記事一覧


進化的アルゴリズムをもちいたChatVector加算の最適化
はじめにこれまで何度かChatVectorやそれに類することを施行してきましたが、元のモデル+ChatVectorの加算はいつも1:1で実施してきました。それでもある程度上手くいっていましたが、この加算比率をSakanaAIのEvoLLMのように最適化するということができるらしいです。
ただ、調べた限りコードが落ちていなかったので自分なりに調べて試してみたというのが本記事の内容になります。
1.

Google Colabで時系列基盤モデルを試す③:IBM granite
はじめに前々回のGoogle Timesfm、前回のMomentに引き続き、HuggingFaceにある商用可能なライセンスの時系列基盤モデルを4つ試し、比較していきたいと思います。
利用するデータはETTh1という電力変圧器温度に関する多変量時系列データセットです。事前学習にこのデータが含まれる可能性があるため、モデルの絶対的な評価に繋がらないことに注意してください。
google/times

Google Colabで時系列基盤モデルを試す②:AutonLab MOMENT
はじめに前回のGoogle Timesfmに引き続き、HuggingFaceにある商用可能なライセンスの時系列基盤モデルを4つ試し、比較していきたいと思います。
利用するデータはETTh1という電力変圧器温度に関する多変量時系列データセットです。事前学習にこのデータが含まれる可能性があるため、モデルの絶対的な評価に繋がらないことに注意してください。
google/timesfm-1.0-200

Google Colabで時系列基盤モデルを試す①:Google timesfm
はじめにTransformerアーキテクチャにテキストデータを大量に読み込ませたらある程度あらゆる場面で使えるモデルができたというのがGPTやBERTなどの言語のFoundation Model(基盤モデル)です。
それと同じ発想で、あらゆる時系列データを読み込ませたら、あらゆる場面で使える時系列モデルが作れるのではないかという発想で作ったのが時系列の基盤モデルになります。
HuggingFa

LLMによる合成データ(Synthetic Data)生成のテクニック
私は最近、LLMによるSynthetic data(合成データ)生成を試しています。手法について色々調べたり試したことをまとめておこうと思います。
個別の論文の詳細については他の方の記事や私の過去記事でまとめたりしてあるので、どちらかというと合成データ生成における方向性にどんなものがあるのかという観点で紹介したいと思います。
概要LLMによる合成データ生成には、その使い道から以下の2つの種類があ

論文メモ: Self-Rewarding Language Models
私は最近、LLMによるSynthetic data(合成データ)生成を試しています。手法について色々調べているので論文等忘れないようにこの場にメモを残していきたいと思います。
基本的に、『Synthetic dataをどう作るか』によったメモとなるので、その論文中の結果等は書かなかったりすると思います。
また、内容には私、GPT、Claudeの見解を含みます。
1. 今回の論文今回は以下の論文を

論文メモ: Beyond Human Data: Scaling Self-Training for Problem-Solving with Language Models
私は最近、LLMによるSynthetic data(合成データ)生成を試しています。手法について色々調べているので論文等忘れないようにこの場にメモを残していきたいと思います。
基本的に、『Synthetic dataをどう作るか』によったメモとなるので、その論文中の結果等は書かなかったりすると思います。
また、内容には私、GPT、Claudeの見解を含みます。
1. 今回の論文今回は以下の論文を
Chat VectorとMath Vectorは併用できるのか
はじめにこの記事は以下記事の続きになります。
Chat Vectorと呼ばれる、重みの足し引きでFine TuningなしにChat能力を事前学習モデルに付与できるという技術あります。
この発想から、Chat能力以外にも能力の切り貼りはできるのかという検証が前記事までの趣旨となります。
結果以下の通りです。
⭕️ Chat(論文)
× Code
⭕️ Math Reasoning
なので
Chat VectorならぬMath Vectorは作れるのか
はじめにこの記事は以下記事の続きになります。
Chat Vectorと呼ばれる、重みの足し引きでFine TuningなしにChat能力を事前学習モデルに付与できるという技術あります。
この発想から、Chat能力以外にも能力の切り貼りはできるのかという検証が本記事の趣旨となります。
今回は以下の能力について試したいと思います。
数学的推論能力
結論だけ書くとある程度うまくいきました。検証記録
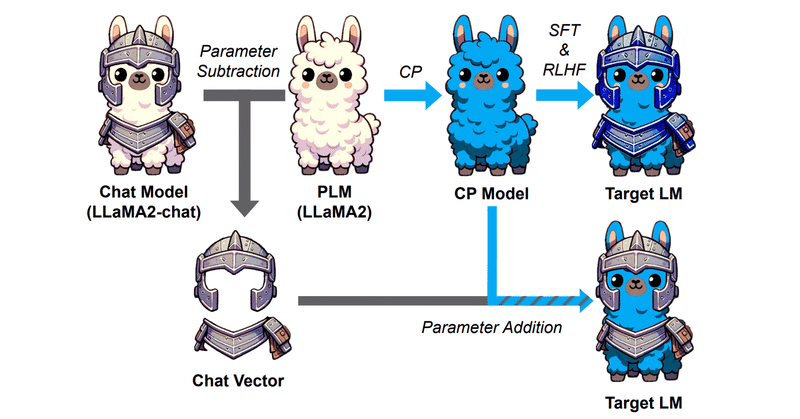
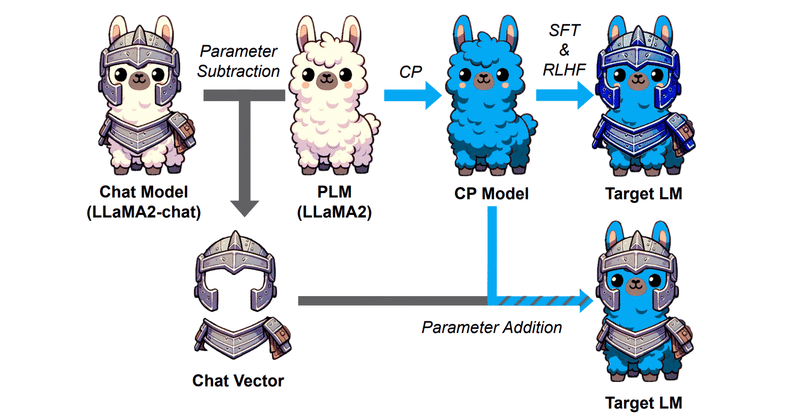
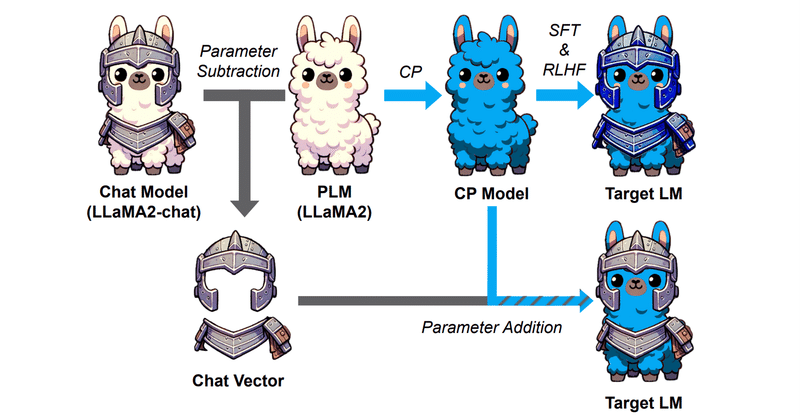
Chat VectorにならぬCode Vectorは作れるのか
はじめにChat Vectorと呼ばれる、重みの足し引きでFine TuningなしにChat能力を事前学習モデルに付与できるという技術あります。
つまりこういうことですね。
ChatVector = Llama2-chat - Llama2
でChat能力を抽出し、
New-Model-chat = New-Model + ChatVector
でNew-ModelにChat能力を付与でき
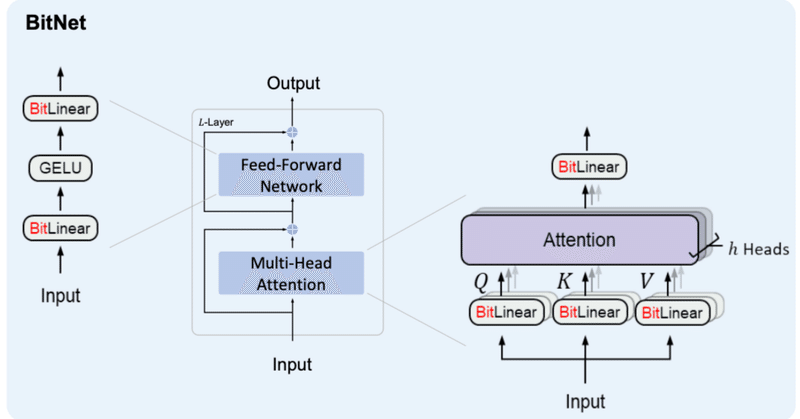
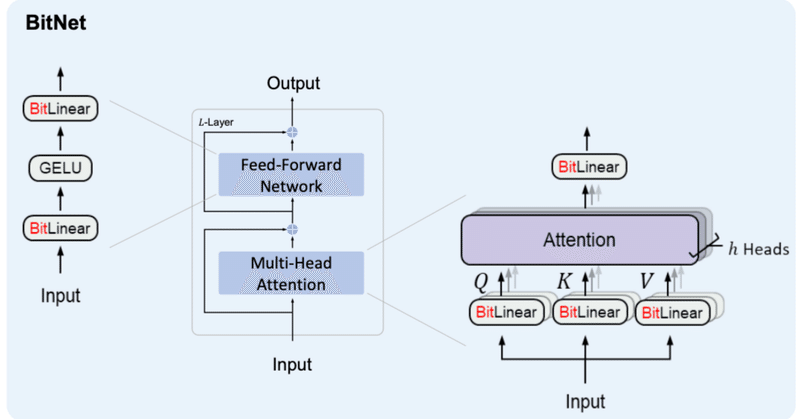
BitNet&BitNet b158の実装④
はじめに前回、BitLinear b158の実装を行いました。前回までの内容は以下をご参照ください。
4. BitNet b158の検証BitNetの検証と同様、
BitLlamaでBitLinear158bを利用できる様に修正
事前学習ができるか(Lossが下がるか)確認
を行います。
4-1. BitLlamaの修正
modeling_bit_llama.pyにおいて、BitLin
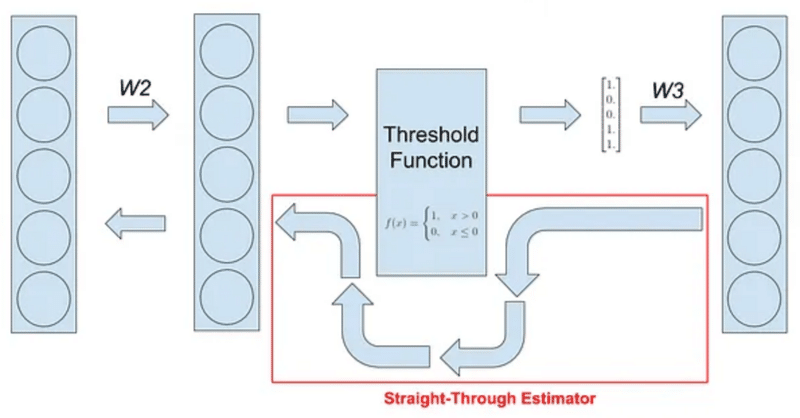
BitNetにおけるSTE(Straight-Through Estimator)の実装
はじめに現在、私は以下のような試みをしています。
BitNetとは
BitNetとはweightとactivationを量子化する手法の1つで、特にweightを{-1, 0, 1}の3値に量子化するBitNet b158はベースとしているLlama2の性能を上回ることを示し、注目を浴びました。
その実装の中で、量子化(つまりFloat16や32ではなくより離散的な値を扱う様にする処理)を行
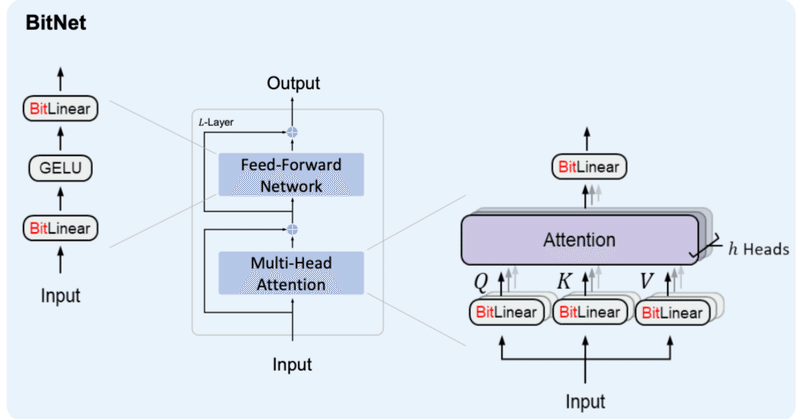
BitNet&BitNet b158の実装③
はじめにBitNetおよびBitNet b158の実装を続けていこうと思います。
ボリュームが大きくなってきたため、記事を分けることとしました。前回までの内容は以下をご参照ください。
2日連続での投稿となるので前後関係をお気をつけください。
3. BitNet b158これまでに作成したBitLinearを修正していく形でBitNet b158用のBitLinear b158を作成していきます。
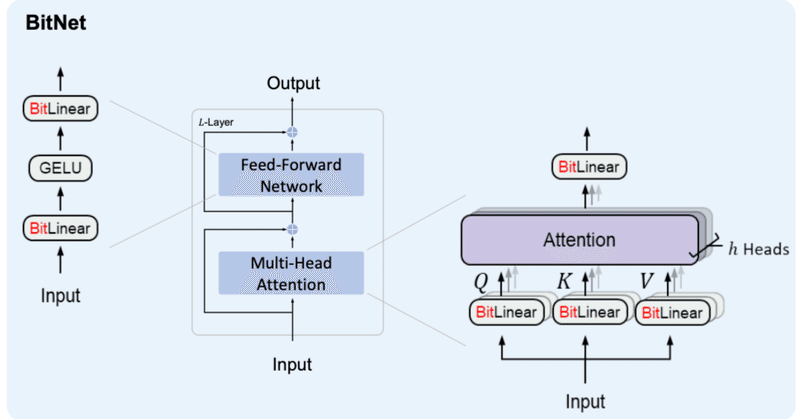
BitNet&BitNet b158の実装②
はじめに少し間が空いてしまいましたが、BitNetおよびBitNet b158の実装を続けていこうと思います。
ボリュームが大きくなってきたため、ページを分けることとしました。前回までの内容は以下をご参照ください。
2. BitNetの検証今回は、前回作ったBitNetの検証を進めていこうと思います。
検証内容としては、
BitLlamaの構築
事前学習ができるか(Lossが下がるか)確認
自作アーキテクチャのモデルをHuggingFaceにプッシュする方法
はじめに現在、私は以下のような試みをしています。
その中で、自作アーキテクチャ(Transformersに実装されていない)モデルをHuggingFaceにpushすると、当たり前ではありますがそのアーキテクチャでは重みをloadできないことに気づきました。
なので、
自作アーキテクチャ(Transformersに実装されていない)モデルをHuggingFaceにpush
できる限り簡単にA