
LangChainをベースにしたRAGアプリケーションのプロトタイプを素早く作る方法

LangChainをベースにしたRAGアプリケーションのプロトタイプを素早く作る方法
スマートなチャットボットの作成には、かつては数ヶ月のコーディングが必要でした。
LangChainのようなフレームワークは確かに開発を効率化していますが、プログラマーでない人々にとっては、それでも何百行ものコードは障壁となることがあります。
シンプルな方法を求めて、私は「Lang Flow」というオープンソースのパッケージを発見しました。これはLangChainのPythonバージョンをベースにしており、一行もコードを書かずにAIアプリケーションを作成することができます。あなたにはキャンバスが提供され、そこでコンポーネントをドラッグしてつなげるだけで、あなたのチャットボットを作成することができます。
この記事では、LangFlowを使用して、数分でスマートなAIチャットボットのプロトタイプを作成します。バックエンドには、埋め込みモデルと大規模言語モデルのためのOllamaを使用し、アプリケーションはローカルで無料で動作します!最後に、このフローを最小限のコーディングでStreamlitアプリケーションに変換します。
Retrieval-Augmented Generationパイプライン、LangChain、LangFlow、Ollamaの紹介
このプロジェクトでは、AIチャットボットを作成し、「Dinnerly - あなたの健康的な料理プランナー」と名付けます。このチャットボットは、Retrieval Augmented Generation (RAG)の助けを借りて、レシピのPDFファイルから健康的な料理のレシピを推奨することを目指しています。
それをどのように実現するかについて詳しく説明する前に、プロジェクトで使用する主なコンポーネントについて簡単に説明します。
Retrieval-Augmented Generation (RAG)
RAG(Retrieval-Augmented Generation)は、外部ソースからの関連情報を提供することでLarge Language Models(LLMs)を支援します。これにより、LLMsはこのコンテキストを考慮してレスポンスを生成することが可能となり、より正確で最新の情報を提供できます。
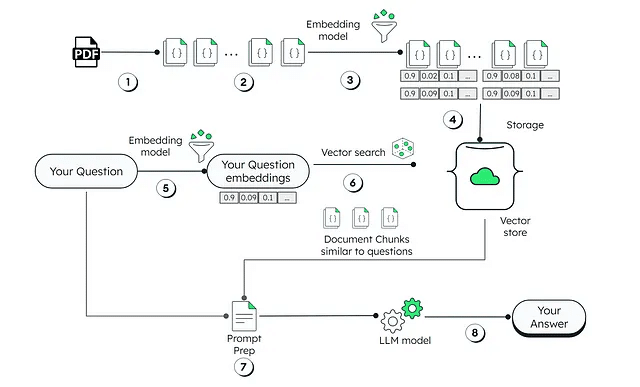
RAGパイプラインには通常、次のステップが含まれます。これは、Retrieval Augmented Generationへのガイドで説明されています。
“
ドキュメントのロード: ドキュメントまたはデータソースをロードから始めます。
分割: ドキュメントを管理しやすい部分に分割します。
埋め込みの作成: これらのチャンクを埋め込みを使用してベクター表現に変換します。
ベクターデータベースへの保存: これらのベクターを効率的な検索のためのデーキャッシュに保存します。
ユーザーとのインタラクション: ユーザーからのクエリや入力を受け取り、それらを埋め込みに変換します。
VectorDBでのセマンティック検索: ユーザーのクエリに基づいてセマンティック検索を行うためにベクターデータベースに接続します。
レスポンスの取得と処理: 関連するレスポンスを取得し、それらをLLMを通じて処理し、答えを生成します。
ユーザーへの回答の提供: LLMによって生成された最終的な出力をユーザーに提供します。
Langchain
LLMを中心に構築されたオープンソースのフレームワークであるLangChainは、チャットボット、要約など、さまざまなGenAIアプリケーションの設計と開発を容易にします。
このライブラリの中心的なアイデアは、複雑なAIタスクを単純化し、LLMを中心に更に高度なユースケースを作り出すために、異なるコンポーネントを"連鎖"させることです。

LangFlow
LangFlowは、LangChain専用に設計されたウェブツールです。これは、ユーザーがコンポーネントをドラッグアンドドロップするだけで、コーディングなしでLangChainアプリケーションを構築してテストすることができるユーザーインターフェースを提供します。
しかし、まず最初に、LangFlowを使用してAIアプリケーションフローを設計するためには、LangChainの動作とその異なるコンポーネントについて基本的な理解が必要です。
Ollama
Ollamaは、私にとっては、オープンソースLLMをすぐに使い始める最良であり、最も簡単な方法です。それは、他の中でも最も優れたLLM、例えばLlama 2やMistralをサポートしており、利用可能なモデルのリストはollama.ai/libraryで見つけることができます。
Ollamaの設定
Ollamaのインストール
まず、Ollamaのダウンロードページにアクセスし、お使いのオペレーティングシステムに対応したバージョンを選択し、ダウンロードしてインストールします。
Ollamaをインストールしたら、コマンドターミナルを開いて以下のコマンドを入力します。これらのコマンドはモデルをダウンロードし、ローカルのマシンで実行します。
このプロジェクトでは、Llama2を大規模言語モデル(LLM)として使用し、“nomic-embed-text”を埋め込みモデルとして使用します。 “Nomic-embed-text”は、大きなコンテキストウィンドウを持つ強力なオープンソースの埋め込みモデルです。これにより、クラウドサービスを必要とせずに、アプリケーション全体をローカルで実行することができます!
ollama serve
ollama pull llama2
ollama pull nomic-embed-text
ollama run llama2LangFlowの設定
前提条件
LangFlowを始める前に、Pythonがコンピュータにインストールされていることを確認することが重要です。Pythonのバージョンは3.9以上、しかし3.12より古いものであるべきです。
LangFlowのインストール
次に、LangFlowのインストールに進みましょう。これを仮想環境内で行うことをお勧めします。このアプローチは、依存関係をその独自のスペース内できちんと管理するのに役立ちます。私のMacでは、Condaを使って設定を行います。コマンドラインのターミナルで以下のコマンドを入力し、Python 3.11を搭載した“langflow”という名前の仮想環境を作成します。
conda create -n langflow python=3.11
conda activate langflow
pip install langflowもしCondaを持っていない場合は、以下のコマンドを用いてPythonで直接仮想環境を設定することもできます。
python -m venv langflow
source langflow/bin/activate
pip install langflowインストールが完了したら、ターミナルに "langflow run" を入力するだけでLangFlowを開始することができます。
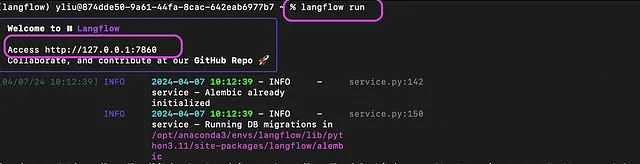
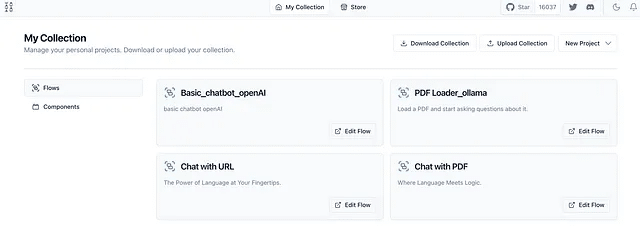
次に、それが提供するURL(上記の例では、http://127.0.0.1: 7860)を取り、ウェブブラウザに貼り付けて、これが表示されるはずです。このページはすべてのプロジェクトを表示します。
チャットボットのフローを設計する
次のステップは、最初のフローを作成することです。
まず、「新規プロジェクト」をクリックして、自分だけの空白のキャンバスを開きます。左側のペインでは、ワークスペースにドラッグアンドドロップできるさまざまなコンポーネントが用意されていることに気づくでしょう。

このプロジェクトでは、PDFファイルからの質問に答えることができるチャットボットを作成しています。以前に話したRAGパイプラインを覚えていますか?これを組み立てるためには、以下の要素が必要になります:
PDFローダー:ここでは「PyPDFLoader」を使用します。PDFドキュメントのファイルパスを入力する必要があります。
テキストスプリッター:「RecursiveCharacterTextSplitter」を選択し、デフォルトの設定を使用します。
テキスト埋め込みモデル:無料のオープンソースの埋め込みを利用するために、「OllamaEmbeddings」を選択します。
ベクトルデータベース:埋め込みを保存し、ベクトル検索を容易にするために、「FAISS」を選択します。
レスポンス生成のためのLLM:「ChatOllama」を選択し、モデルを「llama2」に指定します。
会話メモリ:これにより、チャットボットはチャット履歴を保持し、フォローアップの質問に役立ちます。ここでは「ConversationBufferMemory」を使用します。
会話検索チェーン:これは、LLM、メモリ、検索されたテキストなどのさまざまなコンポーネントを接続し、レスポンスを生成します。「ConversationRetrievalChain」を選択します。
これらすべてのコンポーネントをキャンバスにドラッグアンドドロップし、PDFファイルのパスやLLMモデル名など、必要なフィールドを設定します。他の設定はデフォルトのままにしておいても大丈夫です。
次に、これらのコンポーネントを接続してフローを形成します。

すべてが接続されたら、右下の「ライトニング」ボタンを押してフローをコンパイルします。すべてが順調に進むと、ボタンは緑色に変わり、成功を示します。
フローのコンパイルに成功した後は、「チャットボット」アイコンをクリックして作成したものをテストしてみてください。

いくつかのヒント:
フローが完了したら、JSONファイルとして保存するか、「マイコレクション」の下で将来のアクセスや編集のために見つけることができます。
事前に作成された例を使用してLangFlowにダイブすると、素晴らしいインスピレーションが得られ、始めるのに役立ちます。 以下の方法:
「LangFlowストア」には例がありますが、アクセスにはAPIキーが必要です。
LangFlow GitHub ページでは、例をダウンロードし、「アップロード」ボタンを使用してLangFlow UIにアップロードすることができます。
ローカルでの設定が得意でない場合でも、OpenAIを選択してRAGパイプラインを構築することができます。設定のためにOpenAI APIキーを持っていることを確認してください。
フローをStreamlitチャットボットに変換
さて、フローがちょうどよく設定されていれば、アプリケーションに統合する時が来ました。 フローを構築した後、LangFlowは必要なコードスニペットを提供することで簡単にします。サイドバーにある「コード」ボタンを押すだけです。

このフローをStreamlitチャットボットに統合しましょう。
依存関係の設定:
まず、依存関係をインストールする必要があります。
pip install streamlit
pip install langflow
pip install langchain-communityLang Flowコードスニペットの取得:
import requests
from typing import Optional
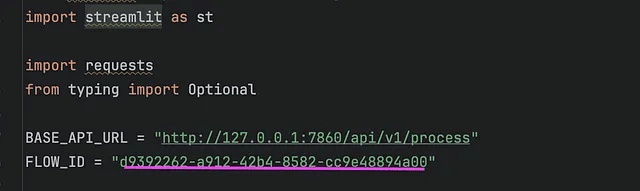
BASE_API_URL = "http://127.0.0.1:7860/api/v1/process"
FLOW_ID = "d9392262-a912-42b4-8582-cc9e48894a00"
# You can tweak the flow by adding a tweaks dictionary
# e.g {"OpenAI-XXXXX": {"model_name": "gpt-4"}}
TWEAKS = {
"VectorStoreAgent-brRPx": {},
"VectorStoreInfo-BS24v": {},
"OpenAIEmbeddings-lnfRZ": {},
"RecursiveCharacterTextSplitter-bErPe": {},
"WebBaseLoader-HLOqm": {},
"ChatOpenAI-aQOv0": {},
"FAISS-o0WIf": {}
}
def run_flow(inputs: dict, flow_id: str, tweaks: Optional[dict] = None) -> dict:
"""
Run a flow with a given message and optional tweaks.
:param message: The message to send to the flow
:param flow_id: The ID of the flow to run
:param tweaks: Optional tweaks to customize the flow
:return: The JSON response from the flow
"""
api_url = f"{BASE_API_URL}/{flow_id}"
payload = {"inputs": inputs}
headers = None
if tweaks:
payload["tweaks"] = tweaks
response = requests.post(api_url, json=payload, headers=headers)
return response.json()3. チャット機能の構築:
同じpythonファイルで、チャット専用の関数を定義します。この関数は、ユーザーからの新しいクエリごとにフローを実行してレスポンスを取得し、このレスポンスをインターフェースにストリーミングします。
def chat(prompt: str):
with current_chat_message:
# Block input to prevent sending messages whilst AI is responding
st.session_state.disabled = True
# Add user message to chat history
st.session_state.messages.append(("human", prompt))
# Display user message in chat message container
with st.chat_message("human"):
st.markdown(prompt)
# Display assistant response in chat message container
with st.chat_message("ai"):
# Get complete chat history, including latest question as last message
history = "\n".join(
[f"{role}: {msg}" for role, msg in st.session_state.messages]
)
query = f"{history}\nAI:"
# Setup any tweaks you want to apply to the flow
inputs = {"input": query}
output = run_flow(inputs, flow_id=FLOW_ID, tweaks=TWEAKS)
print(output)
try:
output = output['result']['output']
except Exception :
output = f"Application error : {output}"
placeholder = st.empty()
response = ""
for tokens in output:
response += tokens
# write response with "▌" to indicate streaming.
with placeholder:
st.markdown(response + "▌")
# write response without "▌" to indicate completed message.
with placeholder:
st.markdown(response)
# Log AI response to chat history
st.session_state.messages.append(("ai", response))
# Unblock chat input
st.session_state.disabled = False
st.rerun()4. インターフェースの作成 :
ここでは、同じpythonファイルに以下のコードを使用して、シンプルなStreamlitユーザーインターフェースを構築します。
st.set_page_config(page_title="Dinnerly")
st.title("Welcome to Dinnerly : Your Healthy Dish Planner")
system_prompt = "You´re a helpful assistant to suggest and provide healthy dishes recipes to users"
if "messages" not in st.session_state:
st.session_state.messages = [("system", system_prompt)]
if "disabled" not in st.session_state:
# `disable` flag to prevent user from sending messages whilst the AI is responding
st.session_state.disabled = False
with st.chat_message("ai"):
st.markdown(
f"Hi! I'm your healthy dish planner. Happy to help you prepare healthy and yummy dishes!"
)
# Display chat messages from history on app rerun
for role, message in st.session_state.messages:
if role == "system":
continue
with st.chat_message(role):
st.markdown(message)
current_chat_message = st.container()
prompt = st.chat_input("Ask your question here...", disabled=st.session_state.disabled)
if prompt:
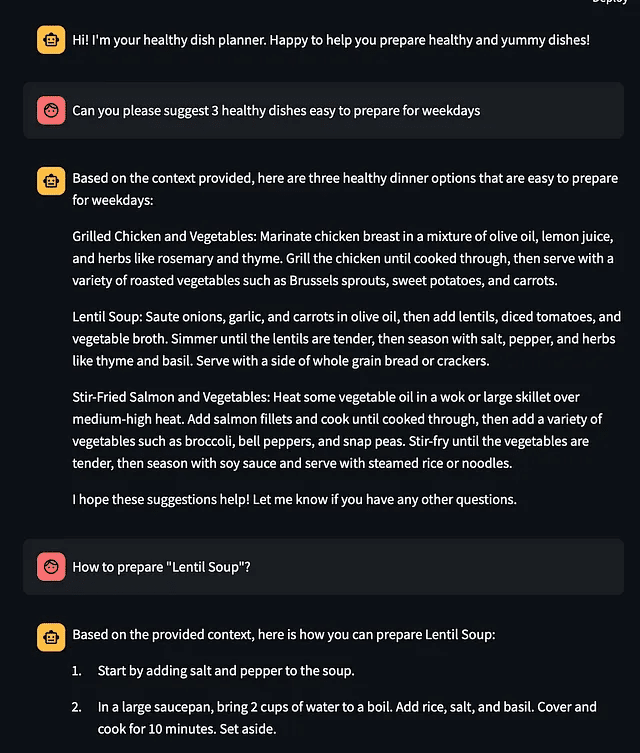
chat(prompt)Streamlitアプリを実行すると、自分だけの料理プランナーとチャットすることができます。
それはあなたが美味しくて健康的な食事を作るのを助けてくれるでしょう。
ヒント:
同じコードとインターフェースを異なるフローに使用できます。単にFLOW_IDを変更して、新しいフローをアプリケーションにテストして統合してください。
結びに
この投稿では、スマートなRAGベースのチャットボットを作成しました。LangFlowを使用してRAGパイプラインを構築し、コーディングする必要なく、埋め込みやLLM処理のためのオープンソースモデルを活用してアプリケーションをローカルで実行し、推論コストをかけずに保ちました。最後に、このセットアップをStreamlitアプリケーションに変換しました。
LangFlowのノーコードの方法が素晴らしい部分であり、AIアプリケーションの構築とプロトタイプの方法を変える可能性があると考えています。
ただし、いくつかのコンポーネントはまだ開発中であり、時々期待通りに動作しないことがあります。これらの瞬間が生じた場合、問題の可視性やトラブルシューティングのガイダンスが不足していることを指摘する価値があります。また、Pythonコードを直接提供してカスタマイズの幅を広げることができるようにすることも改善点と言えます。
参考文献
Deliciously Healthy Dinners(デモで使用されたpdfファイル): https://healthyeating.nhlbi.nih.gov/pdfs/dinners_cookbook_508-compliant.pdf
この記事が気に入ったらサポートをしてみませんか?