGでは特に重要なパートです。
このパートでは以下のような方法が取られていました。
データ欠損に気をつけた独自のparse方法
欠損の少ない外部データの利用
複数のソースデータからRetrieveした出力を最後にensembleする
テキストデータのchunk方法
LLMには入出力のトークンに制限があることが多いため、モデルに入るサイズにテキストを小さいまとまり(以下chunk)に分割する必要があります。
このパートでは以下のような方法が取られていました。
token単位
「N個のtoken単位で分割する方法」や「分割時にM個のtokenはoverlapさせる方法」などがありました。
文章単位
「1文ずつ分割する方法」や「N文ずつ分割する方法」、「N文ずつ分割する際にM文はoverlapさせる方法」、また「分割単位はN個のtokenだがoverlapはM文ずつ行う方法」などがありました
sectionごとに分割
「wikipediaの文章の章立てや段落ごとに分ける方法」や「N個のtokenになるようにsectionを再度分割する方法」などがありました
Dense Retriever
検索対象のテキストや検索文言をベクトル化して検索するパートです。どのモデルを用いて文章をベクトル化するかが焦点となりますが、Massive Text Embedding Benchmark (MTEB) Leaderboard というベクトル化性能を測るベンチマークを元に選択されていたようです。
以下に具体的に利用されたモデルを列挙していますが、ランキングは常に変化するので、その時々にあったもの選び実験するのが良さそうです。
e5-small-v2, e5-base-v2, e5-large-v2, gte-small , gte-base, gte-large , bge-small , bge-sbase , bge-large, all-MiniLM-L6-v2, bge-small-en, bge-small-en, bge-small-en-v1.5, bge-small-en-v1.5, bge-large-en, bge-base-en-v1.5, msmarco-bert-base-dot-v5, all-mpnet-base-v2, multilingual-e5-small, instructor-xl
Dense Retrieverのfine tuning
DenseRetrieverについては事前学習済みモデルをそのまま利用していたチームが多かったですが、中にはモデルのfine tuningを実施していたチームもありました。方法としては以下の通りです。
wikipediaからサンプリングしたcontextから問題文と選択肢をLLM(ChatGPT3.5やChatGPT4、Llama-v2-70B等)で生成したデータを用いた教師あり学習
負例の選出方法としては「contextからランダムにサンプリングする方法」や「対象contextと同じページ内の文章からサンプリングする方法」が用いられていました
chunkに分けたwikipediaの文章をSimCSEにかけて学習
負例の選出方法としては「SimCSEを複数回行うことで1つ前のstepで学習したモデルが類似文章とみなしたものを使用する方法」がありました
Sparse Retriever
単語などのキーワードをベースに文章検索する方法です。キーワード化しづらい画像や音声などにも対応可能なベクトル検索が業界的にはトレンドになっていますが、文書検索においてはまだまだ現役です。
今回のコンペでは以下のような方法が用いられていました。
TF-IDF
「スペース区切りの単語を元にn-gramで行う方法」が主流でしたが、「BERT Tokenizerの語彙を利用する方法」もみられました
pyseriniで実装されているLuceneSearcher (BM25ベース)
ElasticSearchを用いたキーワード検索
ElasticSearchをkaggle環境上で安定的な速度で使用するためにはかなりの工夫が必要だったことが、先日のkaggle tokyo meetupに詳説されていました。
chunk/query作成時の工夫
Retrieverモデルで検索する際、context(wikiテキストのchunk)やquery(問題文や選択肢の方)の文章をそのまま使うのではなく、何らかの加工を行うことで検索性能を向上させる方法が模索されていました。
context側に対しては以下のような方法が取られていました。
{記事タイトル} + {chunk}
{記事タイトル} + {section タイトル} + {chunk}
特別なテンプレート文章をcontextの前につける
query側に対しては以下のような方法が取られていました。
問題文だけ: {問題文}
問題文と選択肢を全て繋げたもの: {問題文} {選択肢A}, {選択肢B}, {選択肢C}, {選択肢D}, {選択肢E}
問題文と選択肢を個別に繋げたもの: {問題文} {選択肢A}, {問題文} {選択肢B}, … {問題文} {選択肢E}
特別なテンプレート文章をcontextの前につける
例: Represent this sentence for searching relevant passages:
その他の工夫
その他、個人的に面白かった工夫がこちらです。
検索はchunkごとに実施するがモデルに入力するcontextは抽出したchunkの前後まで用いる
記事検索を行った後に記事からのcontext検索を実施する
「記事検索にはdense retrieverで実施しcontext検索はsparse retrieverで行う方法」や「記事検索にはタイトルや記事中の全chunkのベクトルの平均を利用しcontext検索は各chunkのベクトルを利用する方法」などが見られました
sparse retrieverでcontextを検索する際はdense retrieverよりも多めに候補を抽出する
Reranker
Retrieverによって取得したcontextをより適切なものだけに絞り込むためのスコアリングを行う方法です。ベクトル検索で取得したcontextは問題文や選択肢と意味的に類似しているものの、回答には役に立たない場合もあるためこのような処理を挟む場合があります。
以下のようなモデルが利用されていました。
deberta-v3-base, re2g-reranker-nq, LGBMRanker, TF-IDF, BM25,
このうち最後の2者はsparse retrieverを再度かけているとも解釈できそうです。
Rerankerの推論方法としては query と contextを結合した文章encodeした後に、「正解contextかどうかを判定する2値分類形式」と「複数のcontextの中から正解contextを選ぶMultipleChoice形式」が見られました。
また、re2g-reranker-nqのような事前学習済みモデルを利用する場合は不要ですが、deberta-v3-baseやLGBMRankerを用いていたチームは以下のような方法で学習用の教師データを作成していました。
ChatGPTで作成したQAデータ
deberta-v3-largeによるpseudo-ranks
こちらは2位の方の解法で用いられていた手法ですが投稿されたsolutionだけでは真意が図れませんでした
Generator
追加学習データの作成
提供されていた学習データの件数が200件と少量だったため、全てのチームがLLMで生成した追加学習データを利用していました。
追加学習データの作成方法としては以下が用いられていました。
ChatGPT(3.5または4)を用いて作成する方法
プロンプトの例としてはSUGUPOKOさんが使われたものや5th place solutionで使われたものが参考になります
QAデータ作成用に学習されたモデルを使用する方法
具体的にはt5-large-generation-race-QuestionAnswer, t5-large-generation-race-Distractorが利用されていました
利用されたモデル
選択問題を解くモデルとして利用されていたものとしては以下がありました。
MLM系
deberta-v3-large, reward-model-deberta-v3-large-v2, deberta-v3-large-squad2
LLM系
Llama-2-7b, Llama-2-13b, Llama-2-70b-hf, Mistral-7B-v0.1, mistral-7b-instruct-v0-1-4g, xgen-7b-8k-base, Xwin-LM-70B-V0.1, Platypus2-70B-instruct
LLMを使う解法が大半を占めているのかと思いましたが、実際は実行環境や制限の関係でdeberta-v3-largeをベースに、難しい問題に対してだけLLMを利用するという方法が多く取られていました。
また、kaggleの実行環境上で巨大なLLMをどう利用するかも困難なポイントだったようです。
推論形式
文章でかかれた選択問題をどのように解くか、についてもさまざまなバリエーションが見られました。
contextと問題文選択肢ごとにencodeした後に分類問題を解くMultipleChoice形式
選択肢を全て見せた後にspanごとに特徴抽出して分類問題を解くSpanClassification形式
選択肢を全て見せた後のA~Eのtokenが出る確率を利用する形式
選択肢ごとにyes or no を出力する確率を利用する形式
yesとnoの確率差を利用している派生系を利用しているチームも存在しました
選択肢ごとにencodeして2値分類する形式
他の選択肢の情報も考慮していた2値分類を実現するために、他選択肢のencode結果の平均を追加して予測するという派生系もありました
MultipleChoice形式とSpanClassification形式に馴染みのない方は、以下のイメージ図が参考になります。

(引用: Improving Language Understanding by Generative Pre-Training)

あくまでイメージで、図は別のコンペティションで用いられたものです。
(引用: DIscussion: 3rd Place Solution - Span MLM + T5 Augmentations)
学習に関する工夫
Generatorの学習時に用いられていたテクニックとしては以下のようなものがありました。
正解のcontextのみを用いて学習すると過学習するため、不正解contextも含めて学習を行う
AutoModelForSequenceClassification がサポートされていないモデルに対して、trl の RewardTrainerを用いてfine tuningを実施する
事前学習時に用いたprompt形式にできるだけ合わせる
入力トークン数は大きめが良く512→768→1280に増やすことで性能が向上した
推論に関する工夫
学習したモデルを推論させる際にも興味深いテクニックがいくつか用いられていました。
学習時よりも多めのcontextを推論時に用いる
たとえば、256 tokenで学習していたものを 768 tokenまで大きくしてもうまく動作しかつ予測性能が上がったようです。
layerごとに推論することで小リソースマシンでLLMの推論を行う
xformersのmemory_efficient_attentionを用いてGPU消費量を抑制する
max_new_tokens=1にして余計なtokenを生成しない
モデルに入力するcontextを変えるTest-Time Augmentation(以下TTA)の実施
選択肢の順番をかえるTTAの実施
全組み合わせを入れた文章を一回だけ読ませた後でattention maskを切り替えることでTTAを効率化する方法も取られていました。
最後に
今回はkaggle LLMコンペで用いられていた上位解法についてまとめてみました。
仕事の役に立つかどうかで界隈を定期的に騒がせているkaggleですが、こと弊社M-AISにおいてはプロジェクトを進める際、プロジェクトの要件定義や顧客コミュニケーションを主導するロールと実際のデータ分析業務を主導するロールが分かれて案件を進めていくため、比較的kaggleが役に立ちやすい環境なのではという印象です。
そんなM-AISに興味を持っていただいた方はぜひカジュアル面談でお話しできると嬉しいです!
最後までお読みいただき、ありがとうございました。
Japan Digital Design株式会社では、一緒に働いてくださる仲間を募集中です。カジュアル面談も実施しておりますので下記リンク先からお気軽にお問合せください。
この記事に関するお問い合わせはこちらからお願いします。
M-AIS
Kyojin Syo