
【Stable Diffusion】Kohya LoRA GUIでLoRA追加学習再チャレンジ!★10,000文字超え/キャプチャ豊富に徹底解説!

Noteでは初めまして!ブログやYoutubeで、AIやブロックチェーン、WEB制作について研究したり、バ美肉(おじさんが美少女のアバターを授かった)Vtuberとして、ピアノやシンセ演奏、作曲活動をしているエルティアナと申します!
普段、Stable Diffusionなどの画像生成AIを試してみたレポートをブログで書いているのですが、今回初めて、Noteに投稿してみよう!と思い立って筆を執っています。※初投稿のくせに有料部分を作ってすみません…でも今回、出来るだけ分かりやすいように(自分も絶対あとで見返して参考にするので)渾身の力を込めて記事を書きました…!
■LoRAについて(復習)
LoRA(Low-Rank Adaptationの略)は、モデルのカスタマイズ手法の一つで、普段利用しているモデルをベースに、簡単にアレンジを加えたい場合に適しているデータを作成可能。VRAMが必要ですが、LoRaなら最低8GB程度あれば可能とのことで、軽いイメージ。
Stable Diffusion Web UIの構成ファイル内に格納して、プロンプトとして呼び出して利用する仕組みになっています。
■LoRA学習再チャレンジの経緯
数か月前に、自分(エルティアナ)の姿を学習させて、いわゆる【うちの子】の出力をしたくて、Kohya's GUIというツールを使ってすでにLoRA学習はやってみたのですが、上手くいっている部分といっていない部分(背景とか学習させたままの内容がかなり影響受けて出てくる…とか)があって、あれからネット上にもナレッジが増えてるみたいだし、最新情報をキャッチしながらもう一回やってみよう!となりました!
◆初回チャレンジのレポート記事
■初回の学習の所感と今回の学習の抱負
はじめてLoRAの学習を行った際は、自分のつたないスキルで出来る範疇でいいからやってみたい!ということで、とにかく実践してみた方の記事をネット上で探してたら、Kohya's GUIという、比較的エンジニアスキルがあまりない自分みたいなのでも簡単にできそうなツールがあると知って、これまた探り探り…最後までやってみたような感じでした。
■以前利用したKohya's GUI(導入方法が若干難しくてほとんど覚えてない…)
これを利用して、結果的に髪型や瞳の色、服装など、確かに私だ!と思えるイラストをLoRAで出力できるようになって、しばらく満足して使ってたのですが、当時学習をさせたときに、学習元の画像にそれぞれ違った背景がはいってしまっていて、おそらく今回試してみようとしている、画像と一緒に学習させるタグの配慮が足らなかったせいで、学習させた背景もかなり色濃く出ちゃってるような感じなので、これを改善したい!と思っている次第です!
■【Kohya LoRA GUI】昔より導入も作業も簡単に!
以前の私のブログで紹介した上記のKohya’s GUIは、今回取り上げる【Kohya LoRA GUI】と名前は似ているのですが、ソフトウェアとして別物?のようで、導入も利用も、以前使ったKohya’s GUIよりさらに簡単に、普通のアプリケーションを使う感覚で操作ができるようになっていて驚きました!(詳細を追い切れていなくて大変恐縮ですが、RedRayzさんという方が、元祖のKohyaさんが作った仕組みを、もっと直観的に使いやすく利用できるツールを作ってくれた流れかな?と思っています!)
特に導入時に、コマンドプロンプトやターミナルという黒い画面に英語で指示していくような、エンジニアじゃない人が【うわあ…やっぱやめとこ…】となりがちな難易度の高いイメージが(ある程度)払拭されています!
※初回のチャレンジの時はインストールを黒画面(Git?)ですべて行っていました…
■【Kohya LoRA GUI】を利用する前提条件
・Python 3.10.xがインストールされている
・Gitがインストールされている
※本記事ではこれらがすでに終わっていることを前提としています。Stable Diffusion Web UIをローカルで使っている人ならすでに導入は済んでいると思います!
■実践の成果
今回、改めて私の姿を学習させて作成したLoRAを使ったところ、こんな感じで生成が出来ました!なかなか理想的なイラストが出せるようになって大満足です!

■今回実践してみたレポート!
①学習させるデータの作成
①-1.元画像作成
まず、LoRA学習のためにこれがなくては始まらない!という学習用の画像データを作成します!
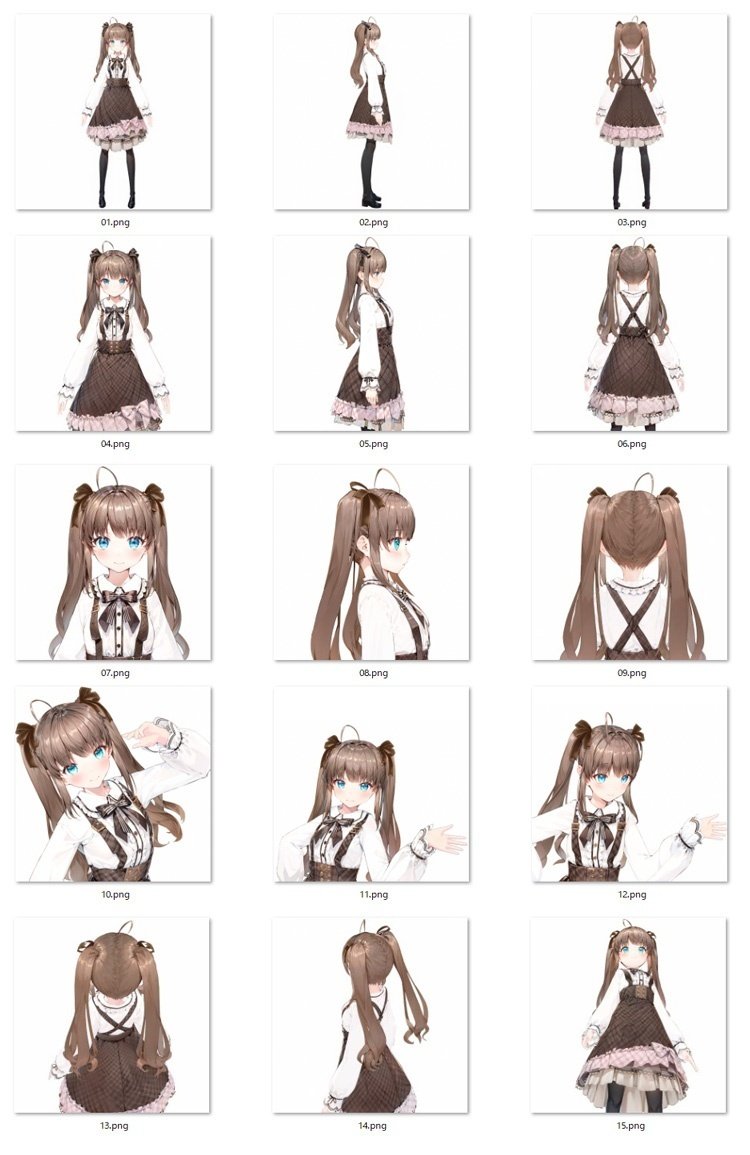
前回、私のブログでも書いている手順を基本的には今回も踏襲するのですが、私の場合、Vroid Studioで3Dのアバターを作成済みなので、今回も大元となる画像を、Vroidからスクリーンショットで作成します。今回の要件としては、以下でやってみたいと思います!
・用意する画像は15枚
・画像サイズは1500px*1500px
・背景画像なし(純粋な白背景)
・画像データの拡張子はpngにする(便宜上)
・画像データの命名規則は【01.png、02.png、03.png…】とする
学習に何枚画像を用意するか?とか、サイズはどのくらいがいいのか?背景を入れた方がいいのか?などなど…前提というのはいろいろ調べてみても議論が尽きない…ような感じだったので、今回は感覚でズバリこれ!という前提で進めてみます!命名規則は便宜上というところかな?と思ってますが前回と同じにしました。
まずVroidで作ってみた画像群がこちら(*・v・)!

①-2.元画像のimg2img
①-1.で作った画像は、まさにVroidの3Dモデルデータまんまなので、今回も、①-1.の画像をお気に入りのモデルでimg2imgをしてクオリティアップを目指します。※今回はごくわずかしか手動では手を加えていませんが、手や服の修正、ごみ取りなど、必要に応じて手動の修正もします。
最終的にimg2imgで再出力してみた画像群!
②Kohya LoRA GUIのインストール
ここで、Kohya LoRA GUIをインストールします!
上記にアクセスして、「kohya_lora_gui-x.x.x.zip」をダウンロード
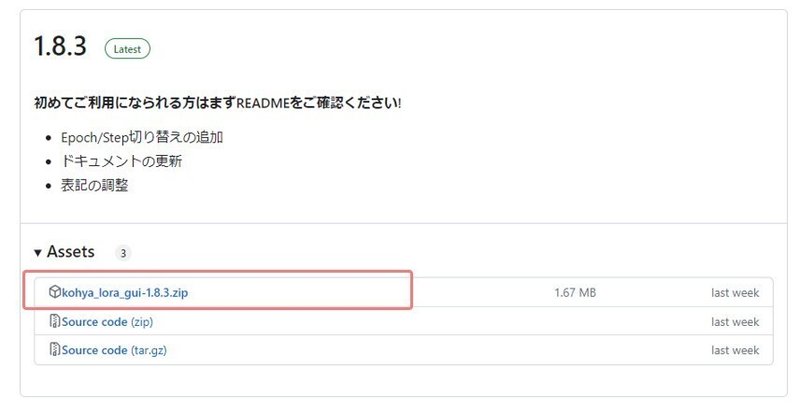
ダウンロードしたら任意のフォルダに解凍するのですが、ご参考までに私は以下のようにCドライブの配下に置いてみました。

Cドライブ直下はさすがに上すぎますが、『kohya_lora_gui-1.8.3』がかぶってる構成は要らなったと反省…
上の【kohya_lora_gui-1.8.3】フォルダ(解凍したフォルダの方)に入り、『Kohya_lora_trainer.exe』をダブルクリック

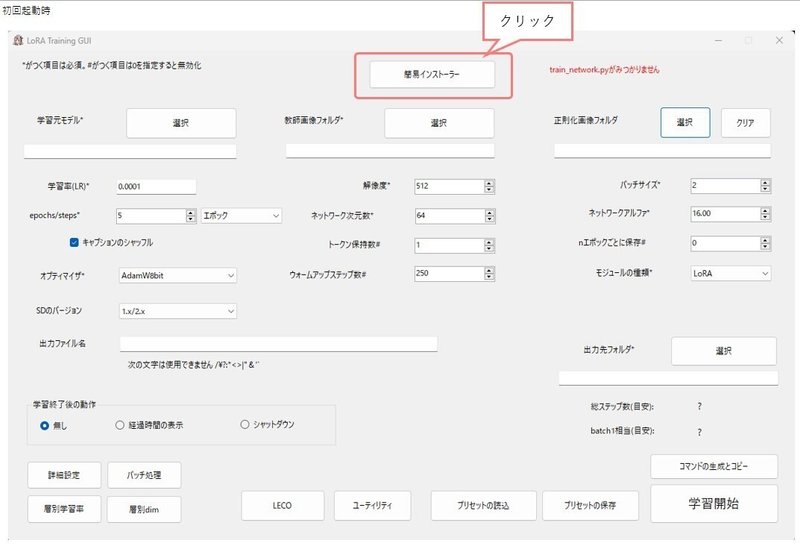
すると、以下のようにLoRA Training GUIが起動するので、画面上の真ん中あたりにある『簡易インストーラー』をクリックします。
※右上にあるtrain_networdk.pyがみつかりませんというのは、簡易インストールが成功すると消えますので、いったん気にしなくて大丈夫です。
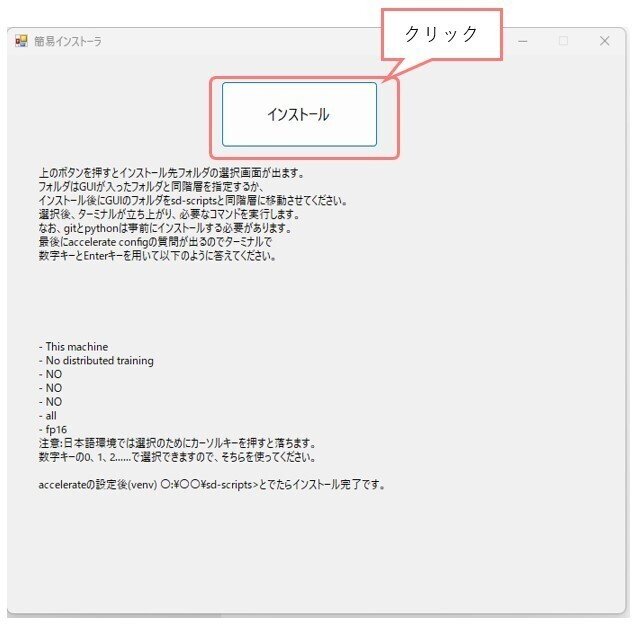
次の画面で『インストール』をクリックします。
すると、ローカルのフォルダを指定するウインドウが出てくるのですが、ここは【kohya_lora_gui-1.8.x】を解凍したフォルダが存在するディレクトリを指定してください(※下図参照)
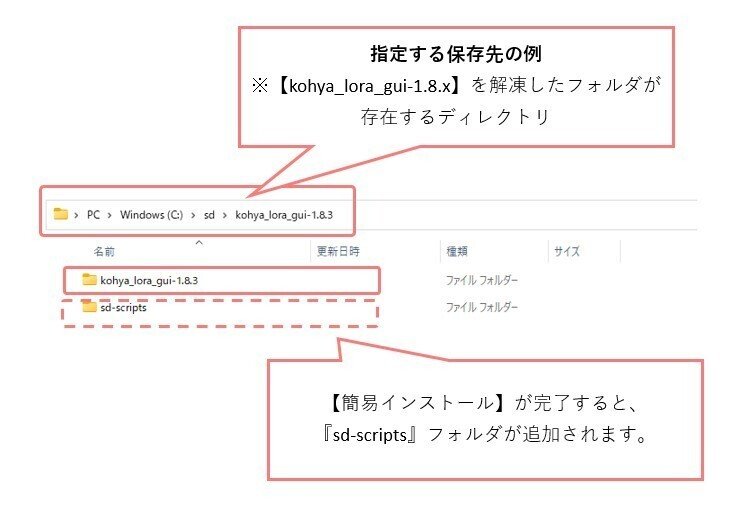
フォルダ指定すると、ここでターミナル(黒画面)が出てくるのですが、自動で英語の命令や進捗バーが進行していくので、その様子を見守ります。
すると、こちらに指示を仰いでくるような形で処理がいったん停止するので、そこで、以下の操作をしてください。
※この操作と似たような操作は前回もありました…
7が若干操作を間違えやすくて間違えてしまうと、簡易インストールのやり直しになってしまう(と思う)のでご注意を!
1.エンターキーを押す(This machineを選択)
2.エンターキーを押す(No distributed trainingを選択)
3.「no」と入力してエンターを押す
4.「no」と入力してエンターを押す
5.「no」と入力してエンターを押す
6.「all」と入力してエンターを押す
7.「1」を押して【fp16】の左に*が移動したのを確認してエンターを押す
※まちがえて【↓】などを押すとエラーで④の初めからやり直し
最後に 〇:¥〇〇¥sd-scripts> というメッセージが出たらインストールは完了です!いったんお疲れ様です!黒画面は閉じて大丈夫です。
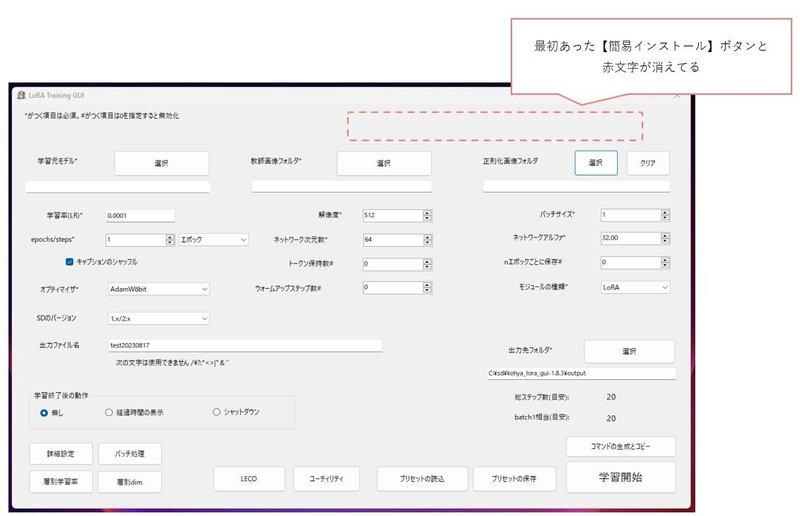
一度『Kohya_lora_trainer』ウインドウも閉じて、再度起動すると、最初にあった簡易インストーラーボタンと赤文字が消えています!
③フォルダ構成・モデル準備
ここから先は
¥ 300
この記事が気に入ったらサポートをしてみませんか?