Julia言語の第一印象

概要
Juliaというプログラミング言語を少し触ってみました.とあるFortranユーザのEngineerが感じた,Juliaの第一印象を正直にまとめます.立場的にかなり偏った印象になっているので,これからJuliaを使ってみようという人は,この記事を参考にせずに自身で触った印象を信じてください.
印象を簡潔に言うなら,「処理の記述は最高だが,いうほど速くはないし,変数宣言や最適化が面倒くさそう」です.
Juliaとの出会い
初めてJuliaに関する話題を聞いたのは,2014~5年頃です.私にオブジェクト指向プログラミングを教えてくれた方が,「Pythonぽいけど数値計算向けを謳っている言語があるよ」と教えてくれました.その頃の私はPythonを触りだしたばかりで,速さを求めるならFortranがあるし,柔軟性ならオブジェクト指向プログラミングを導入すればいいし,それにPythonも触っているからと,特に気にはしていませんでした.
公式サイトによると,Juliaは数値計算のための高レベル・ハイパフォーマンス・動的プログラミング言語だそうです.ですが,Juliaのどの機能が気になったから使おうと決めたわけでもありません.強いて言うならJupyterで動くからです.Pythonにも慣れてきて,Jupyter+numpy+matplotlibでそこそこの処理ができるようになったので,言い方は悪いですがJuliaが速いPythonなら乗り換えてしまおうと考えて試用しはじめました.
インストール
Windowsを使っていると,Juliaのインストールは少し面倒です.ですが,壊滅的に難しいというわけでもなく,まあこんなもんでしょうという印象でした.パッケージマネージャも公式のものが正しく動作するので,Anacondaを使わずにPythonとその他のライブラリをインストールするよりは簡単です.
よい点
処理の記述は最高です.待ち望んでいたものがここにあったと感じます.
まず変数名にユニコードが使えること,これはPythonでも可能ですが,LaTeX記法を採用してTabで置換してくれるのが最高です.
そして,数値と変数の積を,演算子抜きで書けることも最高です.
Fortranと同様に,配列の範囲をコロンで指定できますが,その範囲を変数として保持し,それらに対して演算ができるのも素晴らしい仕様です.これで式とプログラムをより近づけることができますが,もっとよいことは,変数名をどうしようかと悩む時間が減らせることです.
演算子にもユニコードが使えるので,×で外積が計算できたり,if文の比較に≠が使えたりするのも,かゆいところに手が届く感じでよいと感じます.
細かい事ですが,配列が1開始であるとか,多次元配列は次元が小さい方向にメモリが連続([i,j,k]だとi→j→kの順に連続)になるというFortranと同じ仕様であるのも,移植の際に助かります.
以下に,1次元移流方程式を計算する式と,JuliaとFortranで書いたコードの一部を示します.どちらの方がFormula Translationしているかといわれれば,Juliaの方でしょう.
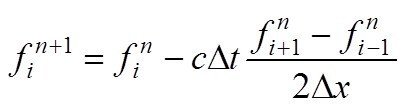
#Julia
domain = 2:Nx-1 !Nxは離散点の個数
fⁿ⁺¹[domain] = fⁿ[domain] - c*Δt*(fⁿ[domain+1] - fⁿ[domain-1])/2Δx
!Fortran
f_new(2:Nx-1) = f(2:Nx-1) - c*dt*(f(3:Nx)-f(1:Nx-2))/(2d0*dx)これはちょっと・・・という点
変数(配列)の宣言の仕方が色々あるのは,便利なようですが,複数人で開発する,あるいは他人のソースを見る際に手を焼きそうです.(Fortranが現在進行形でそうであるように)
配列の初期化も,[1,2,3], [1;2;3], [1 2 3]と複数の書き方ができるのが便利と思わせて,結果作られる配列が違う(前二つは3行1列,最後は1行3列)というのは,最初戸惑いそうです.
演算子に複数の意味があるのも,少し戸惑います.*はスカラ変数に対して単純な積を計算しますが,配列になると要素同士の積ではなく,内積を意味します.1次元配列であっても,形状をきちんと意識しなければなりません.とはいえ,数学的には別のものを他の言語が区別していなかったと考えれば,Juliaの仕様の方が正しいとも言えます.ただ,古典的な手続き型プログラミングに慣れた人には,乗り換える際の障壁になる可能性があるだろうと考えています.
Juliaは動的型付け言語であり,型宣言は不要です.しかし,最適化のためには結局型を意識しなければならないようで,なんというか,本末転倒のように思います.
Juliaの速さはJITコンパイルに依存しているらしく,チュートリアルとして用意されているJupyterノートブックを実行しようとすると,ちょいちょいコンパイルしていると思われる引っかかりを感じます.このせいで,Pythonよりも遅いと感じます.実行時間を測る場合も,1回目はコンパイルの時間があるから2回測りましょうという説明があって(JuliaCon 2015のYoutubeビデオ),それってどうなの?と思います.
Juliaは速いと言われていますが,公式ページでベンチマークとして行われている問題は,少なくとも私が業務で見た範囲では登場しません.フィボナッチ数列を求める場面も,マンデルブロ集合を計算する場面もありません.物理量を馬鹿でかい配列に保持して,せっせと連立一次方程式を解く問題ばかりなので,NASAが行っているこのベンチマークの方が問題設定としては近いように思います.
まとめ
数日間触っただけの印象をダラダラと述べました.冒頭の繰り返しになりますが,処理の記述は最高です.これはちょっと・・・と思う点もありますが,要は慣れの問題ですし,これだけ書きやすいのであれば,今は対象を限って使い,高速化するにつれて徐々にJuliaにシフトしていくのも一つの手だと考えています.
結局のところ,私の要望を完全に叶えるには,Fortranのトランスパイラがあればいいのですが,それが登場するよりはJuliaの改善の方が速いでしょう.速度や使い勝手はこれから改善されるものと期待しています.JuliaのメタプログランミングでFortranのコードを吐かせる構想も抱いています.
私は手続き型プログラミングに慣れきっており,またScientificではなくEngineering problemへの適用を念頭にしているので,Juliaの哲学に沿わない使い方をしている可能性が大いにあります.その辺りはこれから使い込むうちに意見が変わると思います.
公開すると勝手にJuliadomainというハッシュタグが付いて,消しても消しても付くのはなぜ?
この記事が気に入ったらサポートをしてみませんか?