kaggle本の第4章をnoteで書いてみます。

執筆したkaggle本が、note.muだけでこれまで450冊以上を売り上げています。そのkaggle本の第4章のデータを可視化してみるという章をnoteで書いてみることにしたいと思います。
これまでコードのある記事は主にはてなブログを使っていたので、noteでのコードの記述がどれくらい使えるのか、試してみるためのチャレンジです。
4章全部を書くのは時間がかかるので、記載が途中ですが公開してしまって、少しずつ更新するのと、kaggle本では書けなかった可視化のコードも試してみたいと思います。
なお、kaggle本の第3章まではでSpeaker Deckで全て公開していますので、先に読むとわかりやすいです。
概要
Kaggle本で取り上げている、タイタニックチュートリアルコンペは、タイタニック号に乗船している乗客の、性別、年齢、運賃等と生死のデータからパターンを学習し、生死の情報がないテストデータの生存を予測するというコンペです。
タイタニックについては映画などで情報を持っているため、機械学習の知識がない入門者が初めに取り組みやすいので、とてもオススメです。
以下の説明を読んでいけばわかりますが、例えば子供や女性は生存率が高いとか、1等客室の乗客は生存率が高いという傾向が簡単にデータからわかります
ライブラリのインポートとデータの読み込み
# ライブラリの読み込み
import numpy as np
import pandas as pd
import matplotlib as mpl
import matplotlib.pyplot as plt
import seaborn as sns
# df_train、df_testとしてそれぞれ読み込み
df_train = pd.read_csv('../input/train.csv')
df_test = pd.read_csv('../input/test.csv')まずは、ライブラリをインポートして、csvデータを読み込みます。
データの概要を確認する
データの分析をする時は、初めは細部に入り込まずに、どのようなデータかという大枠を把握しながら、徐々に細部の確認をしていくことが重要になります。
データフレームとは、2次元 (行×列)のデータであり、イメージとしてはExcelシートのデータのようなものです。
データフレームを、列方向にみると、同じ特徴量のデータが並び (例えば、左から1列目にはAge列があり、年齢のデータが縦方向に並んでいます)、行方向にみるとある人のデータが並びます。
データフレームの中身を見てみましょう。データフレームは、df.head(n)で、nに好きな数字をいれると、最初のn行が表示されます。
df_train.head(5)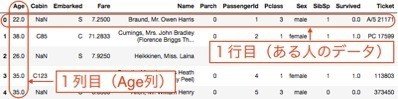
df_trainの初めの5行が表示されました。
このデータフレームは、5人のデータが並び、例えば1番上の人であれば、Ageが22.0、CabinがNaN、EmbarkedがSなどということを表しています。これがデータフレームです。
データフレームの行数と列数を確認
df.shapeにより、データフレームの行数と列数を確認することができます。
print(df_train.shape) # 学習用データ
print(df_test.shape) # 本番予測用データ
print(df_gender_submission.shape) # 提出データのサンプル(891, 12)
(418, 11)
(418, 2)それぞれ次の行数と列数を持つデータ構造だということがわかりました。
・ df_train : 891行×12列
・ df_test : 418行×11列
・ df_gender_submission : 418行×2列
本番予測用データであるdf_testは、学習用データであるdf_trainよりも正解 (生存)の列が1列少なくっています。
学習用データにより学習したモデルで、本番予測用データの生存予測をするためです。
列の名前の確認
df.columnsにより、列の名前を確認します。
print(df_train.columns) # トレーニングデータの列名
print('-'*10) # 区切りを挿入
print(df_test.columns) # テストデータの列名Index(['PassengerId', 'Survived', 'Pclass', 'Name', 'Sex', 'Age', 'SibSp','Parch', 'Ticket', 'Fare', 'Cabin', 'Embarked'],
dtype='object')
----------
Index(['PassengerId', 'Pclass', 'Name', 'Sex', 'Age', 'SibSp', 'Parch','Ticket', 'Fare', 'Cabin', 'Embarked'],
dtype='object')df_trainには、「'PassengerId', 'Survived', 'Pclass', 'Name', 'Sex', 'Age', 'SibSp','Parch', 'Ticket', 'Fare', 'Cabin', 'Embarked'」の12列が含まれることがわかります。
また、df_testは、予測を行う「Survived」の列がないものの、他はdf_trainと同じことがわかります。
続きは、次のnoteを参照ください。
コメントお待ちしています。匿名の質問はマシュマロから→https://marshmallow-qa.com/currypurin