どれくらいスピードアップしたのか

本記事はFireDucksユーザー記事シリーズの第7弾です.本記事はBell様に執筆して頂きました
はじめに
本記事では、Import を書き換えるだけで高速化できる、Pandas 互換のライブラリ FireDucks について、過去の検証を参考にして、速度とメモリ使用量についてどれくらい改善しているのかを検証してみたいと思います。なお、上記記事にあるモデルの訓練の検証については実施しておりません。
環境
下記のような環境で実行しました。
ubuntu-22.04.3 CPU: Intel(R) Core(TM) i7-6800K CPU @ 3.40GHz 3.40 GHz RAM: 64 GB
FireDucksの本記事執筆時の最新のバージョン0.10.2と、過去検証記事で使用されていたバージョン0.8.2の2つのバージョンで検証しています。
検証用のコード
検証用のコードについては過去の検証中に記載のコードをそのまま使用させてもらいます。
通常のpandasとの違いはimport文を import pandas as pd からimport fireducks.pandas as pdに変更するだけです。今回は検証用に_evaluate()をつけて即時実行するようにしています。
別の実行方法もあり、ここにあるベンチマークモードを使うと_evaluate()を使った時と同様の結果が得られます。その際にソースコードは下記のようになります。
ベンチマークモードのコード例
import fireducks.pandas as pd
import numpy as np
import time
from fireducks.core import get_fireducks_options
get_fireducks_options().set_benchmark_mode(True)
def create_random_dataframe(N):
return pd.DataFrame({
'A': np.random.randn(N),
'B': np.random.randn(N),
'C': np.random.choice(['X', 'Y', 'Z'], N),
})
def perform_filtering(df):
start_time = time.time()
df_filtered = df[df['A'] > 0.5]
print("pandas filtering:", time.time() - start_time)
def perform_groupby(df):
start_time = time.time()
grouped = df.groupby('C').mean()
print("pandas groupby:", time.time() - start_time)
def perform_sorting(df):
start_time = time.time()
sorted_df = df.sort_values(by='B')
print("pandas sorting:", time.time() - start_time)
def perform_join(df):
start_time = time.time()
df1 = df[['A', 'B']].copy()
df2 = df[['C']].copy()
joined_df = df1.join(df2)
print("pandas join:", time.time() - start_time)
def perform_fillna(df):
start_time = time.time()
df_na = df.copy()
df_na.loc[df_na.sample(frac=0.1).index, 'A'] = np.nan
filled_df = df_na.fillna(0)
print("pandas fillna:", time.time() - start_time)
def perform_dropna(df):
start_time = time.time()
df_na = df.copy()
df_na.loc[df_na.sample(frac=0.1).index, 'A'] = np.nan
dropped_df = df_na.dropna()
print("pandas dropna:", time.time() - start_time)
def perform_calculation(df):
start_time = time.time()
df['D'] = (df['A'] + df['B'])
print("pandas calculation:", time.time() - start_time)
def main():
N = 50000000
df = create_random_dataframe(N)
perform_filtering(df)
perform_groupby(df)
perform_sorting(df)
perform_join(df)
perform_fillna(df)
perform_dropna(df)
perform_calculation(df)
if __name__ == "__main__":
main()測定結果
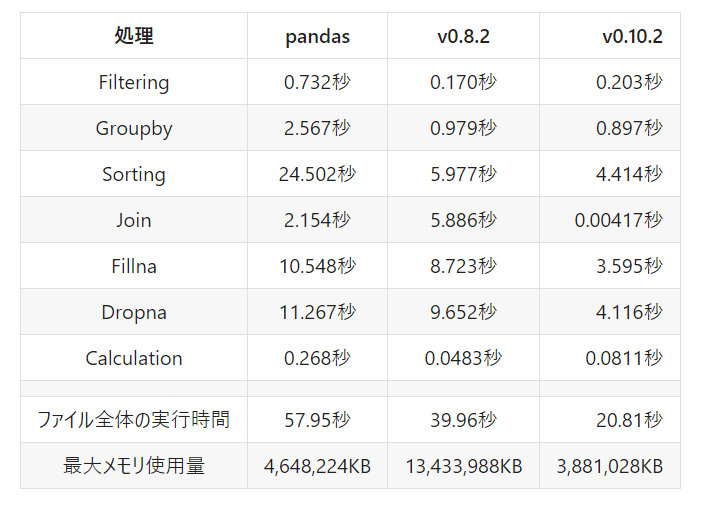
測定結果は下表のようになりました(過去検証記事と環境が違うことも考慮してpandasの測定結果も掲載しています)。 Filtering, Groupby, Calculationについてはバージョン0.8.2とほぼ変わらない結果となりました。一方でSortingに関しては20%ほど高速化、Join, Fillna, Dropnaに関しては数倍以上の劇的な高速化を成し遂げています。
ちなみにJoinが他の処理と比べて非常に高速化しているのは、同じRangeIndexを持つ二つのテーブルを横につなげるだけの処理になっていて,単純にテーブルをつなげるだけの処理にしているためだと考えられます。また公式ページによると、merge/joinの結果の行の順序がpandasと違っている場合があるとのことなので、使用の際には注意が必要です。
メモリに関してはバージョン0.8.2から大幅に改善していて、pandasと比較しても少なくなっています。
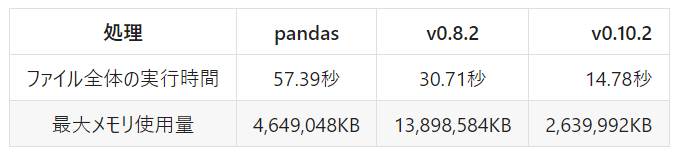
各処理の測定をするために使った_evaluate()ですが、これがあると関数を細切れに実行してしまい、fireducksの一部の高速化が機能しない可能性があるので、測定用のコードを取り除いてファイル全体の実行時間を測定しました。測定結果は下表のようになります。バージョン0.8.2よりも約2倍高速化していることがわかります。また、メモリ使用量もさらに削減されています。
まとめ
バージョン0.8.2から0.10.2になったことにより、一部のメソッドで劇的に高速化していることがわかりました。ファイル全体の実行結果としてはバージョン0.8.2から約2倍高速化しています。また、最大メモリ使用量も0.19倍に抑えられていて、大幅に改善しており、より手軽に使用できるようになっているといえるでしょう。
この記事が気に入ったらサポートをしてみませんか?