Stable-Diffusionの学習設定まとめ

なんか学習設定について、よく分からんけどデフォルト!とかよく分からんけどこうしてみたらうまくいった!みたいな感覚で議論されていることが多い気がするので、学習設定についてまとめてみようと思います。機械学習のこと知らん人にも分かるようにするはずの記事でしたが多分そうなってないです。間違いもあると思いますが、私の記事が間違っていたとしても、悪いのは私よりも頭がいい人が分かりやすい説明をしないせいであって私のせいではありません。
機械学習の簡単な説明
機械学習はモデルの数値を学習データに合うように少しずつ調整していく作業です。なぜ少しずつかというと、機械学習では改善する方向はなんとなくわかるけど、最適な数値の位置は分からないからです。位置が分からないと適当に進んだら通り過ぎてしまうかもしれませんよね。改善する方向に少しだけ進んで、また方向を見直して少しだけ進む・・ということを繰り返します。
夜中目覚めて、トイレに行きたくなったとします。眩しいので明かりをつけずにトイレに向かおうとすると、方向はだいたいわかっても、距離感が掴みにくいですよね。そういうときは慎重に歩くと思います。少なくとも相当おしっこ我慢できない場合を除いてダッシュで向かう人はいないでしょう。機械学習も同じです。
機械学習で改善する方向をどうやって決めるかというと、実際に計算してみて出てきた結果が、学習データとどれだけずれているかを計算して、フィードバックを行います。するとだいたいこっちの方向行けばいいということがわかります。繰り返しになりますが、分かるのはある程度の方向だけでどこにいけばいいのかまでは分かりません。
機械学習領域でありがちな話をまとめておきます
データ量は多ければ多いほどいい(質を犠牲にしていなければ)
モデルがでかければでかいほどいいというわけではない(データ量とのバランスが重要)
学習すればするほどいいっていうわけではない(データ量とのバランスが重要)
GPUは並列計算が得意なので、たくさんのデータを同時に扱うとお得、だけどVRAM容量という制限がある。
機械学習共通の設定
学習率(learning rate)
学習率は夜中トイレに向かうときの1歩の大きさです。大きいとそれだけ早く学習が進みますが、壁にぶつかって痛っ!ってなる可能性も増えます。というか機械学習の場合は壁にぶつかるどころか、壁抜けバグが起きて亜空間に吹っ飛んでしまいます。逆に小さすぎるといつまでたってもトイレにたどり着かなくなってしまいます。たどりつかないどころか、途中でおしっこ漏らしてしまって、廊下がトイレになってしまうかもしれません。それが局所的最適解と呼ばれるものです(?)。
じゃあいくつにすればいいんじゃ!というと分かりません。プロですらいくつかの候補を経験則で選んで実際やってみてよさそうなの選ぶみたいな方法をとるしかありません。
学習率は一定にするのではなく、最初は大きくしてだんだん小さくするということもできます。それが学習率スケジューラです。ゴルフで一打目はドライバーを使って、グリーンに入ったらパターに変えるみたいな感覚です。
あと5e-6みたいな表記をみると思いますが、e-6というのは0が6つあるという意味です。0.000005ですね。小数点の左側の0を含みます。私は普通の学習は5e-6~1e-5、LoRAは1e-4~1e-3、ControlNetは1e-5~5e-5、PFGは1e-5にしますね。普段テキストエンコーダを学習することはないのでよく分かりませんが、テキストエンコーダはUNetの半分くらいの学習率にするといいらしいですね。
バッチサイズ

オンライン学習・・データを1つずつ学習
ミニバッチ学習・・その間
それなので正確にはミニバッチサイズと呼ぶべきだろと毎回思います
バッチサイズは1歩進むのに、いくつのデータを参考にするかという設定です。実は機械学習では一度に全部のデータを解析して、進む方向を決めるのではなく、1歩ごとに見るデータを変えながら進みます。それじゃあ進む方向がバラバラになるじゃないかと思うかもしれません。しかしデータがあまりにもバラバラでなければ、大まかな方向は変わりません。むしろ全てのデータを参照して、ここだあああああああと方向を1個に定めてしまうと、一回壁にぶつかった後壁に向かって歩き続けるNPCみたいになったりします。
大きくするとVRAM使用量が大きくなりますが、GPUは並列計算が得意なので、たくさんのデータを並列に扱える分学習速度は速くなります。そのため基本的にはバッチサイズは上げられるだけ上げた方がいいです。
ステップ、エポック
ステップは今まで説明した1歩のことです。イテレーションと呼ぶこともあります。エポックは学習データに1回ずつ目を通したときに1エポックと呼びます。
たとえば学習データが16枚あって、バッチサイズが4とします。1ステップごとに4つのデータを見るので、4ステップで全てのデータを見ることができます。つまりこの場合1エポック=4ステップです。
データセットの大きさによりますが、私はだいたい40エポックくらいやることが多いです。
mixed_precision

コンピュータは0と1で考える!とよく言われますが、機械学習では普通1個の数値を表すのに、32個の0,1列使います。そこで精度を下げても問題ない数値を16個の列にしてしまうことで、計算速度を大きくしたり、VRAM使用量を削減(例外あり)できたりします。精度は下がりますが、LoRAを作る分にはあまり問題にならないようです。通常はfloat16という方法を使いますが、扱える値の範囲が狭くなって、大きな値や、逆に細かすぎる値に対応できなくなります。そのため計算結果が大きくなって計算できなくなってしまう(これがNaNの意味です)とか、小さいから全部0ってことにしよう!となって学習が進まなくなる可能性があります。
bfloat16にすると扱える値の範囲はfloat32と変わりませんが、精度低下がさらに大きくなります。扱える値の範囲が広いことからfloat16より学習エラーや学習が進まなくなる可能性が低くなるのでこっちの方が安定感あります。とりあえずbfloat16にしとけばよくねと思っているのですが、マイナーな分対応していない機器や関数もありエラーの原因になりがちです。
full_bf16
mixed_precisionでは精度を下げてもあまり変わらない数値を16bitにすることで、学習時間や必要メモリ量を削減しました。full_bf16はそういったことをせず全ての数値をbfloat16にします。これによりさらなる効果が得られる代わりに精度も低下します。float16にするfull_fp16もありますが、こちらは対応する桁数の範囲が狭いためうまくいかないことが多いみたいですね。bfloat16に対応しているのは最新GPUなので、本当にこの機能が必要な雑魚GPUでは使えないというもどかしさがあります。
optimizer

https://arxiv.org/abs/2302.06675
簡単に言っちゃうと歩き方を決めるアルゴリズムです。工夫しないと左右に揺れながら歩いてしまうので、それを修正するものです。収束速度や精度、VRAM使用量に影響します。ただしVRAM使用量は更新対象のサイズに依存するので、LoRAのような小さいモデルを学習する場合はあまり変わりありません。
以下の記事がスーパーわかりやすいです。
AdamW
標準的に使われるOptimizerで、よく分かんなければこれを使えばいいという感じです。私はよく分かんないのでこれと下のVRAM節約版しか使ってないです。過去の更新の方向と大きさの二つを記録するため、更新対象の二倍余計にVRAM使用量が大きくなります。実はAdamWにはbeta1, beta2, weight_decayという設定項目があります。本家Stable Diffusionがデフォルトの設定で学習しているので、誰もいじっていないですが、変えてみたら面白いことできるかもしれません俺はやらんけど。
AdamW8bit
AdamのVRAM節約版で、更新履歴の精度を8bitします。通常は32bitなので、4分の1になります。AdamWでVRAM足らんくて困ったらこっちにしましょう。
Adafactor
こちらもAdamWのVRAM節約版であるほか、学習率を自動的に決定するという機能があります。といっても学習率に関わるような設定項目はあるので、LoRAの学習がデフォルトのままうまくのは奇跡なんじゃね思ってます。
詳しくは以下の記事で、理論的な部分は見なくていいですが、最後のまとめだけでも見てもらったら何か発見があるかもしれません。
Lion
がおー、僕の名前はライオンだぞ。正式名称はEvolved sign momentumっていうんだ。なんでライオンになったかって?僕にも分からないよ。ぼくは頭のいい人の思い付きで考えられたわけではなく、進化的アルゴリズムによって機械的に一番いい手法として見つけ出されたんだ。収束も早い上に、AdamWに比べて、覚えなきゃいけない更新履歴が半分で済むからVRAM節約にもなるぞ。ただしAdamWよりも学習率を低めにした方がいいんだって。よりVRAMを節約できるようになるLion8bitってのもあるぞ。
Dadaptation、Prodigy
学習率を自動で決定してくれるアルゴリズムらしい。Prodigyというのは進化版らしい(全然分かってない)。
gradient checkpointing

機械学習では、改善する方向を確認するために、実際に計算してみた結果と学習データのずれを確認して、フィードバックを行うと書きました。このフィードバックでは、途中の計算式も必要です。小学校のテストみたいですね。ただ途中の計算式をずっと持っていると、メモリが圧迫されてしまいます。そこで途中の計算式のうちいくつかのチェックポイントを除いて削除してしまいます。そして必要になったときはチェックポイントから再計算してフィードバックを行います。そのためVRAM使用量は削減されますが、計算時間は増加します。学習結果には影響を与えません。
※VRAM使用量が削減できるということは、バッチサイズを上げることができるので、GPUの並列計算能力を発揮できることにより計算時間が逆に早くなる例もあります。私の計測ではNVIDIA V100がそうなりました。性能のわりにVRAM容量が小さい、たとえばRTX4080とかも同じことが起きるんじゃないかな~とか想像しています。
gradient accumulation

バッチサイズは大きくすると、VRAM使用量が大きくなります。そのため超巨大スパコンを持っている人が、バッチサイズ5000兆でうまくいったよ!!!!といっても、我々庶民には再現できません。そこで学習データを1回観察した後、すぐに1歩進むのではなく、フィードバックの結果を1個ずつ足していきます。それを繰り返して最後に合計分を元に方向を決めます。これによって、小さいバッチサイズで大きいバッチサイズでのトレーニングをある程度再現できます。n回分繰り返すとn倍分のバッチサイズが再現できます。とはいってもさすがに5000兆は無理ですけどね。
この設定を丸パクリしたい!でもVRAMが足らない!って時に使うといいと思います。
Stable Diffusion限定の設定
次はSD(もしくは画像生成AI)だけの設定です。
v1 or v2
Stable Diffusionにはv1系とv2系がありますが、大きな違いは1つだけで、テキストエンコーダが別物になっています。それに対応するため、UNetの形もちょっとだけちがいます。
あとおそらくAttention head数の違いから、学習の速度が結構違うのですが、気にしているのは私だけなんですか?
XL
v1、v2と違ってモデル構造がかなり違います。
v_prediction(v_parameterization)
v1系やv2-base(512)系、XLはノイズがかかった画像からノイズを予測するモデルなのですが、v2-768系は実はノイズではなくvelocityというものを予測するモデルになっています。そのため学習時に使う計算式が少し変わります。論文読んでもよく分からないんですが、なんか数学的にきれいになっていい感じっぽいです。
Dreambooth(正則化画像)

あるキャラクターの画像を学習させるとき、モデルが元々持っている知識を利用するために、1girlといったタグを使いたいですよね。しかしデータ量が少ないとき、モデルはキャラクターの特徴だけでなく構図等の関係ない情報まで学習してしまいます。こうなると1girlの意味が歪められ、学習データに似たような画像しか生成できなくなってしまいます。
Dreamboothでは、sksに代表される意味のないトークンと、学習対象を説明するトークン(1girlとか)で生成した正則化画像を使います。sks 1girlでキャラクターを生成するよう学習しますが、それとともに正則化画像が1girlというプロンプトで生成できるように学習します。何を言っているんだ?という感じですが、これは要するに1girlというプロンプトで生成した結果が学習前後で変わらないようにしています。これによってモデルが学習データによって歪められることを防いでいます。
prior_loss_weightによって正則化画像の学習の強さを調整できます。
※正則化とは過学習を防ぐためにモデルの学習能力をわざと制限することを言います。今回は正則化画像によって、モデルが1girlの意味まで学習してしまうことを防いでいるわけですね。
Textual Inversion
簡単にいうと新しい単語を追加する手法です。プロンプトはトークナイザーというもので、トークンという単位に分けられます。このトークンはテキストエンコーダーに渡され、トークン埋め込みベクトルに変換されます。トークンは5万種類くらいあるんですが、そこに新しいトークンをいくつか加えます。そしてそのトークンにふさわしい埋め込みベクトルを、画像データを参考に作っていくわけです。単語を増やすだけでモデル自体はほとんど変わらないので元のモデルの能力を失わずに学習できるところが利点です。その代わり表現力は低いですね。
Aspect Ratio Bucketing
NovelAIが紹介した方法で、複数のアスペクト比で学習できる方法です。といっても仕組みは単純で、いくつかの解像度候補(Bucket)を選び、各画像を一番近いBucketの解像度にリサイズ・トリミングをするだけです。学習時は各ステップごとにBucketを選び、そのBucketのデータをバッチサイズ分集めて計算します。
Stable Diffusionは任意の解像度に対応していますが、複数のデータを並列に計算する場合は、解像度を合わせる必要があります。そのためBucketを作ってステップごとに同じ解像度のデータが集められるようにしています。

詳細設定(Kohyaさんの設定名に従う):
max_resolution:Bucketの最大ピクセル数です。
min(max)_bucket_reso:Bucketの最小(最大)幅です
bucket_reso_steps:64を指定すると解像度が64の倍数になります。VAEで8分の1、UNetで8分の1になるので、基本的に64にした方が良いと思います。
Bucketは、幅(もしくは高さ)を64ずつ動かしながら、max_resolutionを越えない最大の高さ(もしくは幅)を決めます。その幅、高さがBucketになります。また人為的に正方形もBucketに加えます。
※Waifu-diffusionのチームがやっている方式は全然別物だったりします、詳しくはこちら。
CLIP-skip
これもNovelAIが紹介した手法です。CLIPとはテキストと画像の関係性を繋げるようなモデルです。テキストと画像をそれぞれ別のエンコーダで数字の列に変えて、テキストと画像間で関係があると似たような列になるよう学習されています。Stable Diffusionでは一部の手法を除き、テキストエンコーダのみが使われます。NovelAIはテキストエンコーダの最終層の状態ではなく、1個手前の状態を使うと性能が良くなると発見したらしいです。私の想像ですが、テキストエンコーダは純粋なテキスト表現からだんだん画像と共通の情報だけ抜き取るような処理を行っていくと想像できるので、最終層からさかのぼればさかのぼるほど、テキストには忠実だが、画像との関連性が薄くなっていくんじゃないでしょうか。NovelAIのようなdanbooruタグ列挙プロンプトを使っていると高度に抽象化された情報より生のテキストに近い情報の方があっているのかな?この辺の話詳しく書いてあるものとかってあったりしますかね。
SDv2では最初からCLIP skipを適用した状態で学習されています。モデルも最終層がない状態でアップロードされているため何も設定していないなくても適用していることになります。
トークン長の拡張

対応するトークン長を75から225とかに拡張するやつですね。Stable Diffusionで使われているテキストエンコーダは、77トークンしか対応しておらず、先頭と末尾に特殊なトークンが必要なので、実際に使えるのは75トークンまでです。しかしUNetはトークン数に制限はないので、テキストエンコーダを3回使ってつなげれば、225トークンにできます。この流れから分かる通り、1~75トークンと76~150トークンなどの間で単語間のつながりがなくなってしまいます。webuiではこれに対応するためにBREAK構文で区切る場所を指定したりできますね。ただ学習時にトークン長の拡張をすると、長いプロンプトを使わないといい画像がでてこなくなって、よくないのではと個人的には思っています。まあ私が普段長いプロンプトを使わないからそう思うだけかもしれません。
キャプションのドロップアウト
学習時、キャプションを一定確率で空文にしたり、一部削除したりします。実は拡散モデルでは、分類器無し誘導という手法のために空文での生成を学習する必要があります。ただしこれは一からStable Diffusionをつくるとか、Waifu-diffusionみたいな大規模の学習でやらなくてはいけないことであって、小規模の学習にはあまり関係がないと思います。私も前やってましたが、効果あるんですかね・・・?
ステップ範囲の制限
学習時のノイズ強度の範囲を制限します。0から1000まで選べて0がノイズが全くない状態、1000はほぼ完全なノイズの状態です。たとえば最小が0、最大を500にすると、ノイズが少ない状態でのみ学習するのでスタイル等細部を学習したいときいいのかもしれません。
cache latents
Stable DiffusionではVAEによって画像を潜在変数と呼ばれる元の情報よりも小さいものに圧縮したあとに、学習や生成を行います。学習中に必要なのは、潜在変数だけで元の画像はいらないので、あらかじめ学習画像を潜在変数に変換しておくことで、学習を効率化させることができます。VAEによる潜在変数への変換は決定的ではなく、平均と分散を出力してからサンプリングをするので、その結果をキャッシュしちゃってええんか?とも思ってますがまあええやろ・・・。
noise_offset
従来の学習法だと暗い画像や明るい画像がでにくいようです。Stable Diffusionではノイズ付きの画像からノイズを予測するよう学習しますが、このノイズは明るすぎず暗すぎないちょうど中間くらいになるようにしてあります。3とか4ばっかり出てくるサイコロみたいなもんです。そのため生成時にノイズを除去していく過程でも、明るくも暗くもない画像を生成するようになっていきます。noise_offsetでは学習時に明るいノイズや暗いノイズを加えるようにすることで、モデルが明るい画像や暗い画像を生成できるようにします。という理解でいいのかな・・・・?
SDXLではついに公式に採用されました。すごいですね。
よく分からんが以下の記事よりうまく説明できる気がしないのでリンク貼ります。
Min-SNR Weighting
SNRとは信号対雑音比というものでようするにノイズがどれくらい大きいかという指標です。値が小さいほどノイズが大きく、0だとただのノイズになります。このSNRを使って損失関数を操作する方法です。
以下は損失の大きさグラフです。横軸は時刻で、右にいくほどノイズが大きくなります。青の線がmin-snrで、途中で紫の線と被ってますが、ここの部分は要するに変わらないということなので気にしなくていいです。ノイズの小さい状態での損失を下げることで、あまり細部を気にしない学習になるんでしょうね。

xformers、sdpa
どちらもメモリ効率化・高速化する設定ですね。トラブルが起こりやすいことを除いて、設定しない理由はないですね。仕組みはよく分かりません。私が教えて欲しいくらいです。sdpaはPytorch2.0で実装された関数のことで、scaled dot product attentionの略です。これは高速化手法の名前とかではなく前からある機械学習用語です。xformersもtransformersにかけてるだけだと思うので、この二つは名前から特長が想像しづらいですね。
Token Merging(ToMe)
通称東名高速
現状Kohyaさんのコードで実装されていないので誰もやらないと思いますが、私が割と注目しているので書いておきます。簡単に言うと画像のピクセル値が近いもの同士をマージしてしまうことで、計算量を削減する方法です。ここでいう画像とはモデルの計算途中の情報であって、元の画像ではないです。学習にも生成にも使える手法です。
私が実験してみた結果を貼ってみます。結果に大きな変化もなく計算速度3割増、VRAM使用量2割減を実現できています。ただバッチサイズや解像度が大きくないと効果が薄いっぽいので、しょぼいGPUだとあまり意味がないかもしれません。
モデル構造的にSDXLには向かないかもしれません。
EMAモデル
これもKohyaさんの訓練コードにはないですが、昔よく使われていたCompVIs版の訓練コードにありますし、diffusersでもたしか実装されているので書いておきます。EMAとはパラメータの指数移動平均のことです。株価みたいなギザギザしたグラフを滑らかにして大まかな推移をみるためのものです。大規模なデータを学習するときは、1エポックの中で最初の方に取り出されるデータと、最後の方に取り出されるデータで偏りが生じてしまいますよね。そこで学習の最終結果を使うのではなく、過去との指数移動平均をとったモデルを使うことで、バランスをとっています。小規模なデータでこれを行うと、むしろ未学習になってしまうので普通の人が使うことはないです。また過去の情報をとっておかないといけないことから、VRAM使用量も上がります。
LoRA関連
LoRAんど「Stable Diffusionの歴史は二つに分けられる。
俺以前か、俺以後か。」
LoRAはモデルにネットワークを追加して、そのネットワークだけ学習することで、VRAM使用量を抑えたり、学習が早くなったり、学習データに過度に適合してしまうことを避けることができる方法です。さらに元のモデルにマージできるという長所があります。
rank(=dim)
LoRAの大きさです。大きければ大きいほど表現力が高まりますが、機械学習ではありがちですが、大きければいいってもんでもありません。実はLoRAの数ともとらえられます。数式的には、たとえばrank=16のLoRAはrank=1のLoRA16個分の合計として書くこともできます。
この辺りの話は以前書いた記事と関係しています。
線形代数に抵抗がない人向けに書くと、upを列方向に分割、downを行方向に分割するとrank個のLoRAを並べて内積を取ったような形になります。
$${AB = (A_1 \cdots A_r)(B_1 \cdots B_r)^T = \sum A_i B_i}$$
alpha
LoRAにかけられる重みです。計算するときはLoRAの結果にalphaが掛け算されます。webuiの拡張等ではLoRAのweightを調整する機能があるのに、なぜこんな設定があるのでしょうか?
rankの項で説明した通り、rank=16のLoRAはrank=1のLoRAが16個あると考えられます。するとモデルに与えるインパクトは16倍になりますよね。そうなると歩幅も16倍長くなってしまいます。これを修正するためには、学習率を16分の1にする必要があります。ただしrankを変えるたびに学習率を調整するのは面倒ですよね。そこでLoRA側で結果をrankで割る処理を行うことで学習率を変えずに済むようになっています。rankで割ったら効果が薄くなってrank=1と同じになってしまうじゃないかと思う人もいるかと思いますが、rank個分のLoRAが別々の機能を果たすため、表現力はあがっています。
この設定は実はKohyaさんの訓練コードには最初導入されていませんでした(元のcloneofsimo氏のリポジトリも同様)。導入されたきっかけは、上で書いた学習率の話ではなく、float16にしたときの学習に問題が発生したからです。繰り返しになりますが、LoRAはrank個分のrank=1のLoRAの合計として考えられます。rankが大きいとき、各LoRAは他のLoRAに配慮して、控えめな数値を持つようになってしまいます。数値が控えめになると、float16で扱える最小の数値を越えてしまい、全部小さいから0でヨシ!となってしまい学習が進まなくなります。そこでrankで割ることによって、逆にLoRA側は大きい数値を取るようになって、これを防ぐことができます。rankで割れば解決!とはなるんですが、今まで使ってきた人にとっては、いきなりrankで割られるようになると学習設定を変えなければいけなくなってしまいます。そこでalphaという、LoRAに掛ける数値の設定を追加することで、rank=alphaにすれば今までの学習設定と同じになるよね、ということで追加されました。
今までの話から分かる通り、alphaは基本的に固定するものです。少なくともalphaの調整は学習率の調整とセットで考えるべきものです。alpha = rank/2にするといいみたいな話もあるみたいですが、どこからきたんでしょうか?
ちなみにLyCORISのリポジトリにはdyLoRAの場合はalpha = rank/4~rankにするといいと書いてあります。dyLoRAは各ステップで1個分のLoRAしか学習しないので、上の議論からすればalpha=rankにするのが自然じゃないですかね。
階層別学習率

私はこんなことやりたくないですが、階層については記事を書いているので興味があったらご覧ください。ただ学習率を0にして学習対象に含めないみたいなこともできるらしく、UP層のみを学習するみたいな手法もできるので、これは興味あります。というかUP層のみの学習は学習時間やVRAM使用量を削減できてかなり有望だと思うんですが・・・。
LoCon(LoRA-C3liar)
LoRAの学習範囲を拡張します。UNetには大域的な情報を解析する層(Self Attention)、テキストとの関連性を解析する層(Cross Attention)、局所的な情報を解析する層(ResNet)の3つに分かれます。通常のLoRAは3つ目について学習しませんが、これを学習するようにしたのがLoConです。色々な論文でファインチューニングに重要なのはCross Attention>Self Attention>ResNetであると実験結果が出ているみたいなので、効率が良いかというと微妙ですが、スタイルLoRAのように細かい表現を学習したい場合はLoConを使うのが良いのかもしれません。
SDXLでは、ダウンサンプルされない一番解像度が大きい層で、Attention層が取り除かれているため、LoConにした方がいいかもしれません。そもそもSDXLはAttention層の比率が大きいため、LoConにしてもあまりファイルサイズは大きくなりません。
Loha
LoRAを二つつくってアダマール積を取ります。線形代数が分かれば理解できます。普通のLoRAのランクに対してルートを取ったものを設定するのがよさそうです。
Lokr
Lohaのクロネッカー積バージョンです。2つの行列のクロネッカー積の階数は2つの行列の階数の積になるので少ないパラメータ数で階数の上界を上げることができます。
dyLoRA
?「ワシのLoRAは百八式まであるぞ」
rankが高ければ高いほど性能が良くなるわけではないことは何となくわかると思います。rankが高すぎても学習データに過度に適合して、生成画像の多様性がなくなるといったことが起きます。当然低すぎてもだめです。今回とりあえずrank<=108に限定するとします。1~108までの全てのrankで学習すれば、どのrankがいいか比較することができますね。しかしこの方法では108回も学習する必要があります。dyLoRAではステップごとにrankを変えながら学習することで、1~108までの全rankのLoRAを同時に学習することができます。
rank=108のLoRAは、rank=1のLoRAが108個あると解釈できます。そこでそれらを1~108番まで番号付けしておきます。そして1~k番目までのLoRAの組がrank=kのLoRAになるように学習します。するとk=1,..,108まで動かすことで各rankのLoRAが取り出せるようになります。
学習時に各ステップで1から108までの適当な数字を決めます。とりあえずkとしておきましょう。次に1~k番目のLoRAのみを用いて計算し、フィードバックをしてLoRAの数値を調整します。ただしこのときk番目のLoRAの値のみを調整します。つまり1~k番目のLoRAで計算したときのずれをk番目のLoRAのみに調整させるようにします。どうしてk番目のLoRAのみを調整するのでしょうか?1~k番目のLoRA全てを調整してしまうとどのようなことが起こるでしょうか。1番目のLoRA視点から見てみましょう。1番目のLoRAは自分自身のみでrank=1のLoRAになるような使命を与えられています。つまり自力で全部解決してやるぞ!とやる気まんまんです。それなのに、1~k番目のLoRAで計算した結果のフィードバックを受けてしまうと、他のLoRAの情報を参考にしてしまうことになります。これではrank=1のLoRAを再現していることになりませんよね。次に2番目のLoRAを見てみましょう。こいつは1番目のLoRAとペアを組むことで、rank=2のLoRAになれと指定されています。つまり参考にしていいLoRAは1番目のLoRAのみです。そのため1~k番目のLoRAを使った計算結果は参考にできません。3~k-1番目のLoRAも同様ですね。そのためk番目のLoRAのみが調整する対象になります。
ちなみに1個ずつではなく2個ずつとかで分割してもいいです。それを決める設定がunitです。
LoRAの抽出
特異値分解を用いて、LoRAを抽出することができます。特異値分解とは任意の行列に対して行える分解法で、$${W = U\Sigma V=\sum \sigma_i U_i V_i}$$です。ここで$${\Sigma}$$は特異値$${\sigma_1, \cdots \sigma_n}$$が並んだ対角行列になります。特異値を大きい順に$${r}$$個選んで、それ以外の項を無視すると、rank=$${r}$$のLoRAに近似できます。
LoRAのマージ・リサイズ

使うときにデータ量を増やさずモデルにマージできるのが、LoRAの最大の特徴です。ただLoRA同士は単純な足し引きによってマージすることはできません。$${AB + CD \neq (A+C)(B+D)}$$になります。精度が下がってもいいなら$${AB+CD}$$をそのまま特異値分解することでマージができます。またモデルサイズ大きくなりますが、upを列方向に、downを行方向結合すれば完全なマージができます。$${(A C)(B D)^T=AB+CD}$$ですね。この方法は最近sd-scriptでも採用されました。というか私が実装したんですけど。
リサイズは$${AB}$$をそのまま特異値分解するだけですね。rankの決め方は普通に設定する方法の他に、特異値の分布に基づいて自動決定する方法もあります。決定の仕方には最大特異値の大きさを基準にするものや、特異値の累積和・二乗累積和を使うものがあります。数学的には二乗累積和(=フロベニウスノルム)を使うのが一番正しいみたいですね。
Dropout
ドロップアウトとは、ネットワークに与える情報をわざと落とすことで、モデルの頑健性を上げる方法です。わざと酸素が少ない状況で走ったりする高地トレーニングのようなものですかね。過学習を抑える効果がありますが、その一方学習速度は遅くなるかもしれません。ドロップアウト自体はLoRAと関係なく一般的に使われる手法ですが、Stable-Diffusion関連では今のところLoRAでしか使われていないかも。Kohyaさんが実装したドロップアウトは3種類あります。設定はすべて0にする確率になります。
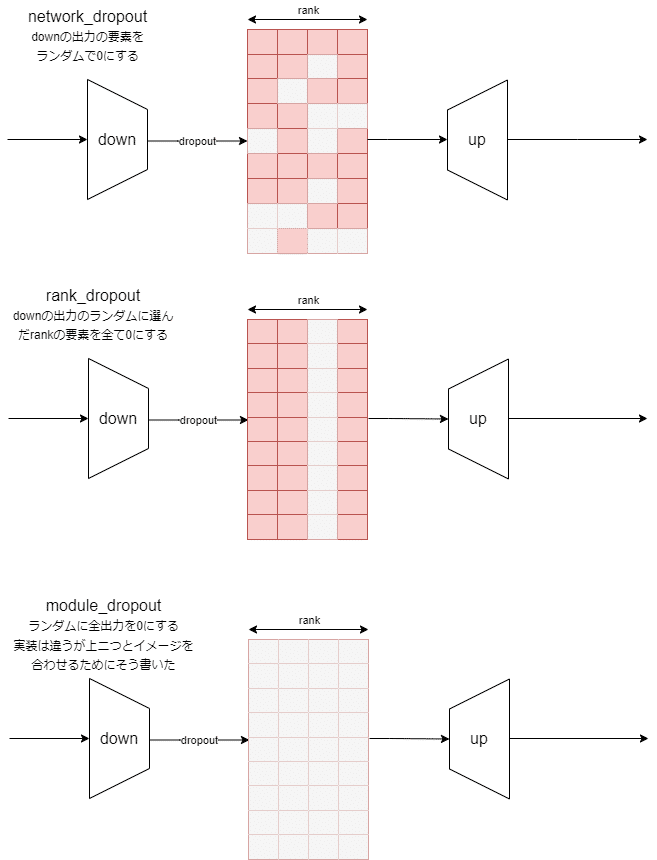
network_dropout:これが通常のドロップアウトです。 過学習を抑えたいときはとりあえず設定してみるといいかもしれません。
rank_dropout:rank方向にドロップアウトします。これはたとえば4などの少ないrankで学習するときに設定するとdropoutの影響が強くなりすぎて良くないかもしれません。たぶん高rankのLoRAを使うときにおすすめです。
module_dropout:ぱっと何の意味があるかわかりませんが、ある階層のLoRAが弱くなっても性能が落ちづらくなるため、階層別のLoRAを利用しやすくなるかもしれません。ただ逆に階層ごとの役割分担があいまいになってコントロールしづらくなるともいえるかも?
参考記事
シングルGPUによる学習の高速化手法についての話が網羅されています。Transformersの話なので最初の方はStable Diffusionと関係ありませんが、手法自体は共通です。