
AWS Step FunctionsでMapを使ってみよう

はじめに
本記事は、Japan Digital Design Advent Calendar 2023 の15日目の記事になります。
三菱UFJフィナンシャル・グループ(以下MUFG)の戦略子会社であるJapan Digital Design(以下JDD)でシステム開発を担当している小笠原啓です。
下記ではデータの収集と加工でよくあるワークフローをAWS Step Functions(以降ではStep Functionsと記載)で実現する方法をご紹介します。
Step Functions は複数のサービスを組み合わせて処理の流れを制御、実行するための serverless orchestration serviceです。
今回はStep FunctionsからAWS Lambda(以降ではLambdaと記載)を呼び出して、大量のデータを並列で処理するバッチ処理を構築します。
実際の業務でも利用頻度が高いワークフローだと思いますので、Step Functionsを構築する際の参考にしていただける内容であると思っています。
実現したいこと(ワークフローの概要)
Step Functionsをもちいると、Lambdaや Amazon ECSのタスク、Amazon EventBridge(以降ではEventBridgeと記載)と共にもちいることで手軽に堅牢なEvent駆動型のアプリケーションを構築できます。
今回は下記のようなワークフローをStep FunctionsとLambdaを用いて構築します。
特定の時間にAPIを利用してデータを取得し、任意のS3のBucketに保存する。なお保存されるファイルの数は数百以上になる
上記のファイルを1つ1つ加工(たとえばJSONをCSVに変換)し、任意のS3のBucketに保存する
上記の処理で加工されたファイルから複数のファイルを読み込み、新たなデータを生成して任意のS3のBucketに保存する
このような処理は分析業務で利用するデータを準備する処理として一般的なものではないかと思います。
Step Functionsから呼び出すのはすべてLambdaです。整理すると下記のようなものになるでしょう。

さらにStep Functionsを通じて上流から下流の処理に値(情報)を渡すことができます。
たとえばprocessDataは前段の処理のretrieveDataが作成したファイル名やファイルが保存されたS3のBucket名を知っている必要があります。
こうした情報を Step FunctionsではInputやOutput 、Parametersというプロパティを利用して渡すことができます。
今回の処理では下記のような情報を渡します。

下記では上記のLambdaをどのように呼び出すか Step Functions の state machine を示しつつ、その内容を説明します。
state machineの全体像
Step Functions で定義するワークフローはstate machineと呼ばれ、その中で定義される各処理はstate と呼ばれます。
下記の図の全体が state machineです。stateは角丸の長方形で示されています。
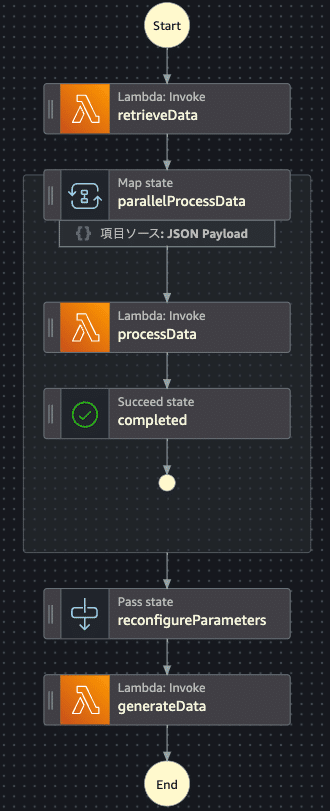
state machineはAWSコンソールにあるエディターを使って作成、編集できます。
またエディターで作成したstate machineはJSONでも出力できます。下記はJSONで出力した内容の一部を編集したものです。(下記をAWSコンソールのエディターで取り込むとLambdaが存在しないためエラーが発生します)
{
"StartAt": "retrieveData",
"States": {
"retrieveData": {
"Type": "Task",
"Parameters": {
"api_client_id.$": "$.apiClientId"
},
"Resource": "arn:aws:lambda:YOUR_REGION:YOUR_AWS_ACCOUNT:function:retrieveData",
"ResultPath": "$.retrieveDataResult",
"Retry": [
{
"ErrorEquals": [
"States.ALL"
]
}
],
"Next": "parallelProcessData"
},
"parallelProcessData": {
"Type": "Map",
"MaxConcurrency": 5,
"ItemsPath": "$.retrieveDataResult.storeInfo",
"ItemProcessor": {
"ProcessorConfig": {
"Mode": "INLINE"
},
"StartAt": "processData",
"States": {
"processData": {
"Type": "Task",
"Parameters": {
"sourceBucketName.$": "$.bucketName",
"targetFiles.$": "$.files"
},
"Resource": "arn:aws:lambda:YOUR_REGION:YOUR_AWS_ACCOUNT:function:processData",
"ResultPath": "$.processDataResult",
"Retry": [
{
"ErrorEquals": [
"States.ALL"
]
}
],
"Next": "completed"
},
"completed": {
"Type": "Succeed"
}
}
},
"Next": "reconfigureParameters"
},
"reconfigureParameters": {
"Type": "Pass",
"Parameters": {
"storeBucketName.$": "$[0].processDataResult.storeBucketName",
"targetFileNames": [
"fileNameA",
"fileNameB",
"fileNameC",
"fileNameD"
]
},
"Next": "generateData"
},
"generateData": {
"Type": "Task",
"Parameters": {
"sourceS3Bucket.$": "$.sourceS3Bucket",
"targetFileNames": "$.targetFileNames"
},
"Resource": "arn:aws:lambda:YOUR_REGION:YOUR_AWS_ACCOUNT:function:processData",
"Retry": [
{
"ErrorEquals": [
"States.ALL"
]
}
],
"End": true
}
}
}state machine 全体の定義について簡単に解説します。
StartAt はワークフローがどのstate から開始するを指定します。上記では retrieveData からワークフローが開始されます。
実行内容は States の中で定義します。
今回は retrieveData 、 parallelProcessData 、 reconfigureParameters、 generateData というstateを定義しています。下記ではそれぞれのstateの内容を少し詳しく見ていきます。
EventBridgeを使って state machine を起動する
retrieveDataの定義について説明をします。
"retrieveData": {
"Type": "Task",
"Parameters": {
"api_client_id.$": "$.apiClientId"
},
"Resource": "arn:aws:lambda:YOUR_REGION:YOUR_AWS_ACCOUNT:function:retrieveData",
"ResultPath": "$.retrieveDataResult",
"Retry": [
{
"ErrorEquals": [
"States.ALL"
]
}
],
"Next": "parallelProcessData"
},まず Type を Task と定義しています。
Taskは何らか処理、たとえばLambdaを呼び出したりECSのタスクを呼び出したりするstateであることを表します。今回は Resource に指定したLambdaを呼び出します。
次にParameters です。
今回の state machine はEventBridgeのルールで特定の時間で起動する想定です。そしてEventBridgeのルールは state machine に値を渡せます。
上記の Parameters では、EventBridgeから渡された想定でapiClientId のvalueを受け取っています。
この値はResource で定義しているLambdaから参照できます。例えばpythonで書かれたLambdaであれば下記のように参照します。
def lambda_handler(event, context):
key1 = event["api_client_id"]Retry はLambdaの処理がエラーになった際に再実行する条件を指定しています。上記では States.ALLであればRetryを行うと定義しています。
ALLはいずれの種類のエラーであってもRetryを行う設定です。
retrieveData はAPIを叩いてデータを取得、それをS3に保存する処理です。
APIとの接続時にネットワークエラーになったり、取得したデータに想定外の値が入っていてデータの整形などの処理に失敗したりといったランタイムエラーがLambdaの処理では発生しえます。
こうしたエラーが発生した際にはこのRetryに設定した条件に従ってstateの処理を再実行します。
なおStatesにはALLのほかに States.DataLimitExceeded など詳細なエラー内容を指定できます。実際に構築する際は目的にあわせてStatesを設定してください。また指定できる値は公式のドキュメントをご覧ください。
Next にはこの処理が正常に完了した場合に実行するStateを指定します。
ここでは retrieveData の完了後 parallelProcessData を実行するという設定をしています。
parallelProcessDataで並列処理を定義
大量のデータを加工、保存する処理には長い時間がかかります。とくにファイルを1つずつ処理するとファイルの数だけ処理時間が伸びてしまいます。
Lambdaの実行時間は15分という上限があるため、1回の実行ですべてのファイルが処理しきれない場合もあります。
こうした場合Lambdaの処理を並列化して実行することを検討します。そして並列処理を管理、実行する仕組みがStep FunctionsのMapというTypeです。
今回は parallelProcessData をMapとして定義し、またMapの中で実行されるTaskとして processDataと complete をそれぞれ定義しました。
"parallelProcessData": {
"Type": "Map",
"MaxConcurrency": 5,
"ItemsPath": "$.retrieveDataResult.storeInfo",
"ItemProcessor": {
"ProcessorConfig": {
"Mode": "INLINE"
},
"StartAt": "processData",
"States": {
"processData": {
"Type": "Task",
"Parameters": {
"sourceBucketName.$": "$.bucketName",
"targetFiles.$": "$.files"
},
"Resource": "arn:aws:lambda:YOUR_REGION:YOUR_AWS_ACCOUNT:function:processData",
"ResultPath": "$.processDataResult",
"Retry": [
{
"ErrorEquals": [
"States.ALL"
]
}
],
"Next": "completed"
},
"completed": {
"Type": "Succeed"
}
}
},
"Next": "reconfigureParameters"
},まずはMapで定義している要素を抜き出して示します。
Type は Map を設定
MaxConcurrency は 5(並列)と設定
ItemsPath に $.retrieveDataResult.storeInfoを設定
Mode は INLINE と設定
ItemProcessor には並列に実行するワークフローを定義
Next に stateの reconfigureParameters を設定
これら設定について詳細に見てきます。
MaxConcurrency は並列実行数の上限を示します。
1回の実行にかかる時間、必要な実行回数、そして合計の実行時間を勘案して、必要な数値を設定します。
なお設定可能な値は Mode によって変化します。今回利用している INLINE では40(並列)が上限です。
これ以上の並列数で実行したい場合は DISTRIBUTEDというModeを利用します。詳細なDISTRIBUTEDの設定方法はこちらを参考にしてください。
またItemsPath、そしてItemProcessorの中の Parametersでは上流の処理retrieveDataのstateから値を受け取っています。
まずはItemsPathについて見てみましょう。ItemsPathではretriveDataの処理結果を受け取っています。
今回は下記のような retrieveDataが保存したファイル名と保存先のS3のBucket名のオブジェクトの配列が入っていることを想定しています。ItemsPathに渡された配列のオブジェクトの数だけItemProcessorのワークフローが実行されます。
[
{
bucketName: "bucketA",
files: ["file1","file2"]
},
{
bucketName: "bucketB",
files: ["file3","file4"]
},
]ItemProcessor についても詳しく見てみます。
"ItemProcessor": {
"ProcessorConfig": {
"Mode": "INLINE"
},
"StartAt": "processData",
"States": {
"processData": {
"Type": "Task",
"Parameters": {
"sourceBucketName.$": "$.bucketName",
"targetFiles.$": "$.files"
},
"Resource": "arn:aws:lambda:YOUR_REGION:YOUR_AWS_ACCOUNT:function:processData",
"ResultPath": "$.processDataResult",
"Retry": [
{
"ErrorEquals": [
"States.ALL"
]
}
],
"Next": "completed"
},
"completed": {
"Type": "Succeed"
}
}
},ItemProcessor には並列実行するワークフローを定義します。
ItemsPath に定義した各オブジェクトから$.bucketNameと$.fileを読み込み、設定しています。これにより渡した値を Resource に定義したLambdaから参照することができます。
なお少し長い余談になりますが、このResourceにはLambda以外も指定できます。
たとえば arn:aws:states:::states:startExecution.sync:2 という指定ができます。
この設定では別のStep Functionsの state machineを呼び出し、呼び出した stae machine が完了するまで呼び出し元の処理は待機、呼び出した state machine の処理結果をJSONで受け取るという動作になります。
states:startExecution はStep FunctionsのStartExecutionというAPIをコールすること、 .syncは 子のstate machine( 呼び出した state machine)がすべて完了するまで、呼び出し元の state machine が待機すること、 :2 は処理のレスポンスが JSON であることをそれぞれ意味します。
このように別の state machine を呼び出せば複雑なワークフローも実現できます。
processData で呼び出したLambdaがエラーなく完了すると complete というstateが呼び出されます。
complete のTypeは Succeed に設定しています。
Succeedは正常にワークフローが完了したことを示すものです。
今回は設定をしていませんが、ScucceedはChoice や Fail という Typeと組み合わせると、エラー時のワークフローなども state machine 上で実現できます。
reconfigureParametersでparameterを再定義
今回の定義では generateData の前に reconfigureParameters というStateを呼び出しています。
このstateの目的は generateData に渡す parameter の内容を編集することです。
"reconfigureParameters": {
"Type": "Pass",
"Parameters": {
"storeBucketName.$": "$[0].processDataResult.storeBucketName",
"targetFileNames": [
"fileNameA",
"fileNameB",
"fileNameC",
"fileNameD"
]
},
"Next": "generateData"
},stateのTypeは Pass を指定しています。
Pass には複数の用途がありますが、このように後続のStateに渡すparameterを編集することもその1つです。
今回は2つの方法で parameter を編集しています。
1つはprocessDataで出力された値を利用する方法、もう1つは全く新しい値を設定する方法です。
前者は $[0].processDataResult.storeBucketName というJSONPathを指定して値を取得しています。
これはprocessDataで加工したファイルが保存されたS3のBucket名を取得するという処理を想定したものです。
Mapの出力は処理を実行した回数分生成され、下記のような配列として reconfigureParameters にinputされてきます。
[
{
"processResult": {
storeBucketName: "processedDatabucket",
....
},
},
{
"processResult": {
storeBucketName: "processedDatabucket",
....
},
}
]Mapで実行する processDataのファイルの保存先となるBucketは同じ想定のため、いずれの処理結果に含まれる storeBucketName を参照しても値は変わりません。
このため $[0]と配列の先頭を指定して、 storeBucketNameの値を取得しています。
後者の方法では単純にJSONを定義するような方法で定義したオブジェクトの値を設定しています。
今回はtargetFileNames として後段のgenerateDataでデータを生成するためにどのファイルを利用するかを示すファイル名を受け取っています。
このように前段のstateの処理結果を受け取りつつ、更に必要な値を外部から与えることもできます。
すべてのファイルの処理後にgenerateDataを実行する
この generateData で処理対象としているのはretrieveDataが取得する複数のファイルです。さらにそれらのファイルが processData による処理が行われた最新のデータである必要があります。
このような「複数のファイルに対する処理がすべてが終わったら generateData を実行する」という条件付きの処理もStep Functionsで簡単に定義できます。
これについてはフロー図を見たほうがわかりやすいと思いますので、再掲します。
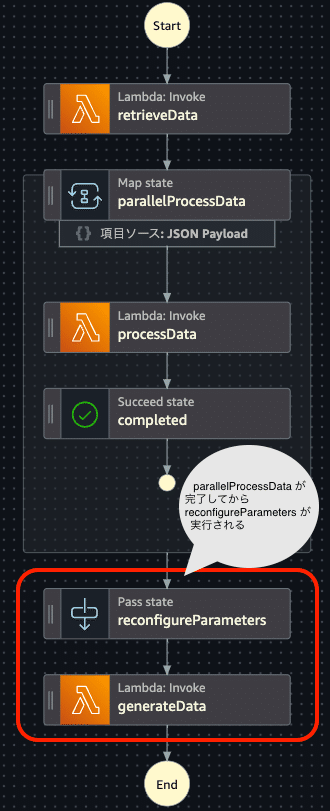
state machineは parallelProcessData の処理が完了した後に、reconfigureParameters とそれに次いで generateDataが順番に呼びされるように定義しています。
これにより processDataのすべての処理が正常に終了する前提でgenerateDataは処理を実行できます。
まとめ
AWS Step Functions で Mapを使ってみよう、というタイトルでよくありそうな構成を state machine で構築する方法とその定義を解説しました。
はじめてStep Functionsを利用される方の参考になればうれしいです。
最後までご覧いただきありがとうございました。
Japan Digital Design株式会社では、一緒に働いてくださる仲間を募集中です。カジュアル面談も実施しておりますので下記リンク先からお気軽にお問合せください。
この記事に関するお問い合わせはこちら
Technology & Development Div.
小笠原 啓