マガジン

記事一覧

【Xcode】ローカルLLMをiPhoneの実機で試した!!
前回の記事の続きです https://note.com/flymywife/n/nf898cff3fb6e 上記の記事を参考に実機テストができました(^^) iPhoneをプライバシーとセキュリティからデベロッ…


MacStudio(M2MAX96GBユニファイドメモリ)の推論能力
推論能力を測定してみました。 gradioで、モデル切り替えて遊べる環境を作ります! こちらのリポジトリにgradioのソースコードを置いておきます https://github.com/flymyw…



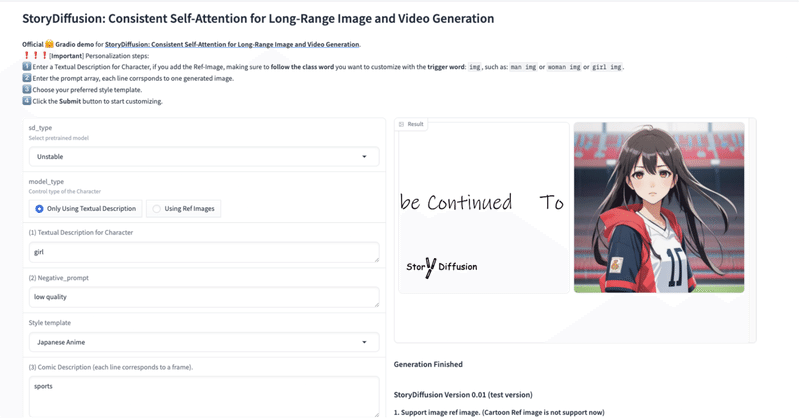
StoryDiffusion動かしてみた
↑
無料で漫画生成できるみたいなのでやってました!
まず導入から使ったことないanaconda入れたり大変でした
その後
pip install -r requirements.txt
に書かれてるバージョンがあってなかったり
Claude 3 Opusに聞きまくりながら
必要なものbrew installしました
その後
python app.pyして
Macだからcuda使えないからcpuに
![[Mac]Dockerでmysql立ち上げてみた](https://assets.st-note.com/production/uploads/images/140848148/rectangle_large_type_2_01d1a520588157c4f80e706d907673a5.png?width=800)
[Mac]Dockerでmysql立ち上げてみた
参考記事
とりあえずDocker run するとこまではできたけど
ターミナルで
mysql
と打っても入れないからClaudeに聞いてみたらこれを打てと
docker exec -it <CONTAINER_NAME or CONTAINER_ID> bash
<CONTAINER_NAME or CONTAINER_ID>の箇所はコンテナ名が
some-mysqlなら
docker
![[Mac]Meta-Llama-3-8Bをgguf変換して量子化してみました](https://assets.st-note.com/production/uploads/images/140358057/rectangle_large_type_2_ef166d5f13a6e81839b531a000442ea0.png?width=800)
[Mac]Meta-Llama-3-8Bをgguf変換して量子化してみました
上記のモデルを自分で量子化してみました。
参考にした記事
基本的な流れは上の記事の通りですが
convert.pyを実行すると
ずっと
ValueError: unknown format: models/Meta-Llama-3-8B/model-00001-of-00004.safetensors
というエラーが出ていて泣きそうになってました
safetensorsのファイルの中身を見て

Mac StudioでComfyUI使ってみた
上記の記事を参考にMac StudioでComfyUIt使ってみました
記事の流れ通りにvenv作ってライブラリインストールしてクローンして、
すぐできました!
CheckpointがUndifinedなので以下の記事を参考に進めました
StableDiffusionV1.5を入手して、
Queue Promptを押下すると…
以前レンタルしてたPCはVRAMが8GBしかなくてよくアウトオ

話題のArrowPro-7B-KUJIRA の量子化モデル使ってみました
ArrowPro-7B-KUJIRA15歳の高校生がMistral7BをベースにAITuberで使えるように日本語能力世界一のモデルを作ったそうです。
すっげ
そのモデルのggufの量子化モデルが上がっていたので使ってみます↓
https://huggingface.co/MCZK/ArrowPro-7B-KUJIRA-GGUF
量子化モデルなんで日本語能力世界一のモデルよりいくらか劣化する

Fugaku-LLM-13B-instruct-gguf 試しみた
スーパーコンピューターで開発したという日本語LLM
富岳の13B量子化モデルを試してみます。
[リクエスト]
./main -m ../LLMModels/Fugaku-LLM-13B-instruct-0325b-q5_k_m.gguf -n 200 -ngl 38 -t 10 -p "あなたは誰ですか?" --ctx_size 512
[レスポンス]
<s|LLM-jp> あなたは誰です
【Xcode】ローカルLLMをiPhoneの実機で試した!!
前回の記事の続きです
https://note.com/flymywife/n/nf898cff3fb6e
上記の記事を参考に実機テストができました(^^)
iPhoneをプライバシーとセキュリティからデベロッパーモードにしたり
llama.cppが読み込めない原因が信頼ボタンクリックしたりしましたが
なんとかできました!
当方iPhone SE3であります!
19 token/s は思った

llama.cppのexampleで遊んでみた→XcodeでiPhoneプレビューでローカルLLMを動かす
llama.cppをクローンしたときにexampleというフォルダが入っていて
ここにお試しみたいなアプリが入っています。
その中の
こちらをXcodeでビルドして遊んでみました。
View Modelsをタップしてみましょう
ちなみに生成速度でてますが108 token/seconds
ってめちゃめちゃ早いです
僕のM2MAXのパワーで出ているので
実機で試すとどのくらいのスピードになるか

MacStudio(M2MAX96GBユニファイドメモリ)の推論能力②
llama.cppを使いGPUを開放する術を身につけました
Llama 3 8B-Instruct GGUFQ4K_M
【リクエスト】
./main -m ./LLMModels/Meta-Llama-3-8B-Instruct.Q4_K_M.gguf -n 512 -ngl 38 -t 10 -p "" --ctx_size 512
【結果】
llama_print_timings: loa
MacStudio(M2MAX96GBユニファイドメモリ)の推論能力
推論能力を測定してみました。
gradioで、モデル切り替えて遊べる環境を作ります!
こちらのリポジトリにgradioのソースコードを置いておきます
https://github.com/flymywife/LLMSpeedTester
Meta-Llama-3-8B-Instruct.Qa_K_M.gguf
Elapsed time: 27.71 seconds
Tokens per sec

Claude3:Macでvenv環境
user:MACでvenv環境を作ってその環境にライブラリを入れたい
Claude3Opus:MACでvenv環境を作成し、その環境にライブラリをインストールする手順は以下の通りです。
ターミナルを開きます。
プロジェクトのディレクトリに移動します。
cd /path/to/your/project
次のコマンドを実行して、新しい仮想環境を作成します。
python3 -m venv

Mac Studioが届いた!
やったぜ!
M2MAXユニファイドメモリ96GBのMac Studioが届いたぜ。
意外とでかい。
アップルショップから持って帰ったけどカバンにちゃんと入りきらなかった。
Windowsで使ってたキーボードとかマウスとかは使える。
ちょっと使い心地は違う。
例えば全角入力切り替えはCtrl + space だったりする。
多分慣れれば大丈夫。
あとWindowsより予測変換めっちゃしてくれる。
Scalaめっちゃいい