
RNNとTransformerの要素を組み合わせた新しいアーキテクチャ: RWKVとは?

自分の勉強のために、RWKVの論文前半の仕組みの解説部分を、要約してみました。Transformerの考え方を踏襲しつつ、RNNのアイデアを取り入れたRWKVについて雰囲気をお伝えできれば幸いです。
なお、大事な論点の書き忘れ、認識間違いなどぜひコメントください。
背景・概要
トランスフォーマー技術は、ほぼ全ての自然言語処理(NLP)タスクを革新しましたが、取り扱うトークン数が長くなるほど、計算量・メモリへの負担が二乗に比例して急増する問題点がありました。
これに対して、従来の再帰型ニューラルネットワーク(RNN)技術は、文章の長さに関わらず一定の計算量の増加で済むものの、並列化が難しいことや、スケーラビリティの制限から、性能はトランスフォーマーに比べて、劣っていました。
今回提案された、Receptance Weighted Key Value(RWKV)は、トランスフォーマーの高性能と、RNNの計算効率を組み合わせたものです。
RWKVでは、線形アテンションzメカニズムを活用し、訓練時の計算を並列化を可能にし、推論を行う際の計算量は一定に保つことができます。このことで、数十億のパラメータにスケールできる初の非トランスフォーマーアーキテクチャを実現しました。
実験の結果、RWKVは同じサイズのトランスフォーマーと同等の性能を発揮することが確認され、これは将来このアーキテクチャを活用してより効率的なモデルを作成できる可能性が示唆されました。
この研究は、計算の効率とモデルの性能という、通常はトレードオフの関係にある二つの要素をうまく調和させることができる重要な一歩となっています。

1. 従来モデルの課題
従来から 自然言語処理に用いられている深層学習モデルには、色々な課題がありました。
RNN(LTSM, GRU含む)の課題
勾配消失の問題のため、長いシーケンスの学習が困難
学習時、時間次元が並列化できないためスケーラビリティが制限される
CNNの課題
局所的なパターンを補足することしか得意でない
多くのシーケンス処理タスクにとって重要な、長距離の依存関係に対処する能力が不足
Transformerの課題
ローカル依存性と長距離依存性の両方を処理できる能力、並列トレーニングの能力から、NLP分野でも大幅な進歩をもたらしたが、 Transformerの特徴である Self-Attentionメカニズムを用いる場合、トークン数が増えるとともに必要な計算資源が増大する課題がある

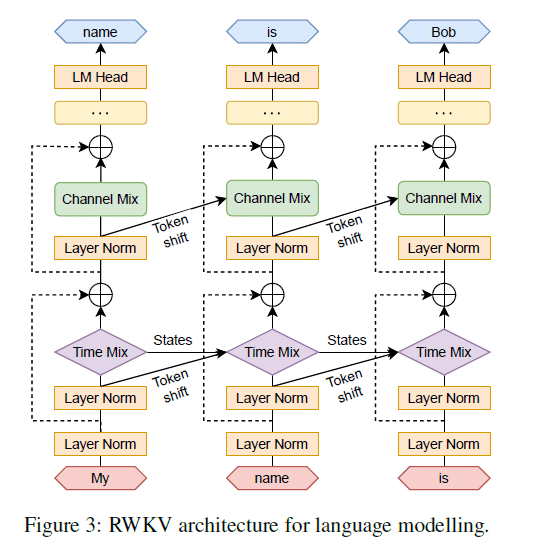
2. RWKV (Receptance Weighted Key Value)モデルの構造
2.1 RWKVを構成する4つのモデル要素
RWKVの「時間ミキシングブロック」および「チャンネルミキシングブロック」は以下の4つの要素で構成されています。
R: Receptance レセプタンス。過去の情報の受け止めを示すベクトル
W: Weight トレーニング可能なパラメータ。位置減衰ベクトル
K: Key TransformerのKに類似したアテンション用ベクトル
V:Value Transformerの Vに類似したアテンション用ベクトル
レセプタンス(Receptance):
レセプタンスは、RWKVモデルの一部で、過去の情報をどの程度「受け止める」かを示すベクトルです。これは、モデルが過去の情報をどの程度重視するかを調整する役割を果たします。レセプタンスは、不要な履歴情報を削除するための「忘却ゲート」としても機能します。
下図のように、タイムステップごと(同一タイムステップ内)の要素間の相互作用は乗算的になります。

RWKVアーキテクチャは、時間(タイムステップ)方向にスタックされた残差ブロックで構成され、時間ミキシングとチャンネルミキシングのサブブロックで構成されます。
2.2 時間ミキシングブロック(Time Mixing Block):
時間tに対して1 から (t-1) の区間の重みづけ加算[(14)式]を行って、その結果wkv_t にレセプタンス σ(r) を掛けます。算出される wkv_t は相互作用がスカラー間のものであるため、二次コストを発生させることなく線形のコストで Transformer のアテンション機構 (Q, K, V)と同等の役割を果たします。
なお、相互作用は、あるタイムステップ内では乗法的、他のタイムステップでは加算的になっています。

2.3 チャンネルミキシングブロック(Channel Mixing Block):
チャンネル間の情報を処理します。具体的には、1ステップ前の情報と重みのドット積を行い、その結果に活性化関数(例えばReLUの二乗)を適用します。これにより、各チャンネル間の相互作用が調整され、モデルの出力が生成されます。

なお、時間ミキシング、およびチャンネルミキシングでは、レセプタンスrをパラメタにするシグモイド関数を、不要な履歴情報を削除するための「忘却ゲート」として利用しています。
3. RWKVの特徴
3.1 Transformer のような並列化
RWKVはTransformerのように、いわゆる時間並列モードで並列化を行うことができます。単一層でシーケンスのバッチ処理する場合の計算量は、
O(BT d^2)で、主に r, k, v, oに関するWの行列計算で構成されます。
(B:シーケンス、 T: 最大トークン、d:チャネル)
チャネル数の影響は二乗オーダーになっていますが、通常、チャンネル数はトークン数より小さい値であるため トークン数の二乗オーダーで計算量が増大する Transformerと比べてアドバンテージになっています。
3.2 RNN のような逐次復号化
RNNでは、状態t の出力を状態t+1 の入力として使用することが一般的です。RWKVでは時系列モードと呼ばれるRNNに似た構造を利用します。RWKVは推論時の復号化のために再帰的に定式化することができるため、各出力トークンがシーケンスの長さに関係なく、サイズが一定の最新の状態のみに依存して推論を行うことで、一定の速度とメモリフットプリントを実現し、長いシーケンスをより効率的に処理できます。
これに対してセルフアテンション機構を用いる Transformerではシーケンスの長さにリニアに比例するKVキャッシュが必要となるため、シーケンスが長くなるにつれて効率が低下し、メモリフットプリントと計算時間が増加してしまいます。

まとめ
RWKVは、Transformerの高性能とRNNの計算効率を組み合わせた新しいアーキテクチャです。線形アテンションメカニズムを活用し、訓練時の計算を並列化し、推論を行う際の計算量を一定に保つことができます。これにより、長いシーケンスを効率的に処理し、数十億のパラメータにスケールできる初の非トランスフォーマーアーキテクチャが実現しました。
感想
いままでRWKVのコードを見ても、 再帰処理を活用しているとアピールしているわりにコード自体はTransformerっぽい雰囲気を感じるだけで、恥ずかしながら何を意図しているのか掴めてなかったのですが、時間ミックス、チャンネルミックスの機構で並列化を実現していることなど、論文で整理して説明してくれていて、かなり理解が進んだ気がします。
新しいアイデアを知るのは刺激的で楽しいですね。おしまい
この記事が気に入ったらサポートをしてみませんか?