人気の記事一覧
大規模言語モデルをフルスクラッチする練習 (環境構築ー前処理ー事前学習ーファインチューニングー評価まで)
2年次では、進路ガイダンスの事前指導を行いました。【いわき総合】
大規模言語モデルの構築の事前学習に使えそうなデータセット(主に日本語系)の整理メモ
Chat VectorならぬMath Vectorは作れるのか
Chat VectorにならぬCode Vectorは作れるのか
6-4.ディープラーニングの詳細な説明(深層強化学習等)
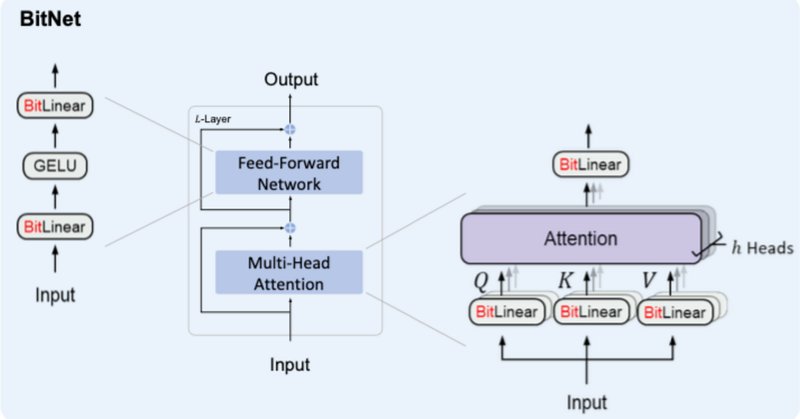
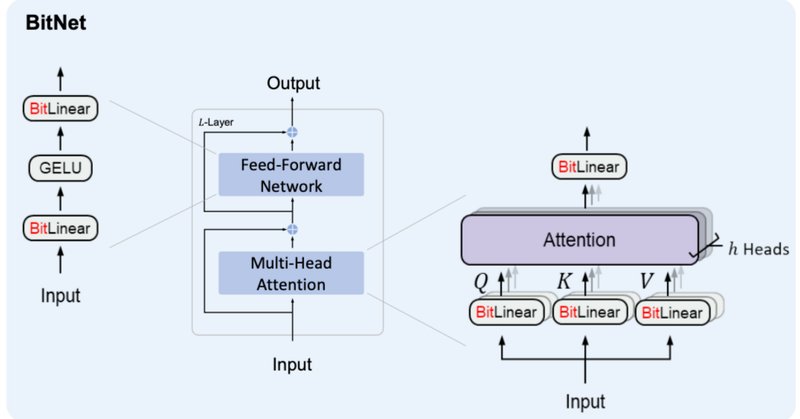
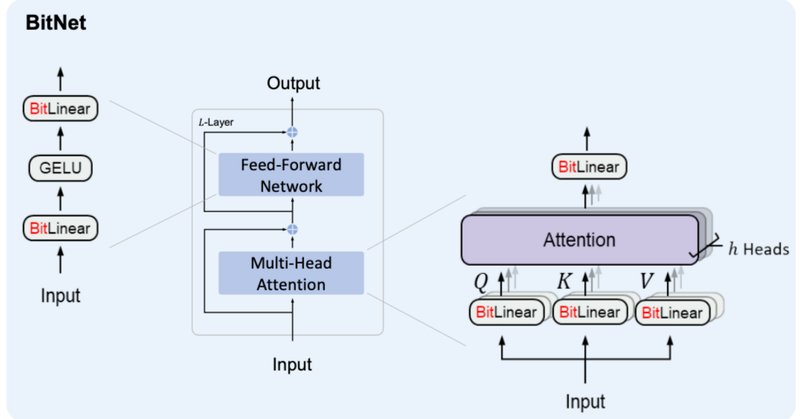
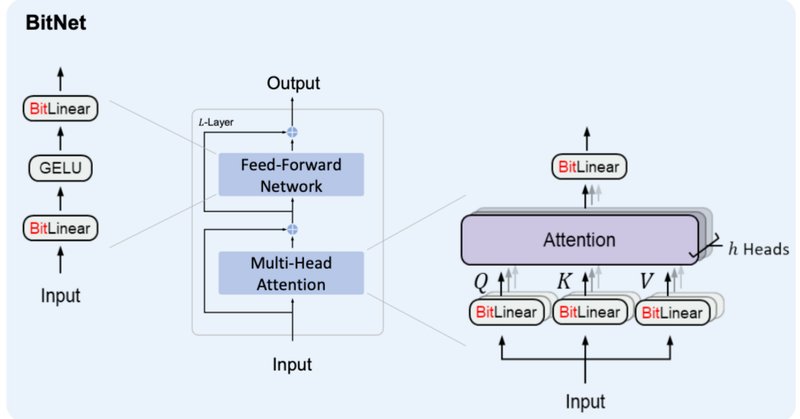
BitNetにおけるSTE(Straight-Through Estimator)の実装
Google Colabでの日本語Mambaの事前学習
パラメータ効率が圧倒的に高いLLM学習手法ReFT(Representation Finetuning)を試してみた。