
新たなトレンド「AIエージェント」がもたらす未来のユーザ体験

こんにちは、Doryと申します!
本日は、私がここ数ヶ月夢中になっている「AIエージェント」という分野に着目し「AIエージェントという技術が、ユーザ体験に今後どんな変化をもたらすか?」という観点から記事を書いてみました!
【この記事には何が書いてある?】
・AIエージェントの概要や仕組み
・AIエージェントに関する事例
・AIエージェントが今後どんな変化をもたらすか?といった予測・展望
・AIエージェントはむちゃくちゃ楽しいよということ
【この記事の想定読者】
・「いま話題のAIエージェントって何ぞ?」をキャッチアップしたい方
・AIエージェントが今後どういった変化をもたらすか?に興味がある方
1. 「AIエージェント」って何ぞ?
OpenAIの「GPT-4」やMetaの「LLaMA」をはじめとした大規模言語モデル(Large Language Model;以降は"LLM"と記載)は、大規模なテキストデータを事前に学習しており、要約、翻訳、質問応答などのタスクで非常に高い性能を発揮しています。
「AIエージェント」とは、そうしたLLMを使用して開発された"自律型"のソフトウェアの総称です。
誤解を恐れずにざっくりと説明すれば、AIエージェントとは「人がいちいち指示を出さなくても、自分でやることを考えて、いろんなツールを使い分けながらタスクをこなしてくれる」というソフトウェアです。
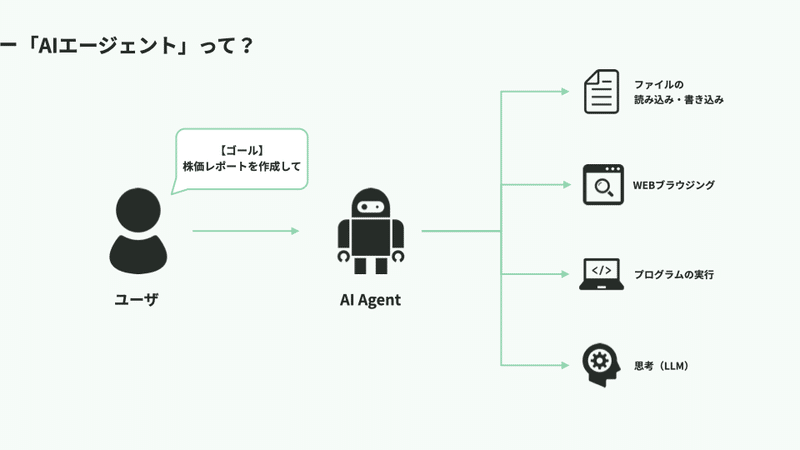
AIエージェントは以下のような特徴を持っています。
人間が与えた目標をもとに「やるべきこと(タスク)」を洗い出したり、優先順位づけしたりする
「WEBを検索する」「ファイル書き込み/読み込みをする」「WebAPIを叩く」など外部ツールを利用する
外部ツールの実行結果やエラーの内容をもとに自身の行動を修正する

2. ムーブメントの火付け役「Auto-GPT」
AIエージェントに一気に注目が集まるきっかけになったのは「Auto-GPT」というオープンソースのAIエージェントです。
Auto-GPTはGPT-3.5/GPT-4ベースで動作するAIエージェントで、「近年最も勢いのあるAI関連リポジトリの一つ」とも言われています。
リリースから1ヶ月の間にGithubでスターが13万ついたり(※みんな大好きPyTorchの倍くらい)、二〜三日ほど目を話している隙に200コミットくらい更新されているなど、なんというか狂気的なパワーを感じるプロジェクトです。
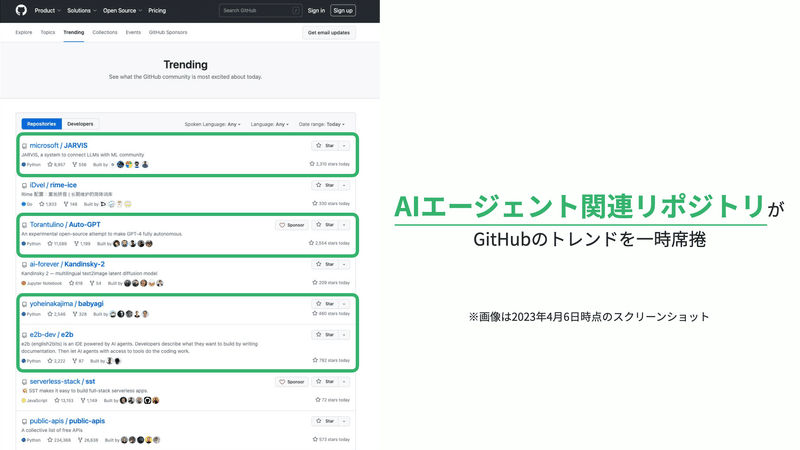
このAuto-GPTが2023年4月にリリースされて以降、一気にAIエージェントに注目が集まり、オープンソースのAIエージェントやWEBサービスが爆発的なスピードで登場しています。

こうしたAIエージェント関連プロジェクトがGitHubのトレンド上位を席捲したこともあり、非常にホットな分野であることが伺えます。
3. AIエージェントのユースケース
こうしたAIエージェントは、まだ発展途上の分野であり、まだまだ実業務への適用には研究が必要です。
しかしながら、今後の私達のワークスタイルを大きく変える可能性を秘めていると私は強く感じています!
ここでは、主にB2B分野でのユースケースを中心に、面白いものをいくつかご紹介します!
デスクトップリサーチ
Aomniは、リサーチ業務に特化したAIエージェント型のプロダクトです。
「競合他社のA社について、今月の最新ニュースをまとめて」「◯◯分野の論文を調査して」「△△というニュースについて、世間の声をまとめて」などの形でゴールを与えると、WEB上の情報を探しながら要点をまとめてくれます。
土地勘の無い分野での初期リサーチを行う際には、非常に重宝しそうです!
Just launched: an agent specifically designed for research.
— David (@dzhng) April 17, 2023
Using a modified babyagi architecture by @yoheinakajima & AutoGPT
For example:
- podcast script from latest news
- market research report
- new github repos trending on hacker news
Live now on https://t.co/tyAraqL0cH pic.twitter.com/FvQzNj1uIo
コーディング
つい先日登場したGPT-Engineerは、ユーザが作成したいものを能動的ヒアリングしながらコードを書いてくれるエージェントです。
現時点ではまだまだピーキーで正常に動作しないこともありますが、いずれエージェントと共同開発できる日が来ると思うと、非常に楽しみです。
GPT-Engineer just hit 12,000 stars on Github.
— Lior⚡ (@AlphaSignalAI) June 18, 2023
It's an AI agent that can write an entire codebase with a prompt and learn how you want your code to look.
▸ Asks clarifying questions
▸ Generates technical spec
▸ Writes all necessary code
▸ Easy to add your own reasoning… pic.twitter.com/3ILw9nBKmo
SQL
Auto-GPTをベースに作られたデモです。データベース内のテーブル構造を理解したうえでSQLを組み立て、実行結果をSlackに通知してくれます。
非エンジニアでもSQLが使いこなせるようになると、様々な企業でデータ活用がより進みそうですね!
#AutoGPT is making automation possible. 😱
— Karan Doshi (@KaranDoshi13) April 17, 2023
We built an intern that does things by itself - just tell it what to do. It understands all tables in your database, writes SQL queries automatically, and sends notifications on your Slack channels.
Introducing #GlazeGPT ⬇️🧵 pic.twitter.com/rZMuJt1I68
データ分析
手前味噌ですが、個人でこのようなAIエージェントを開発しています!
CSVの内容をもとに、データ分析方法をエージェント自身で考え、グラフ付きのレポートを作成します。
仕組みはこちらのスライドに記載しています!
完全自動でデータ分析してくれるAIが、半分くらい出来上がりました🤖
— Dory | AI Agent (@dory111111) March 10, 2023
ExcelやCSVをアップロードするだけで、AIがデータ分析方法を自分で考えて、数分でグラフつきのレポートにまとめてくれます!先行登録も開始したので、αテストにご協力いただける方は何卒🙇https://t.co/s0epfcMMOW#ChatGPT pic.twitter.com/9AR7MGRlq5
ライブ配信
ここまで紹介したB2B分野向けのAIエージェントとは方向性が異なりますがが、AIエージェント界隈で最も熱量高い分野のひとつがAITuberです。
人の手を介さない完全自律型のVTuberのようなイメージで、生配信で自動でコメントを拾ったりリアルタイムで音声対話したり、過去の会話内容を記憶して覚えたり…と、非常に面白いチャレンジが行われています。
4. AIエージェントのしくみ
では、ここまで紹介したようなAIエージェントはどのようなしくみで動いているのでしょうか?
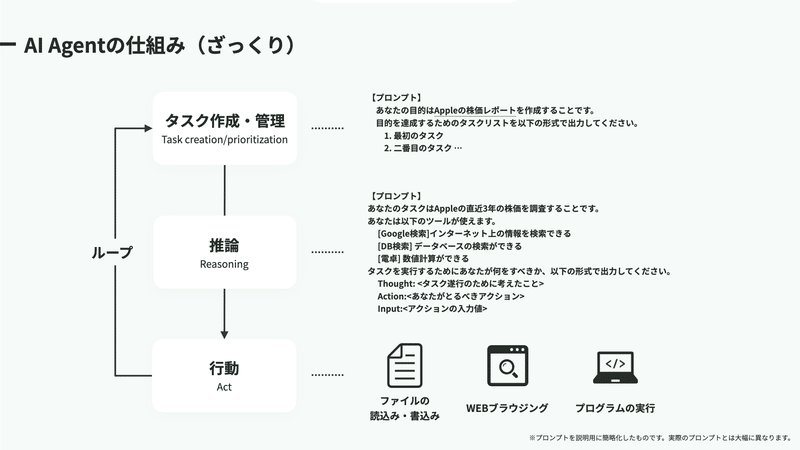
エージェントごとにしくみは大きく異なるものの、超ざっくり説明すると
1.タスク作成・管理(Task creation/priorization)
2.推論(Reasoning)
3.行動(Action)
の3ステップに分かれていて、これらのループによりエージェントは構成されています。
【ステップ1: タスク作成・管理】
ユーザから与えられたゴールに基づいて、ゴールを達成するためのタスクを考えるステップです。
たとえば、ユーザから与えられたゴールが【Appleの株価レポートを作成すること】だったときは、以下のような形でエージェントがタスクを分解し、実行可能な粒度に落とし込みます。
タスク1. 過去3年分のAppleの株価データを収集する
タスク2. 収集したAppleの株価データを分析する
タスク3. Appleの株価に影響する要因を調査する
タスク分解はLLMを用いて行われます。
以下のようなプロンプトがLLMに与えられるイメージです。
【プロンプト】
あなたは【Appleの株価レポートを作成する】というゴール達成するために、タスクリストを作成する必要があります。
・レスポンスでは、各行に1つのタスクを返してください。
・結果は次のようなフォーマットの番号付きリストである必要があります
1. 最初のタスク
2. 2番目のタスク
・番号の後にはピリオドを付けてください。
・タスクリストが空の場合は、「現時点で追加するタスクはありません」と記載してください。
実際のプロンプトとは大幅に異なります。
【ステップ2: 推論】
次のステップでは、エージェントがタスクの実行方法を考えます。
たとえば、1つ目のタスクが【Appleの株価データを収集する】だったときは、以下のようなプロンプトをLLMに対して与えます。
【プロンプト】
あなたのタスクは【Appleの直近3年の株価を調査】することです。
あなたは以下のツールが使えます。
[Google検索]インターネット上の情報を検索できる
[DB検索] データベースの検索ができる
[電卓] 数値計算ができる
タスクを実行するためにあなたが何をすべきか、以下の形式で出力してください。
Thought: <タスク遂行のために考えたこと>
Action:<あなたがとるべきアクション>
Input:<アクションの入力値>
実際のプロンプトとは大幅に異なります。
上記のようなインプットをLLMに対して与えると
Thought:株価データを入手するためにまずは信頼性の高いソースを見つける必要がある
Action: Google検索
Input: 「Apple, 株価, 2020年以降」
といった形式でのレスポンスがあり「あ、次は"Apple, 株価, 2020年以降"ってキーワードでググれば良いんだな」とエージェントが判断するようなイメージです。
【余談です💡】
2023/6/14にOpenAIから大きなアップデートが発表され、Function Calling(関数呼び出し)という機能が追加されました。
これは上記の「タスクの実行方法を考える」ステップを手軽に実装できるような機能で、これによりAIエージェントをより構築しやすくなりました。
【ステップ3: 行動】
推論の結果をもとに、AIエージェントがツールを利用してアクションを実行します。
前述の例であれば、Google検索ツールをエージェントが利用し、Appleの株価データをYahooファイナンスから引っ張ってくる、みたいなイメージです。

5. AIエージェントがもたらす未来のユーザ体験
ここまでの説明を読んでいただくと、AIエージェントはChatGPTのようなチャット型のプロダクトとは全く異なる特性をもつソフトウェアなんだな、ということが感じられたかなと思います!

私は、AIエージェントはソフトウェアの未来像の1つだと強く信じており、少なくとも今後数年間はこの分野にベットしていく所存です。
そこで、ここからは、エージェントが実用化した “一歩先” の未来で起きそうなことをいくつか予測してみたいと考えています。
予測①:AI利用のハードルが更に下がる?
これは前述の「全自動データ分析エージェント」開発時のエピソードなのですが、私は実はもともとChatGPTのような「チャット型データ分析ツール」を開発していました。
ユーザが「◯◯のデータを抽出して中央値をまとめて」「◯◯と△△の相関係数とp値を出して」などをAIに対して命令するようなイメージのツールです。
このツールのプロトタイプを作り、実際にユーザさん数人にテストいただいたのですが、自信満々で作ったわりにユーザの皆様からはボロボロなフィードバックを頂いたということがありました。

ユーザの皆様から頂いたコメントとしては「統計用語に詳しくないので、何を指示すればいいのかわからなくて使い物にならない」「そもそもどんな分析をすべきかの判断が難しい」といったものです。
このフィードバックからは「チャット型のUIは本質的に万人向けのものではない」んだな、という気付きが得られました。
チャット型のUIの場合「このAIには何を話しかけるべきなのか」というリテラシーやドメイン知識がユーザに強く求められてしまいます。
「ググり力」という言葉が表すように、検索エンジンですら使用には習熟が求められます。であればチャットAIのユーザには、より高度な「プロンプト力」が要求されるのも必然です。
一方、複雑なプロンプトを考える必要がなく"よしなに"やってくれるAIエージェントは、老若男女の全人類が平等にLLMの恩恵を受けるうえで必要不可欠な、新たなユーザインターフェースになるのではないか?と予測しています。

もちろん、すべてのアプリケーションがエージェント型になればいいかというとそんなことはありません。
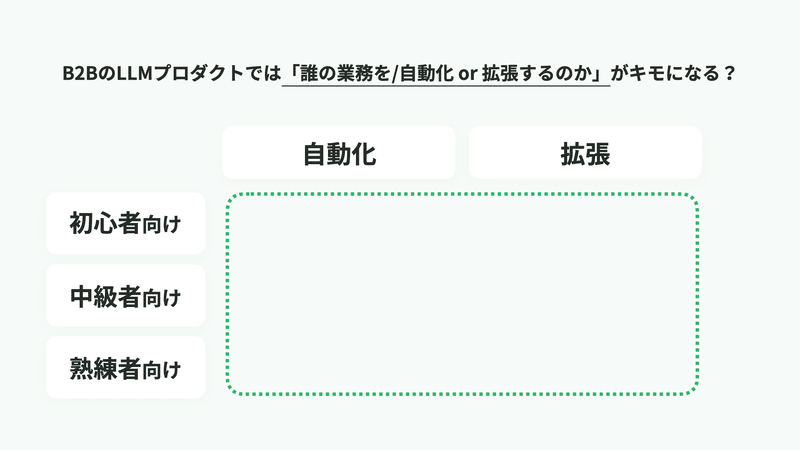
Googleが2019年に発表したAIプロダクト向けのUXデザインガイド「People + AI Guidebook」によれば、AIアプリケーションには「自動化」「拡張」の2つの方向性があるとされています。

すべてのアプリケーションが「自動化」を志向する必要は決してなく、重要なのは各アプリケーションが
・どんなリテラシーのユーザ向けに
・自動化/拡張のどちらを実現したいのか
という位置づけだと思います。
位置づけに応じて、チャット型とエージェント型のインターフェースを適切に使い分けることが、恐らく今後の鍵になるのではないでしょうか。
予測②:ユーザはもはや「人間」だけではなくなる?
数年後の未来に起きそうなもう一つのことは「サービスの利用者が人間だけではなくなる」ということです。
さきほど、AIエージェントは「検索エンジン」「ファイル操作」「API」といった外部ツールを使いわけるということを記載しました。
これはエージェントに限った話ではなく、ChatGPTでもWebブラウジングやプラグインといった外部ツールを使えるようになってきています。
これらが示すのは、人間のかわりにLLMがツールを操作するケースがめちゃくちゃ増加するという未来です。

人間のかわりにLLMがツールを操作するようになれば、必然的にツール側の”AI可読性”、つまりAIにとっての"使いやすさ"が重要になります。
"AI可読性"の重要性を予感させる出来事でいうと、前述の全自動データ分析エージェントを作っていたとき、明らかにLLMにとって分析しやすいCSVデータとそうでないデータが存在していました。
例えば、カラム名に単位が付与されていると分析が成功しやすくなったり、データについての説明が記載されていると結果の解釈で誤りが発生しづらくなる、といったパターンが見られました。
似たケースで言えば、ChatGPTのBrowsing機能を使っているとき、内容を要約しやすいWEBサイトと要約しにくいサイトがあるということを感じている方も多いのではないでしょうか?

今後はAIエージェントの増加に伴い「サービス利用者としてのAI」にとってフレンドリーなつくりが、サービスやツールの提供者には求められるかもしれません。
6. AIエージェントが今、本当に最高にアツい
ここまでAIエージェントの仕組みやユースケース、エージェントがもたらすかもしれない一歩先の未来について紹介をしてきました。
読者の中には「Auto-GPTを触ってみたけど、まだ実用化には早いかな」「AIエージェントは世に出たての技術だし、荒削りだなぁ」といった感想を持たれた方もいるかもしれません。
逆に言えば、これは間違いなく、作り手にとっては最高にアツい状況です。
もし今、実用的なAIエージェントを提供することができれば、世界で最初にエージェントの社会実装に成功したひとりになれるはずです。
また、技術の黎明期に立ち会うことで、AIエージェントという技術が世界を徐々に変える瞬間に立ち会えることはめちゃくちゃ面白い経験だなと思います。
そして何より、AIエージェントを作ることは最高に楽しく、作り手としての知的好奇心がマジで満たされます。ドーパミンを放出しまくりたい方にとって、AIエージェントはこの上なくオススメです。
ということで、7000字以上に渡ってつらつらと書いてきましたが、私がお伝えしたいのはこれだけです!!

【📢宣伝】一緒にAIエージェントを作りませんか?
ここまで読んで頂いた皆さんは、今すぐにでもAIエージェントを作りたくて気が狂いそうな状態になっているのではないでしょうか。
そんな皆様に良いお知らせがあります!!!
私が参画しているとあるAIスタートアップにて、AIエージェントを活用したプロダクトを一緒に開発してくれる仲間を募集しています!!!
AIエージェントで日本の生産性を一桁変えるような事業を一緒に作りましょう🙆♀
【募集職種】
・ソフトウェアエンジニア(Azureに強い方は特に歓迎です!)
・テクノロジーディレクター(事業部のCTO候補です!)
現時点ではまだオープンになっていない求人のため、DMをいただければ社名などの詳細をご案内します。
ご興味がある方は、下記アカウントまでDMでご連絡ください!
【おまけ】AIエージェントはいつ誕生したの?
本noteで取り扱ったような「LLMを使った、自律的に動作するエージェント」は、いつ頃に誕生したものなのでしょうか?
私は正確な起源を把握できていないのですが、類似のコンセプトを示す論文やホワイトペーパーは、1年以上前から既に存在していたようです。
ここでは、とくに代表的なものに絞って紹介をするので、興味がある方はぜひ読んでみてください!
MRKL Systems: A modular, neuro-symbolic architecture that combines large language models, external knowledge sources and discrete reasoning
・https://arxiv.org/abs/2205.00445(2022年5月)
・AIエージェントが複数のツールやアプローチを組み合わせる「MRKL(Multi-Round Knowledge Loop)」というアプローチを提案
-------------------
Language Model Cascades
・https://arxiv.org/abs/2207.10342(2022年7月)
・言語モデルカスケードというアイデアを提案
--------------------
ReAct: Synergizing Reasoning and Acting in Language Models
・https://arxiv.org/abs/2210.03629(2022年10月)
・推論(Reasoning)と行動(Action)を交互に行うReAct (Reason + Act)というアプローチを提案
-------------------
Toolformer: Language Models Can Teach Themselves to Use Tools
・https://arxiv.org/abs/2302.04761(2023年2月)
・外部ツールを呼び出す方法を学習した「Toolformer」というモデルの提案
-------------------
Generative Agents: Interactive Simulacra of Human Behavior
・https://arxiv.org/abs/2304.03442(2023年4月)
・25人のAIエージェントによる小規模社会シミュレーション
--------------------
※ 私も網羅的にはサーベイできていないので「こんな論文もあるよ!」という情報、お待ちしてます!
この記事が気に入ったらサポートをしてみませんか?