人気の記事一覧
[Mac]Meta-Llama-3-8Bをgguf変換して量子化してみました
llama.cppでHuggingFaceモデルを4bit量子化😚【GoogleColab】/大塚
【動け!】ゲーミングノート vs ELYZA-13B量子化モデル【ローカルLLM】
Mac内のローカルで電子カルテ解析できますか? 〜日本語LLM(Swallow)を使ってみた〜
200Kトークン対応34BモデルNous-Capybaraをローカルで試す
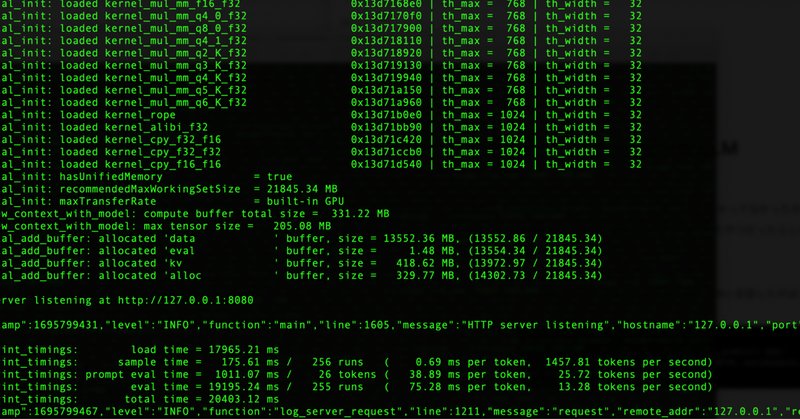
【llama.cpp】CPUとRAM、どっちが重要?
【llama.cpp】Qwen-14BをGGUF量子化して日本語で試す
【ローカルLLM】Gradioとllama-cpp-pythonで日本語チャットボットを作る
GGMLからGGUFへ:llama.cppのファイルフォーマット変更
rinna-youri-7b-instructionを作成済みの試験PGやAPIサーバ・クライアントで試す。
【ローカルLLM】llama.cppの「投機的サンプリング」を試す
【ローカルLLM】Colabの標準GPUで「CodeLlama-34B-GGUF」を動かす
Text Generation Web UI の利用の覚書メモ
youri 7b chat gguf(短期記憶あり)
GoogleColabでHuggingFaceのモデルをGGUFフォーマットに変換🔄/大塚
gguf版、elyza-japanese-7b-instでチャットモードで会話してみました。(短期記憶あり)