
次世代RAG:図解による概要

元ネタ: Advanced RAG Techniques: an Illustrated Overview | by IVAN ILIN | Towards AI
次世代RAG:図解による概要
はじめに
Retrieval Augmented Generation、通称RAGは、LLMに情報を提供し、生成された回答を基盤とする。基本的にRAGは検索+LLMプロンプティングであり、モデルに対して、検索アルゴリズムで見つかった情報をコンテキストとして提供し、クエリに回答するように求める。クエリと取得されたコンテキストは、LLMに送信されるプロンプトに挿入される。
RAGは、2023年のLLMベースのシステムの中で最も人気のあるアーキテクチャである。Web検索エンジンとLLMを組み合わせた質問回答サービスから、数百のデータとチャットを組み合わせたアプリまで、ほとんどがRAGに基づいて構築されている製品が多数存在する。
ベクトル検索分野もその人気に押され、埋め込みベースの検索エンジンは2019年にfaissで作成された。chroma、weaviate.io、pineconeなどのベクトルデータベースのスタートアップは、既存のオープンソース検索インデックス(主にfaissとnmslib)に基づいて構築され、最近では入力テキストの追加ストレージとその他のツールを追加している。
LLMベースのパイプラインとアプリケーションには、2つの主要なオープンソースライブラリがあります。LangChainとLLamaIndexであり、それぞれ2022年の10月と11月に立ち上げられ、ChatGPTのローンチに触発され、2023年に広く採用され始めました。
この記事の目的は、主にLlamaIndexでの実装に言及しながら、主要な高度なRAGテクニックを体系化することで、他の開発者が飛び込みやすくすることです。
問題は、ほとんどのチュートリアルが1つまたは複数のテクニックを選りすぐり、それを実装する方法執着してしまい、利用可能なツールの多様性を説明していないことです。
もう1つ特徴的なのは、LLamaIndexとLangChainの両方が素晴らしいオープンソースプロジェクトであり、そのドキュメントはすでに2016年の機械学習の教科書よりも厚くなっているということです。
Naive RAG
この記事でのRAGパイプラインの出発点は、テキスト文書を集約したデータソースになります。
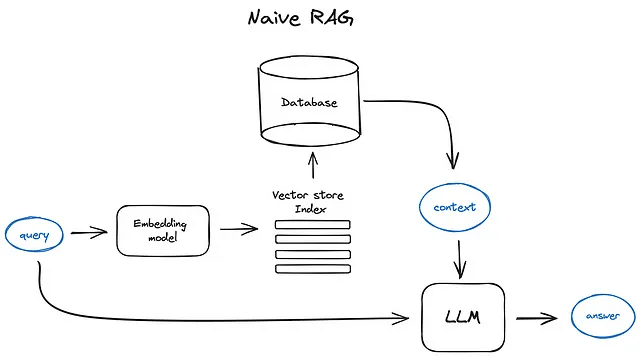
Vanilla RAGケースは、次のように動作します:テキストをチャンクに分割し、それらのチャンクをTransformer Encoderモデルでベクトルに埋め込み、すべてのベクトルをインデックスに入れ、最後にLLMのプロンプトを作成して、ユーザーのクエリに答えるようモデルに指示します。ランタイムでは、同じエンコーダーモデルを使用してユーザーのクエリをベクトル化し、そのクエリベクトルをインデックスと照合し、トップkの結果を見つけ、対応するテキストチャンクをデータベースから取得して、それらをLLMのプロンプトのコンテキストとして提供します。
The prompt can look like that:

Prompt engineeringは、RAGパイプラインを改善するための最も手軽な方法です。OpenAIの包括的なプロンプトエンジニアリングガイドを確認してください。
OpenAIはLLMプロバイダーとしての市場リーダーでありながら、AnthropicのClaude、MistralのMixtral、MicrosoftのPhi-2などの新しいモデルや、Llama2、OpenLLaMA、Falconなどのオープンソース言語モデルなど、RAGパイプラインとしての選択肢が多いです。
Advanced RAG
ここでは、高度なRAG技術の概要について詳しく説明します。以下は、関連する主要なステップとアルゴリズムを示したスキームです。スキームの可読性を保つため、一部の論理ループや複雑な多段階のエージェント行動は省略されています。
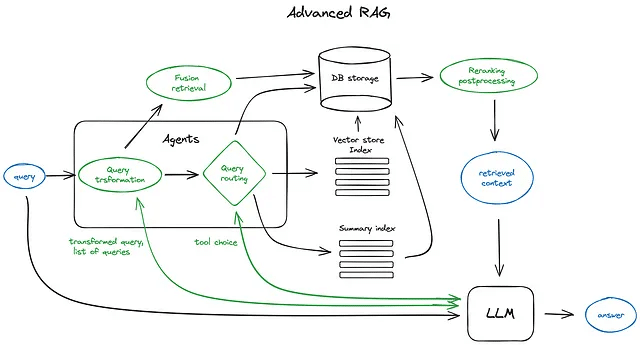
スキーム上の緑色の要素はさらに下記で紹介されるRAGの技術であり、青色のものはテキストです。さまざまな文脈拡大手法など、この図ではすべての高度なRAGのアイデアを1つのスキームで簡単に視覚化することができ無いものもあります。それについては途中で詳しく説明します。
1. チャンキングとベクトル化
最初のステップでは、文書内容を表すベクトルのインデックスを作成し、ランタイムでこれらのベクトルとクエリベクトルの間の最小余弦距離を検索することを目指しています。これにより、最も近い意味を持つクエリベクトルが対応することになります。
1.1 チャンキング
Transformerモデルは固定の入力シーケンス長を持っており、入力コンテキストウィンドウが大きくても、文のベクトルまたは数ページにわたって平均化されたベクトルよりも、その意味をよりよく表す。したがって、データをチャンク化することが重要です。つまり、初期ドキュメントを意味を失わないようにいくつかのサイズのチャンクに分割します(文または段落にテキストを分割し、単一の文を2つに分割しないようにします)。このタスクに対応したさまざまなテキスト分割実装があります。
チャンクのサイズは重要なパラメータです。使用する埋め込みモデルとそのトークン容量に依存します。BERTベースのSentence Transformersなどの標準のトランスフォーマーエンコーダーモデルは最大で512トークンを取ります。一方、OpenAI ada-002は8191トークンのような長いシーケンスを処理できますが、ここでの妥協点は、LLMが推論するための十分なコンテキスト vs 効率的な検索を実行するための特定のテキスト埋め込みです。こちらで、チャンクサイズ選択に関する懸念を示した研究が見つかります。LlamaIndexでは、NodeParserクラスが、独自のテキスト分割、メタデータ、ノード/チャンクの関係の定義など、いくつかの高度なオプションでこれをカバーしています。
1.2 ベクトル化
次のステップは、チャンクを埋め込むモデルを選択することです。いくつかのオプションがありますが、私はbge-largeやE5などの検索最適化モデルを選択します。最新の情報はMTEB leaderboardをチェックしてください。
チャンキングとベクトル化ステップのエンドツーエンドの実装については、LlamaIndexの完全なデータ取り込みパイプラインの例をご覧ください。
2. 検索インデックス
2.1 ベクトルストアインデックス
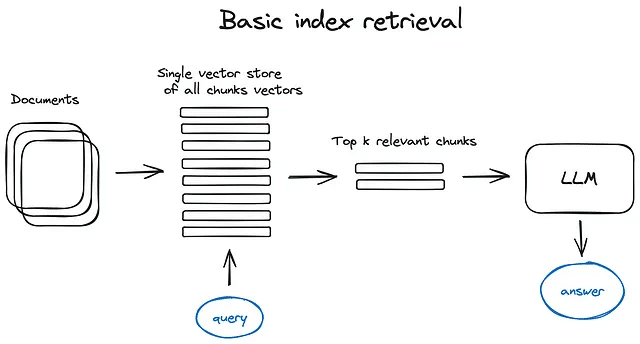
このスキームおよびテキスト全体で、エンコーダーブロックを省略し、クエリを直接インデックスに送信します。もちろん、クエリは常にベクトル化されます。トップkチャンクも同様に、インデックスはトップkベクトルを取得しますが、それらをチャンクと置き換えます。
RAGパイプラインの重要な部分は、検索インデックスであり、前のステップで取得したベクトル化されたコンテンツを格納します。最も単純な実装では、フラットインデックスが使用されます。つまり、クエリベクトルとすべてのチャンクベクトルの間で総当たりの距離計算が行われます。
効率的な検索を最適化した適切な検索インデックスは、10000以上の要素にスケーリングされるベクトルインデックス、たとえばfaiss、nmslib、またはannoyのような、クラスタリング、ツリー、またはHNSWアルゴリズムなどの近似最近傍探索の実装を使用します。
また、OpenSearchやElasticSearchのような管理されたソリューションや、Pinecone、Weaviate、Chromaのようなデータ取り込みパイプラインを処理するベクトルデータベースなどもあります。
インデックスの選択、データ、および検索のニーズに応じて、ベクトルと一緒にメタデータを保存し、たとえば日付やソース内の情報を検索するためにメタデータフィルターを使用することもできます。
LlamaIndexはベクトルストアインデックスを多くサポートしていますが、リストインデックス、ツリーインデックス、およびキーワードテーブルインデックスなど、他のより単純なインデックス実装もサポートされています。後者については、フュージョン検索の部分で詳しく説明します。
2.2 階層的なインデックス
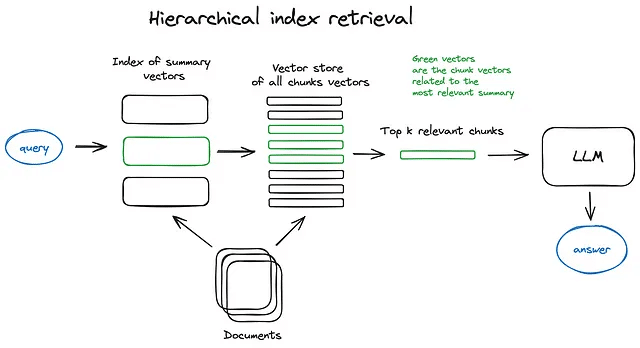
多くの文書を取得する必要がある場合、それらの中を効率的に検索し、関連情報を見つけ、参照元を含めた一つの回答にまとめる必要があります。大規模なデータベースの場合、効率的な方法は、要約から構成される1つの索引と文書チャンクから構成されるもう1つの索引を作成し、まず要約によって関連する文書を絞り込み、その後その関連グループ内で検索することです。
2.3 仮説的な質問とHyDE
別のアプローチとしては、LLMに各チャンクに対して質問を生成し、これらの質問をベクトルに埋め込むように求め、実行時にこの質問ベクトルのインデックスを使用したクエリ検索があります(チャンクベクトルを質問ベクトルに置き換えてインデックスを作成)。その後、取得した情報を元のテキストチャンクにルーティングし、それらをLLMの回答のコンテキストとして送信します。このアプローチは、クエリと仮想的な質問との間の意味的類似性が実際のチャンクの場合よりも高いため、検索品質が向上します。
また、逆転した論理的なアプローチであるHyDEというものもあります。これは、LLMにクエリに対する仮想的な応答を生成させ、そのベクトルをクエリベクトルとともに使用して検索品質を向上させるものです。
2.4 コンテキストの充実
ここでのコンセプトは、より良い検索品質のためにより小さなチャンクを取得することですが、LLMが推論するために周囲のコンテキストを追加します。 2つのオプションがあります - より小さな取得されたチャンクの周囲の文を展開するか、文書を再帰的に複数の大きな親チャンクに分割して、より小さな子チャンクを含めることです。
2.4.1 文ウィンドウの取得
このスキームでは、文書内の各文が個別に埋め込まれるため、クエリとコンテキストのコサイン距離検索の高い精度が提供されます。最も関連性のある単一の文を取得した後に見つかったコンテキストについてより良い推論を行うために、取得した文の前後にk文のコンテキストウィンドウを拡張し、この拡張されたコンテキストをLLMに送信します。

緑の部分は、インデックス内で見つかった文章の埋め込みです。そして、黒色と緑色の段落全体がLLMに供給され、提供されたクエリに対する推論を行う際にその文脈を拡大します。
2.4.2 Auto-merging Retriever (またはParent Document Retriever)
ここでのアイデアは、ほぼSentence Window Retrieverと同じです。つまり、より細かい情報を検索し、それを推論のためのLLMに渡す前に、コンテキストウィンドウを拡張することです。ドキュメントは、より大きな親チャンクを参照するより小さな子チャンクに分割されます。

ドキュメントは階層構造のチャンクに分割され、その後最も小さなリーフチャンクがインデックスに送信されます。検索時には、k個のリーフチャンクを取得し、同じ親チャンクを参照するn個のチャンクがあれば、これらを親チャンクに置き換えてLLMに送信し、回答を生成します。
検索時にはまずより小さなチャンクを取得し、その後、トップk個の取得されたチャンクの中でn個以上のチャンクが同じ親ノード(より大きなチャンク)にリンクされている場合、この親ノードによってLLMに提供されるコンテキストを置き換えます。これは、いくつかの取得されたチャンクを自動的により大きな親チャンクにマージするように機能するため、メソッド名が付けられています。ただし、検索は子ノードのインデックス内でのみ実行されます。詳細については、Recursive Retriever + Node ReferencesのLlamaIndexチュートリアルをご覧ください。
2.5 フュージョン検索またはハイブリッド検索
比較的古い考え方で、両者の利点を採用するというアイデアがあります — キーワードベースの検索 — tf-idf のような疎な検索アルゴリズムや検索業界の標準である BM25 — そして現代の意味論的またはベクトル検索を組み合わせて、1つの検索結果にまとめるというものです。ここで唯一のトリックは、異なる類似性スコアで取得した結果を適切に組み合わせることです — この問題は通常、Reciprocal Rank Fusion アルゴリズムの助けを借りて解決され、最終出力のために取得した結果を再ランキングします。
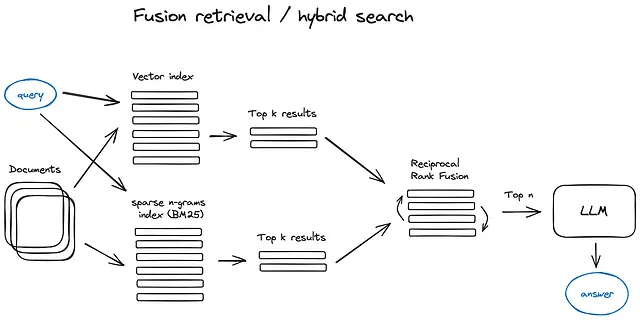
LangChainでは、これはEnsemble Retrieverクラスで実装されており、定義したリトリーバのリストを組み合わせています。たとえば、faissベクトルインデックスとBM25ベースのリトリーバを使用し、RRFを再ランキングに使用します。
一方、LlamaIndexでは、こちらでほぼ同様の方法で行われています。
ハイブリッドまたはフュージョン検索は通常、2つの補完的な検索アルゴリズムを組み合わせるため、クエリと格納されたドキュメントの間の意味の類似性とキーワードの一致を考慮して、より良い検索結果を提供します。
3. 再ランキングとフィルタリング
上記のいずれかのアルゴリズムで検索結果を取得しました。これからは、フィルタリング、再ランキング、またはいくつかの変換を通じてそれらを洗練させる時です。LlamaIndexには、Postprocessors があり、類似スコア、キーワード、メタデータに基づいて結果をフィルタリングしたり、他のモデルで再ランキングしたりすることができます。たとえば、LLM、sentence-transformer cross-encoder、Cohereの再ランキングエンドポイント、または日付の新しさなどのメタデータに基づいて再ランキングすることができます。基本的に、想像できるすべてが可能です。
これは、取得したコンテキストをLLMに提供して結果の回答を得る前の最終段階です。
これからは、クエリ変換やルーティングなどのより洗練されたRAG技術に取り組む時です。これらは、LLMを含むため、エージェント的な振る舞いであり、RAGパイプライン内でLLMの推論を含む複雑なロジックを表しています。
4. クエリ変換
クエリ変換は、ユーザーの入力を改善して検索品質を向上させるために、LLMを推論エンジンとして使用する技術の一群です。 そのためのさまざまなオプションがあります。
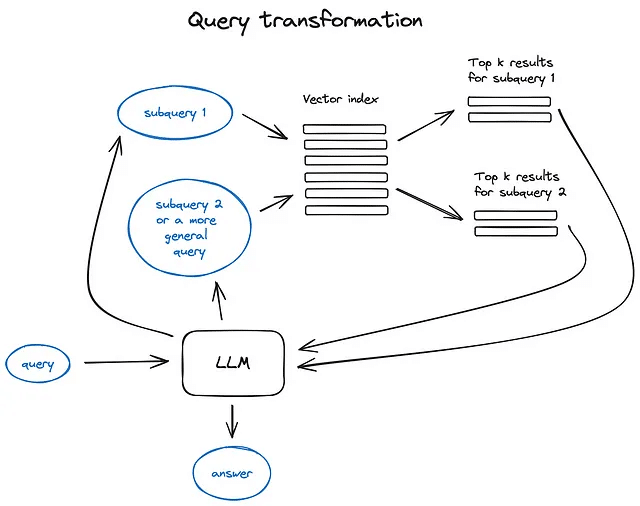
クエリが複雑な場合、LLMはそれを複数のサブクエリに分解することができます。 たとえば、あなたが尋ねたのが — “Githubで星が多いフレームワークは、LangchainとLlamaIndexのどちらですか?” という質問である場合、私たちのコーパスのテキストに直接的な比較が見つかる可能性は低いため、この質問をより単純で具体的な情報検索を前提とした2つのサブクエリに分解することが理にかなっています: — “LangchainはGithubでいくつの星を持っていますか?” — “LlamaindexはGithubでいくつの星を持っていますか?” これらは並行して実行され、その後、取得したコンテキストが結合され、初期のクエリに対する最終的な回答を合成するためのLLMに単一のプロンプトとして提供されます。 両方のライブラリには、これを実装した機能があります — LangchainにはMulti Query Retriever があり、LlamaindexにはSub Question Query Engine があります。
ステップバックプロンプティング は、より一般的なクエリを生成するためにLLMを使用し、その結果、より一般的または高レベルのコンテキストを取得し、元のクエリに対する回答を基盤とするのに役立ちます。 元のクエリのための検索も実行され、両方のコンテキストがLLMに最終的な回答生成ステップで提供されます。 こ
ちらはLangChainの実装 です。
クエリの書き直しは、初期のクエリを改変するためにLLMを使用します。これにより、検索が改善されます。 LangChain とLlamaIndex の両方に実装がありますが、少し異なる点があります。私はLlamaIndexのソリューションがここでより強力だと考えています。
参考文献引用
これは番号なしで(回収改善技術よりもむしろ手段であるため、非常に重要です)。 回答を生成するために複数のソースを使用した場合、初期のクエリの複雑さ(複数のサブクエリを実行し、その後に回収されたコンテキストを1つの回答に組み合わせる必要があった)または単一のクエリの関連コンテキストを複数の文書で見つけたため、私たちが正確にソースをバックリファレンスできるかどうかという問題が発生します。
それを行うためのいくつかの方法があります:
この参照タスクをプロンプトに挿入し、LLMに使用されたソースのIDを言及するように求めます。
生成された応答の部分を元のテキストのチャンクにマッチングする — llamaindexはこのケースに対して効率的なfuzzy matchingベースのソリューションを提供しています。Fuzzy matchingについて聞いたことがない場合、これは非常に強力な文字列マッチングテクニックです。
5. チャットエンジン
素敵なRAGシステムを構築する際の次の大きなポイントは、対話コンテキストを考慮したチャットロジックです。これは、LLM以前のクラシックなチャットボットと同様に、単一のクエリに対して複数回機能する必要があります。これは、追加の質問、照応、または前回の対話コンテキストに関連する任意のユーザーコマンドをサポートするために必要です。クエリ圧縮技術を使用してチャットコンテキストを考慮し、ユーザークエリと一緒に解決されます。
いつものように、このコンテキストの圧縮にはいくつかのアプローチがあります。人気のある比較的シンプルなContextChatEngineでは、まずユーザーのクエリに関連するコンテキストを取得し、それをLLMに送信し、LLMが次の回答を生成する際にメモリバッファからのチャット履歴と共に前のコンテキストを認識できるようにします。
もう少し洗練されたケースはCondensePlusContextModeで、各インタラクションでチャット履歴と最後のメッセージが新しいクエリに縮約され、そのクエリがインデックスに送られ、取得したコンテキストがLLMに渡され、元のユーザーメッセージと共に回答を生成します。
重要な点として、LlamaIndexではOpenAIエージェントベースのチャットエンジンもサポートされており、より柔軟なチャットモードを提供しています。また、LangchainもOpenAI機能APIをサポートしています。
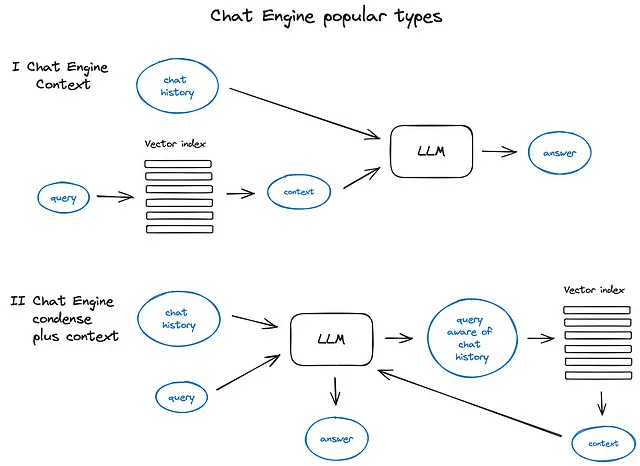
異なるチャットエンジンの種類と原則のイラスト
ReAct Agent のような他のチャットエンジンの種類もありますが、セクション7でエージェント自体に進みましょう。
6. クエリルーティング
クエリルーティングは、LLMパワードの意思決定のステップであり、ユーザークエリに対して次に何をするかを決定するものです — 通常のオプションは、要約するか、あるデータインデックスに対して検索を行うか、またはさまざまなルートを試行してその出力を単一の回答にまとめることです。
クエリルーターは、ユーザークエリを送信するためのインデックス、またはより広い意味でデータストアを選択するためにも使用されます。たとえば、クラシックなベクトルストアとグラフデータベース、またはリレーショナルDBなど、複数のデータソースがある場合や、インデックスの階層がある場合もあります。複数のドキュメントを保存する場合、典型的なケースとしては、要約のインデックスと、例えばドキュメントチャンクのベクトルの別のインデックスがあります。
クエリルーターの定義には、それが行うことができる選択肢を設定することが含まれます。 ルーティングオプションの選択は、LLMの呼び出しで行われ、その結果は事前に定義された形式で返され、クエリを指定されたインデックスにルーティングするために使用されます。また、アグナティックな振る舞いの場合、Multi documents agent scheme で示されているように、サブチェーンや他のエージェントにも送信されます。
LlamaIndex と LangChain は、クエリルーターをサポートしています。
7. RAG内のエージェント
LangchainとLlamaIndexの両方によってサポートされているエージェントは、ほぼ最初のLLM APIがリリースされて以来存在しています。そのアイデアは、推論が可能なLLMに、完了すべきタスクとツールのセットを提供することでした。ツールには、コード関数や外部API、他のエージェントなどの決定論的な機能が含まれる場合があります。このLLMチェーンのアイデアは、LangChainの名前の由来となっています。
エージェント自体が非常に重要なものであり、RAGの概要の中でそのトピックに深く入り込むことは不可能です。そのため、エージェントベースのマルチドキュメント検索ケースについて続け、比較的新しいものとして最近のOpenAI開発者会議でGPTsとして発表されたOpenAIアシスタントステーションで短い停止を行います。そして、以下で説明するRAGシステムの下で動作しています。
OpenAIアシスタントは、以前にオープンソースで利用可能だったLLM周りの多くのツールを実装しています。チャット履歴、知識ストレージ、ドキュメントのアップロードインターフェース、そしておそらく最も重要なのは関数呼び出しAPIです。後者は、自然言語を外部ツールやデータベースクエリへのAPI呼び出しに変換する機能を提供します。
LlamaIndexには、この高度なロジックをChatEngineとQueryEngineクラスと結びつけたOpenAIAgentクラスがあり、知識ベースのコンテキストに応じたチャットと、1つの会話ターンで複数のOpenAI関数呼び出しを行う能力を提供し、本当にスマートなエージェントの振る舞いを実現しています。
マルチドキュメントエージェントスキームを見てみましょう。これはかなり洗練された設定で、各ドキュメントごとにエージェント(OpenAIAgent)を初期化し、ドキュメントの要約とクラシックなQAメカニクスを行うことができるとともに、クエリをドキュメントエージェントにルーティングし、最終的な回答の合成を行うトップエージェントがあります。
各ドキュメントエージェントには、ベクトルストアインデックスと要約インデックスの2つのツールがあり、ルーティングされたクエリに基づいてどちらを使用するかを決定します。そして、トップエージェントにとっては、すべてのドキュメントエージェントがそれぞれのツールです。
このスキームは、関与する各エージェントによって多くのルーティング決定が行われる高度なRAGアーキテクチャを示しています。このアプローチの利点は、異なるドキュメントとその要約に記載された異なるソリューションやエンティティを比較する能力と、クラシックな単一ドキュメントの要約とQAメカニクスが含まれており、基本的には最も頻繁に行われるドキュメントの集まりとのチャットをカバーしています。

複数の文書エージェントを示すスキームは、クエリのルーティングとエージェントの行動パターンの両方を含んでいます。
このような複雑なスキームの欠点は、図から推測できます。エージェント内のLLMとの複数のやり取りにより、少し遅くなるという点です。念のために、LLMの呼び出しは常にRAGパイプライン内で最も時間がかかる操作です。検索は速度を重視して設計されています。そのため、大規模な複数文書ストレージの場合は、このスキームを拡張可能にするためのいくつかの簡略化を考えることをお勧めします。
8. レスポンス合成器
これは、任意のRAGパイプラインの最終段階です。私たちが注意深く取得したすべてのコンテキストと初期のユーザークエリに基づいて回答を生成します。最も簡単なアプローチは、単に取得したすべてのコンテキスト(一定の関連性の閾値を超える)とクエリを一度にLLMに連結して提供することです。しかし、いつものように、取得したコンテキストを洗練させ、より良い回答を生成するために複数のLLM呼び出しを含む他の洗練されたオプションがあります。
レスポンス合成の主なアプローチは次のとおりです:1. 回答を反復的に洗練する - 取得したコンテキストをLLMにチャンクごとに送信する2. 取得したコンテキストを要約する - プロンプトに収まるように3. 異なるコンテキストチャンクに基づいて複数の回答を生成し、それらを連結または要約する。詳細については、レスポンス合成モジュールのドキュメントをご覧ください。
エンコーダとLLMファインチューニング
このアプローチでは、私たちのRAGパイプラインに関与する2つのDLモデルのうちいくつかを微調整します。それは、Transformerのエンコーダー(埋め込みの品質およびそれによるコンテキストの取得品質に責任がある)または提供されたコンテキストを使用してユーザーのクエリに答えるための最善のLLM(Long Length Matching)に責任がある。幸運なことに、後者は優れたfew shot learnerです。
今日の大きな利点の1つは、GPT-4のようなハイエンドのLLMが利用可能であり、高品質の合成データセットを生成できることです。ただし、常に注意しておくべきことは、プロの研究チームによって慎重に収集、クリーニング、検証された大規模なデータセットで訓練されたオープンソースモデルを取り上げ、小さな合成データセットを使用して素早く調整することが、一般的にモデルの能力を狭める可能性があるということです。
エンコーダーの微調整
最新のTransformerエンコーダーは検索に最適化されており、エンコーダーの微調整アプローチについては少し懐疑的でした。したがって、bge-large-en-v1.5(執筆時点でMTEB leaderboardのトップ4)の微調整によるパフォーマンス向上をLlamaIndex notebookでテストし、リトリーバル品質が2%向上したことが示されました。劇的な変化はありませんが、特にRAGを構築する狭いドメインのデータセットがある場合には、このオプションを知っておくと良いでしょう。
ランカーの微調整
他の古典的なオプションは、検索結果を再ランキングするためにクロスエンコーダーを使用することです。これは次のように機能します。クエリと上位k個の取得されたテキストチャンクをクロスエンコーダーに渡し、SEPトークンで区切って、関連するチャンクには1を、関連しないチャンクには0を出力するように微調整します。この微調整プロセスの良い例はこちらで見つけることができ、クロスエンコーダーの微調整によってペアワイズスコアが4%向上したとの結果が示されています。
LLMの微調整
最近、OpenAIはLLMの微調整APIを提供し始め、LlamaIndexにはRAG設定でGPT-3.5-turboを微調整するチュートリアルがあります。ここでのアイデアは、ドキュメントを取得し、GPT-3.5-turboでいくつかの質問を生成し、その後GPT-4を使用してこれらの質問に基づいてドキュメントの内容に回答を生成し(GPT4パワードのRAGパイプラインを構築)、その質問と回答のペアのデータセットでGPT-3.5-turboを微調整することです。RAGパイプラインの評価に使用されるragasフレームワークは、微調整されたGPT 3.5-turboモデルが提供されたコンテキストを生成するために元のモデルよりもより良い利用をしたことを示し、忠実度メトリクスが5%向上しました。
最近の論文 RA-DIT: 検索強化デュアルインストラクションチューニングでは、Meta AI Researchによって、LLMとリトリーバー(元の論文ではデュアルエンコーダー)の両方をクエリ、コンテキスト、回答の三つ組で微調整する技術が提案されています。実装の詳細については、このガイドを参照してください。この技術は、OpenAI LLMを微調整APIを介して微調整し、元の論文ではLlama2オープンソースモデルに適用され、知識集約的なタスクメトリクスで約5%、常識的な推論タスクで数パーセントの向上が見られました。
LLMのRAG用のより良い微調整アプローチをご存知の場合は、特に小規模なオープンソースのLLMに適用される場合は、コメントセクションで専門知識を共有してください。
評価
RAGシステムのパフォーマンス評価には、いくつかのフレームワークがあり、回答の関連性、回答の根拠、忠実度、および取得されたコンテキストの関連性など、いくつかの独立したメトリクスを持つという考え方が共有されています。
前述のセクションで言及されたRagasは、生成された回答の品質メトリクスとして忠実度と回答の関連性を使用し、RAGスキームの取得部分にはクラシックなコンテキストの精度と再現率を使用しています。
最近リリースされた素晴らしい短期コースBuilding and Evaluating Advanced RAGでは、Andrew NG、LlamaIndex、および評価フレームワークTruelensが、RAGトライアド — クエリに対する取得されたコンテキストの関連性、根拠(LLM回答が提供されたコンテキストによってどれだけサポートされているか)、およびクエリに対する回答の関連性を提案しています。
主要で最もコントロール可能なメトリクスは取得されたコンテキストの関連性であり、基本的には上記で説明した高度なRAGパイプラインのパート1から7に加えて、エンコーダーとランカーのファインチューニングセクションがこのメトリクスの改善を意図しており、一方でパート8とLLMのファインチューニングは回答の関連性と根拠に焦点を当てています。
比較的シンプルなリトリーバー評価パイプラインの良い例はこちらで見つけることができ、これはエンコーダーのファインチューニングセクションで適用されました。ヒット率だけでなく平均相互順位などの一般的な検索エンジンメトリクスや、忠実度や関連性などの生成された回答メトリクスを考慮に入れたもう少し高度なアプローチは、OpenAIのcookbookで示されています。
LangChainには、カスタム評価者を実装できるかつRAGパイプライン内で実行されるトレースを監視してシステムをより透明にすることができる、かなり高度な評価フレームワークLangSmithがあります。
LlamaIndexを使用している場合は、rag_evaluator llama packがあり、パブリックデータセットを使用してパイプラインを評価するための迅速なツールを提供しています。
結論
RAGの中核となるアルゴリズム的アプローチを概説し、その中のいくつかを具体例として示しました。これにより、RAGパイプラインで試してみる新しいアイデアの火付け役となるか、今年に発明された多様な技術にいくらかの体系をもたらすことを期待しています。私にとって2023年はこれまでで最もエキサイティングな機械学習の年でした。
他にも考慮すべきことがたくさんあります。例えば、ウェブ検索ベースのRAG(RAGs by LlamaIndex、webLangChainなど)、エージェントアーキテクチャにより深く踏み込むこと(そして最近のこの分野でのOpenAIの取り組み)、そしてLLMsの長期記憶に関するいくつかのアイデアです。
回答の関連性と忠実性に加えて、RAGシステムの主要な製品化の課題は速度です。特に柔軟なエージェントベースのスキームに興味がある場合は、これは別の投稿の話題です。このストリーミング機能はChatGPTや他のアシスタントが使用するものは、ランダムなサイバーパンクスタイルではなく、単に知覚される回答生成時間を短縮するためのものです。そのため、私は小規模なLLMsや最近のMixtralやPhi-2のリリースがこの方向に私たちを導いていると考えています。
この記事が気に入ったらサポートをしてみませんか?