データエンジニアのことがちょっとだけわかるnote

データエンジニアってどういう人?
このnoteのモチベーション
今、データエンジニアの需要が少しずつ高くなってきています。
元々、データエンジニアリングの分野自体の歴史は古く、インターネットが広まる前からありました。当時はデータベースエンジニアと呼ばれ、主にOracleやMicrosoft SQLといったリレーショナルデータベース、簡単に言うと表形式のデータを扱うことが多かったですが、それらは大企業の大きなシステムで利用される専門性の強い分野でした。
やがてインターネットが広まり始めると同時にSQLサーバを自前で持つ企業も増え始め、そして2010年ごろビッグデータがバズワードとなると、ビッグデータを扱うための様々な技術が現れ、同時にデータアナリストやデータサイエンティストといった職種も台頭し、データの重要性が理解されはじめてきました。
データサイエンティストなどは、データサイエンティストブームというような流行が過去何度か起こったので、分野に明るくない方でも名前くらいはご存知の方もいらっしゃるでしょうが、それらを支えるデータエンジニアの存在はまだ世の中に浸透していないように思えます。
私がデータエンジニアとして活動を始めてから8年目、データエンジニアの会社を立ち上げて3年目に突入し、この分野もいろいろトレンドが移り変わってきました。ここで一つの節目として、私の歩みと共にデータエンジニアリングの流れを振り返りつつ、データエンジニアリングのこれまでとこれからを概括的に振り返ってみたいと思います。
データエンジニアの生態
世の中のエンジニアと呼ばれる職種は様々ですが、データエンジニアがどのような仕事をしているのか書かれた資料は少ないです。就活サイトを見ても職種として項目自体が存在しない場合も多く、かろうじてデータベースエンジニアなどの名前が見つかることもありますが、それはデータエンジニアとは少しニュアンスが違います。
どのように違うかというと、データエンジニアはデータベースだけのことを扱うわけではなく、データ利用者に対して色々な形でデータを提供するために様々な役割を担います。
現状、通説的には世の中でそのように受け止められているので、仕事の内容についてもかなり広範に色々なことを行います。そのため、ネット上でどこからどこまでがデータエンジニアの領分なのかという議論が度々巻き起こり、あらためて未分化で発展途上な分野だなという印象を受けます。
そのように曖昧で定義のはっきりしないデータエンジニアの仕事についてはのちの章でより詳細に追っていきたいと思います。
データエンジニアリングの歴史
近年のデータエンジニアリングの歩みについてざっとまとめてみます。技術的な系譜としては、たとえばこのRudderstackの資料によくまとまっているので詳細はそちらをご覧いただければと思います。
上記資料にあるデータエンジニアリングツールの年表をかいつまんで見てみますと、2000年初頭から2010年まではETLツール、2010年からビッグデータツールの台頭、2015年ごろよりDatawarehouseの登場、そしてビッグデータが当たり前のものになってくると、それらを整備するツールが登場する流れとなっています。
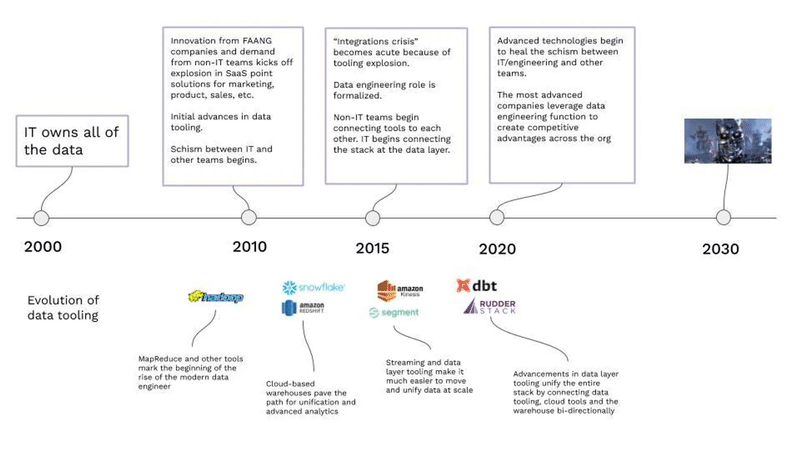
一方で、この年表と照らし合わせて見たい指標として、データマネジメント成熟度モデル(DMM)というものがあります。DMMとはその名のとおりデータを管理する段階の成熟度を表したものです。
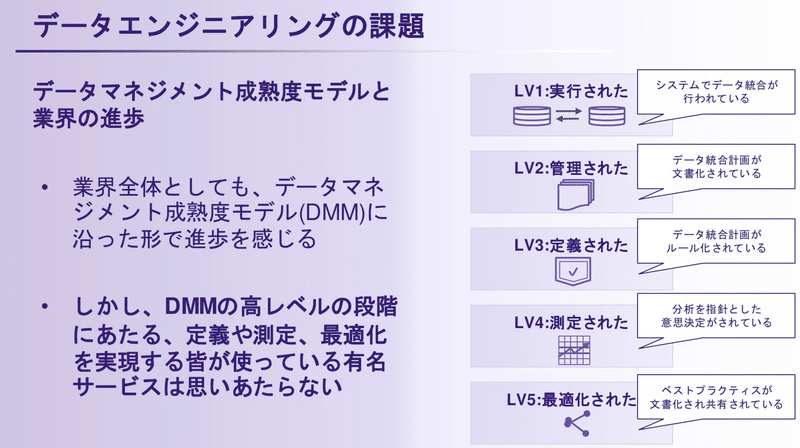
私は、データツールの年表とDMMの成熟度は、お互いに補完し合うものとなっていると考えています。DMMは通常、特定の企業でデータがどれだけ整備されているか示す指標として用いられますが、世の中のデータエンジニアリングツールも、このDMMのレベルに沿った形の課題を解決するものが徐々に登場してきたように映ります。
そのように考えると、現代のデータエンジニアリングツールはたとえばdbtなどが流行ですが、LV5の段階の課題解決にかなり近づいているように思えます。
私とデータエンジニアリング
ここでは、より具体的にデータエンジニアの実態に光を当てるため、まず私個人の経歴やスタンスを簡単に振り返らせていただきます。
技術的背景・SIer時代
データエンジニアになる以前、私はSIerで長く働いていました。私が新卒で働いていた頃はまだIT業界に人権意識が浸透しておらず、ハラスメントの横行や300時間を超える長時間残業などといった、世に言う典型的な昔語りに登場するようなトラブルはおよそ漏れなく経験してきました。そう考えると現代の仕事環境は相当に改善されてきたと感じています。
SIer時代では、OracleやHiRDBといったデータベースを用いていたこともありましたが、主にC言語でOSやハードウェアの開発といった低レイヤーの開発を長く続けてきました。低レイヤーとはコンピューターのハードウェアに近い部分のことで、コンピュータが理解しやすい形でプログラミングする必要があったため面倒が多かったです。現代の開発ではやりたいことを実現するために便利なツールが揃っているので、随分開発もスピーディーで楽になりました。

SIerで働いてきてよかったと思うことは、スタートアップやベンチャー企業で働いているとあまり意識することがないですが、世の中はまだまだ序列や組織の力学に従ったルールを強いる場面があり、独特なお作法を学べる機会がたくさんあったことです。SIerで働いてきた人全員がそうとは言いませんが、世の中の仕事に対して柔軟な向き合い方を獲得できたと考えています。
データエンジニアを選んだ経緯
私がSIerを辞めたのは2017年でした。当時は先行きが特に不透明な時代で、当時刊行された戦略系トレンドの書籍に当たっても、中長期の見通しについて具体性のある記述がなかなか見つからなかったことを覚えています。
当時のエンジニアの志向としてはWebエンジニア・アプリエンジニアが人気でした。そうした中で私がデータエンジニアの道を選んだのは、エンジニア全体としてのパイは拡大し続ける見通しがあったものの、すでに流行のピークに近く過当競争気味だったWebエンジニア・アプリエンジニアの分野にこれから参入するのはピークアウトが訪れるのも早く、将来的な競争優位を取ることが難しいかもしれないと考えたためです。
その点、データサイエンティストが話題になっていたもののデータエンジニアはそれほど注目されておらず、開発者自体も少なく新参者でも参入障壁が低かったので、参入するタイミングとしてちょうどいいと考えました。
今になって思うと、上に挙げたRudderstockの資料にあるように、データエンジニアのトレンドが2016年ごろより上昇してきたことをみると、うまく機を伺い流れに乗れたのではないかと考えています。
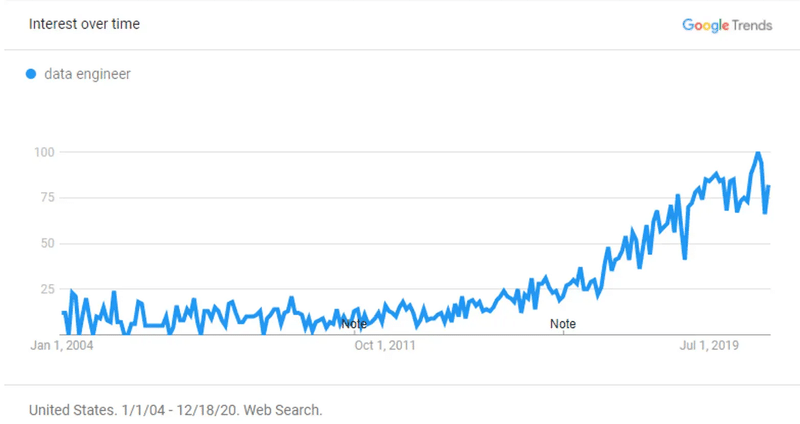
それ以外にも、データ業界全体の将来性についてはかなり昔より注目しており、私が考えていたことは以下のややこしいエントリにまとめているので、お暇な時にでもご一読いただければと思います。
エンジニアとしてのスタンス
会社員をやめてから8年目、法人化してからは3年目。おかげさまで事業は好調で、バイネームでお仕事の依頼を頂いたり、ひと月あたり数時間での技術相談契約をいただいたりと、様々な形で仕事をいただくようになりました。
私の仕事は、データ基盤を一気通貫で構築し、技術的なコンサルティングをすることも掲げている以上、専門性に広く深く通じていることは必要不可欠となります。ですが、それとは別にマーケットトレンド・企業との関係性、そして、技術よりも企業が提供するサービスに貢献することをより重視しています。
私はSNSが苦手で、これまでの登壇数や書いてきた記事もそれほど多くないのですが、それでもちらほらお仕事の依頼をいただけているのはトレンドの流れのようなものを意識しながら仕事をしてきたこともあるかもしれません。法人化してそろそろ落ち着いてきたので、これからは広報にも注力しようとこのエントリを書いています。

データエンジニアの仕事
ここでは、紛糾しやすいデータエンジニアのスキルセットの議論と、僭越ですが私の事例をもとにデータエンジニアの実態に光を当ててみたいと思います。
データエンジニアのスキルセット
冒頭の章で少し触れましたが、データエンジニアの業務はとりあえずの共通認識としては「データ利用者に対してデータを提供する業務」と考えていただけたら良いでしょう。ですが、それはとても抽象的で広い意味の業務を指しています。
一方で、先行する海外では「データエンジニアの基礎」という書籍が出版され、先日邦訳されました。この本で示すデータエンジニアの領分を見ると、そうした膨大なカバー範囲を受け入れた上で、それらを一つの体系として確立してしまったように思えます。
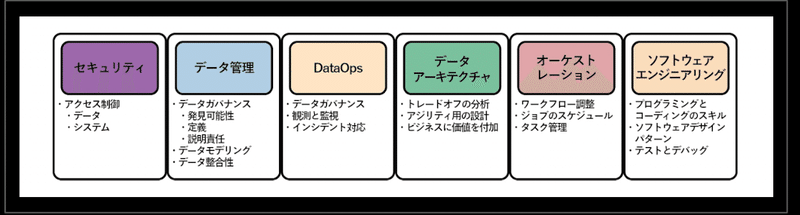
話は少し逸れますが、データ系の職種では、よくこれからのキャリアをどのように進むべきか?という話題があがります。通常のエンジニアの場合、進むべきロールモデルはすでに確立しているので選択肢もある程度決まっているのですが、データ系の職種は、例えばデータアナリストからアナリティクスエンジニアを志向したり、PdMを志向したり、データエンジニアでもインフラ寄りかアナリスト寄りかという分類をされたり、キャリアを指し示す的確な言葉が無いように見えます。
こうした現状は、この分野の急速な発展に世間の認識が追いついておらず、適切な議論がなされないままニーズだけが拡大、加速してきたために起こった結果であると考えています。
ただ、私としては、データエンジニアの価値や職分がこれだけ議論になるということは、裏を返せばそれだけ現代に説明に適した言葉がないということで、今の言葉で説明できてしまう職業よりはずっと将来性があると考えています。
そういった意味でも、少なくとも今においては、ロールモデルの無い課題に向き合うような、比較的強い主体性や応用力を持った全人格的な素養が求められる職種ではあるかもしれません。

データエンジニアとしてたずさわった案件
ここでは、できるだけ企業や案件の具体を避けながら、私が歩んできたデータエンジニアリングのあぜ道のような事例をいくつか紹介したいと思います。少し専門性が強く泥臭い話なので、泥が跳ねないようにお気をつけながら読み進めていただけたらと思います。
私がたずさわってきた現場は様々でした。アパートの一室を職場にしているようなスタートアップから、メガベンチャー、伝統的な日本企業まで幅広くお仕事させていただきました。100人を超える大きなプロジェクトに参加したり、月の稼働が200時間を超えたこともありました。
dbtやsnowflakeを用いたデータ分析基盤の構築や、データモデリング、セキュリティ関係などのデータエンジニアの現代の正道のお話は今まさに花盛りとなっており、ここで特に紹介する必要はないと考えました。私が過去アップした資料なども含めネット上にたくさんアップされているので、そちらをご覧いただけたらと思います。
Hadoopベースの大規模データシステム
Hadoopベースのデータシステムとは、先に挙げたビッグデータ流行の時代に登場した大規模データを扱うためのシステムで、現代でもDatabricks、TreasureData製品、Salesforce CDPなどといった著名なサービスで、扱う人がそれと意識していないところで多く用いられています。これらはBigQueryやSnowflakeなどが登場してからは、構成の複雑さやコストなどの関係で主流を明け渡しつつあります。
たとえば、コスト削減のため、これまで使用していたTreasureDataからBigQueryにデータを移行したいというご要望は多いのですが、HadoopベースのデータシステムはBigQueryやSnowflakeとアーキテクチャが大きく異なるので単純に移行するということができず、なかなか大きなプロジェクトになることがあります。
変わったところでは、BigQueryが世の中で知名度を得ていない頃に、位置情報のような大規模データを処理する際に少しでもリアルタイム性を上げようと、バイナリで読み込まないといけない特別なデータ形式をHadoopに独自APIを組み込み並列処理するような尖った対応をしていたのを覚えています。先端の技術であるほど、そうしたアドホックな処理にも対応できる下地が必要になってきます。
データパイプライン・データ分析基盤構築・機械学習基盤
これまでにAWS kinesisやAirflow、DigDagやDataflow、Dagsterなど、データ分析基盤や機械学習基盤を環境構築も含めていくつも作ってきました。ここは紹介しませんが、その時に用いた技術スタックについては企業から許可を得たものはネットにもアップしています。
データ分析基盤は社内の分析用途で用いられるため、通常そこまで高い可用性や即時性が求められることはないのですが、裏返すとそこまで緊急度の高い要件ではないので、なるだけ少人数で設計から構築、そのあとの運用まで面倒を見るケースがありました。
運用については昔はfluentdでログをバイパスするのが主流で、ログが詰まったりログの形式に気を遣ったりすることが多く、アラートの対応に追われることもありました。ですが、私は仕事の意識を切り替えるスイッチングコストのようなものがあまりないので、突発的な対応も私のタイプ的には向いていました。今はそのあたりはフルマネージドになって、かなり楽になったと思います。
上に書いたようなことや売上に直接関与しないことから、データエンジニアはコストセンターと見做される傾向があり、コスト圧縮のためになんでもかんでも一人に任せる一人データエンジニアという言葉が自嘲的に用いられるのを見かけたこともあります。
海外では、データ基盤のトレンドがモダンからライブ、つまり即時性の高いものに移り変わり始めており、日本でもデータエンジニアに人が投入され始め、だんだんプロフィットセンターとして扱われてきたのではないかと感じています。
フルスタックでのシステム開発
歴史のある会社では最近の開発の知見自体を持っていないことも多く、モダンな開発手法も併せて導入して欲しいというオーダーもありました。前述のスキルセットのくだりで紹介したように、データエンジニアのスキルはフルスタックに耐え得るものでもあるので、システムの基本設計から始まるほぼ全てを任せられました。
あまり具体的には言えないのですが、案件情報でたまに見かけることもありますが、内容としては世の中にはSalesforceやMarketoなどといったCRMをさらに自社向けにカスタマイズしたシステムを構築したいというオーダーで、波及的にマーケットリサーチのためにストーリーやKPIやNPSも考える必要もあり分析手法も学びました。
極力保守に耐え得る耐用年数の長いサービスを構築しようと、私は当時まだ利用者の少なかったdbt Cloudやfivetran、snowflakeといったツールを導入しました。これらサービスの現在の隆盛を考えると、その選定は間違っていなかったと胸を撫で下ろすと同時に、とても短いスピードで覇権サービスになった驚きもあります。
製造業のデータエンジニアリング
私は長く製造系の会社にいたので、製造系でどのように仕事を進めるのか理解しています。製造系では大人数で利用する大きなシステムが基本で、システム同士の連携に細かく気配りしたり開発にドキュメントを残すことが強く求められたり、web系やアプリ系に比べて一般的にシステム設計や技術選定に緻密さや慎重さが求められます。
こうした経験が元になっていて、私は今でも仕事でできるだけ多くのドキュメントを残すようにしています。web系やアプリ系のエンジニアは開発をスピーディーに進めるためドキュメントをなおざりにしがちなので、世のデータエンジニアの多くがそういった界隈の方であることを考えると、製造業のルールに倣うのはもどかしく感じることがあるかも知れません。
また、web系やアプリ系とは異なり、企業が販売しているものが実体のある製品であるため、組織で強い力を持っているのは製造部の人たちであることが多く、システム開発者に強い発言権が与えられることは少ないです。そのため、組織間での調整のスキルも求められます。
最近のトレンドを見ているとDXの波は製造業にも届いていて、私は近い将来、製造系はDXのマスマーケットとなるだろうと考えています。昨今の円安トレンドも長期的になる見通しで、製造業の国内回帰の流れがやってくると市場も大きくなると予想されます。そのため、上に書いたような製造業における振る舞いを知っていることは大きな強みになると考えています。

データエンジニアリングの将来
最後に、データエンジニアリングの分野においてこれからやってきそうなトレンドと、特にAIと密接に関係しそうな技術について触れていきます。
AIとデータエンジニアリング
AI技術の急速な台頭により、エンジニアの仕事は将来なくなってしまうのではないかという議論がたびたび起こります。ただ、そうしたブームの中においても、私はデータエンジニアはエンジニア全体の中でも比較的安定した立ち位置を取り続けることができるのではないかと楽観視しています。
その理由の一つは、データサイエンスが上で挙げたテクノロジー流行のハイプサイクルにおけるピークを何度か迎えたのに比べ、データエンジニアではまだピークにすら達していない点が挙げられます。データエンジニリングが描く流行のグラフは、とても勾配が緩やかであるか、もしくはとても大きなピークの山を登り始めているといったところではないでしょうか。
もう一つの理由は、データエンジニアの技術が、AIに必要とされる技術の根幹に位置していることが多く、AIで代替しにくいと考えているためです。
データエンジニアの領域は、AIが適切に稼働するための環境を整える部分が多く、AIが自分自身の動く環境を自動で構築するような自律的な判断ができるようになるのはまだまだ難しいはずです。
データエンジニアリングのトレンド
以下で紹介するDCRの技術や、データカタログの技術、ベクトルデータベースといった技術は、機械学習と密接に関わってくると考えられている次世代の技術です。共通するのは、AIが膨大なデータを資源とみなしてそれを学習や自動化に用いる点にあり、今後は、企業がそれぞれ独自で持つコアデータが競争力の源泉となり、データエンジニアの仕事はそれをどうやって管理していくかが課題となるでしょう。
最後はこれらを簡単に紹介して締めたいと思います。
Data Clean Room(DCR)
GoogleがGDPRなどの関わりによりCookieを段階的に廃止する告知をしてから、それに代わる技術としてデータクリーンルームという考え方が提唱されました。この技術の特徴は、従来のCDP(カスタマーデータプラットフォーム)とは異なり、自社のデータだけではない第三者のプライバシー情報を排したデータを利用できる点にあり、現段階で日本でも少しずつ導入の声を聞いています。
利用ケースとしては、たとえば、ある広告会社で蓄積した顧客情報を、購入者を特定できるだけの情報を抜き出した形で、飲料会社や製造会社などに提供し、将来の購買予測などに利用する。といったことが考えられます。
この技術が一般化すれば、自社でデータを所有することなく必要なデータを他社から借り受けることができるため、リソースの少ない会社でも質の高い分析が可能になると期待されています。
データカタログ
データカタログとは、データを整備する際に付加情報(メタデータ)をつけて管理することです。技術自体は昔から存在するものであり、資本力の強い大企業などではデータを整備する課題は喫緊であったため、infomaticaなどの有名なデータカタログサービスを用いてデータ管理を行ってきました。
ですが、現代はデータの利用者数が急速に増大しており、中小企業においてもデータを整備する課題が表面化してきました。そのため、コストが低くユーザフレンドリーなデータカタログのスタートアップに大きな注目が集まっています。
データの利用者はそれを専門的に扱う人だけでは無いので、わかりやすいようにデータの所在や作成時刻やメモなどといった付帯情報を付与して、利用を促す必要があります。データ利用者が利用するデータの品質を担保する側面もあります。

ベクトルデータベース
ベクトルデータベースとは、一般的なMySQLやpostgreSQLなどで使われるリレーショナルデータベースとは異なり、ベクトル情報で画像データやテキストデータなどを蓄えることができるデータベースです。
ベクトル情報とは、どの情報がどこにあるかを示す情報のことです。リレーショナルデータベースのように何行目の何列目にデータがある。というような方法よりもっと細かく位置を表現できるものと考えてください。画像や動画データのようなテキストに比べて重たいデータを検索するには、AIにわかりやすいようにそのような方法を用いています。
現時点では検索エンジニアや機械学習エンジニアが担っている領域ですが、今後、各企業が自身が持つコアデータをAIの学習に用いる時代になってくると、ベクトルデータベースを自前で持つ必要があり、数も増えて扱いやすい形になり、データエンジニアがベクトルデータベースを管理するようになってくるでしょう。
データ基盤開発・分析・ダッシュボード構築等の受託・業務委託のご依頼を承っております。 DataMarketではデータの利用シーンに応じて適切な知識や技術をご提供・ご提案し、企業の問題を解決いたします。 🏙 https://datamarket.co.jp