
遺伝的アルゴリズムを用いたペア作成ロジックを作ってみた
こんにちは、buildサービス部の鈴木です。
冬もようやく終わりが見え始め、初春が各地で見え始めてきました。自分もこの前、水戸の偕楽園に行き春の訪れを感じてきました。
年度末まであと数週間、最後まで全力で頑張りたいですね。
さて、今回はつい先日、新たなサービスの開発に携わったのですが、そのサービスにおいてユーザーのペアを毎週シャッフルして決めるという要件がありました。
単にペアを作るだけであれば、ランダムに毎週シャッフルして割り当てればいいのですが、利用者目線を考えれば、ペアを作成するにあたって、
スキップを選択しているユーザーは抽選から除外
前回と同じペアは避ける
できるだけ組んだことのないペアを作成したい
といった要望があると思います。こういった要望も踏まえた最適化も踏まえてペア作成を行う場合は当然ランダムに割り当てるのでは不十分で、スポーツの試合みたいにあらかじめペアが一巡するサイクルを作るのはランダムにスキップするユーザーが発生するため不可能、全通り探索して最適なものを見つけるという方法も人数が増えればそれだけ計算量が増大し探索は困難を極め、また雑な探索だと最適解よりも接点がない人同士の組み合わせ数が少なかったり、 制約を満たせなかったりするかもしれません。
そのため、何かしらの最適化手法を用いてペア作成を行う必要があり、今回は最適化手法として遺伝的アルゴリズムを用いて最適なペア作成を行いました。
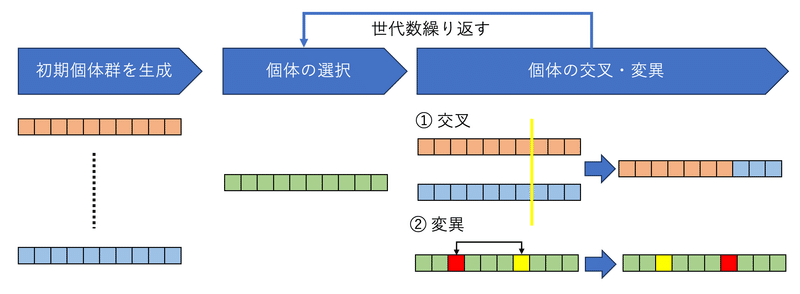
遺伝的アルゴリズムの概要
遺伝的アルゴリズム(Genetic Algorithm, GA)は、進化的アルゴリズムの一種で、自然界の進化のプロセスから着想を得た最適化手法です。
主に、最適な解を見つけるために個体集団を進化させることに特化しています。以下に遺伝的アルゴリズムの基本的な概念を説明します:
個体(Individual):
個体は問題の解を表します。これは通常、数値ベクトルや文字列などで表現されます。個体は遺伝子と呼ばれる要素から成り立っています。
遺伝子(Gene):
遺伝子は個体を構成する要素で、通常は問題の特定のパラメータを表現します。遺伝子は数値や文字などの形で表現され、個体の性質を形成します。
適応度関数(Fitness Function):
適応度関数は、個体が問題を解くのにどれだけ優れているかを評価するための関数です。高い適応度の個体が、問題の最適解に近い可能性が高いです。
この評価関数の定義によって結果が如何様にもなりえます。
集団(Population):
個体の集まりを指します。アルゴリズムは、この集団を進化させ、より良い解に収束させようとします。
選択(Selection):
適応度の高い個体を選び、次の世代に保持する操作です。選択のプロセスにより、適応度の高い個体が次の世代に引き継がれますが、その選択方法には様々なものがあります。
交叉(Crossover):
2つの親個体から新しい個体を生成する操作です。これにより、親個体の特徴が組み合わさります。遺伝子が交換されることで新たな個体が生まれ、多様性が生まれます。
突然変異(Mutation):
個体の遺伝子をランダムに変更する操作です。突然変異は、新しい情報を導入し、集団の多様性を保つ役割があります。
収束(Convergence):
アルゴリズムが進化する中で、集団が最適解に収束することを指します。これにより、問題の最適な解に近づくことが期待されます。
遺伝的アルゴリズムは、探索空間が大きく、複雑な問題に対して広く使用されています。特に、組み合わせ最適化、スケジューリング、機械学習のハイパーパラメータ最適化などの領域で利用されています。
一方でパラメータチューニング等をうまく設定しないと局所解に陥ってしまうので、設定が重要になります。
ペア作成に対する適用
実装環境
Node.jsランタイムのTypescriptコードでAWSのLambdaを定期的にEventbridgeでトリガーすることにより実行
遺伝子
各ユーザーを格納した配列とし、前から二つずつをそれぞれペアと表現するように定義しました。
評価関数
前回ペアになった人とまたペアになった場合は大幅に減点
// 前回のペアと同じ場合は減点
if (i % 2 === 0) {
const previousPairId = previousPairs.find((pair) => pair.userId === entity[i].userId)?.pairUserId;
if (entity[i + 1].userId === previousPairId) {
score -= 100;
}
} 全ペアの履歴を集計し平均ペア回数を計算し、今回のペアが平均ペア回数よりも多い場合は減点、少ない場合は加点
この点数は、平均との乖離が大きければ大きいほど上がっていくようにする。(今回は切り上げした差分の二乗をかけることにしました)
// ペアの回数が多い人とペアになった場合は減点 entitySizeは参加者数
if (pairInfo.pairHistory.length > averagePairHistory) {
score -= (100 * Math.pow(Math.ceil(pairInfo.pairHistory.length - averagePairHistory) + 1, 2)) / entitySize;
} else {
// ペア回数が特に少ない人とペアの場合は加点
score += (100 * Math.pow(Math.ceil(averagePairHistory - pairInfo.pairHistory.length) + 1, 2)) / entitySize;
}交叉
一様交叉や二点交叉といった交叉方法もありますが、今回はシンプルに一点交叉法で実装しました。
片方の遺伝子(A)の配列を一点で分けて、残りの部分をもう片方の遺伝子(B)で結合しました。単純に結合するとユーザーが被るので、結合する際に採用するAの配列に存在するユーザーは除外した配列をBから生成し、それを結合させます。
交叉の際の親遺伝子は、逆関数法でスコアの良い個体が他よりも多少選ばれやすいようにしました。
function crossOver(populations: populationsType): FindCurrentPairResponse[] {
// 全順位の合計値を出す
const num = arithmeticSequenceSum(populations.length);
// 合計値から乱数を出す
const r1 = Math.random() * num;
const r2 = Math.random() * num;
// 逆関数で選択する順位を求める
const parent1Index = Math.ceil(arithmeticSequenceSumInverse(r1)) - 1;
const parent2Index = Math.ceil(arithmeticSequenceSumInverse(r2)) - 1;
// 一点で交叉
const idx = Math.floor(Math.random() * (populations[parent1Index].individual.length + 1));
const p1 = populations[parent1Index].individual.slice(0, idx);
const p2 = populations[parent2Index].individual.filter((x) => !p1.includes(x));
const child = p1.concat(p2);
return child;
}
// 等差数列の和
function arithmeticSequenceSum(size: number, start = 1, diff = 1) {
return (size * (2 * start + (size - 1) * diff)) / 2;
}
// 等差数列の和の逆関数
function arithmeticSequenceSumInverse(val: number, start = 1, diff = 1) {
if (diff == 0) return val;
const t = diff - 2 * start + Math.sqrt((2 * start - diff) ** 2 + 8 * diff * val);
return t / (2 * diff);
}
突然変異
遺伝子の配列の要素をランダム確率で二つ選択して並び替える処理をいれました。
選択
個体の内、最高スコアの1個体のみを次世代に残し後は淘汰(交叉の対象)する方式にしました。
実装してみた結果
実際にペア作成処理を回してみたところ、前の人と同じペアになるということは一度も起きませんでした。
できるだけ偏りなくペアを作成する要件も、必ず最適なペアの組み合わせを作れるわけではなく、多少は偏りは生じてしまうことはあったものの、回数の少ないペアは積極的に作られるようにペア作成を最適化することができました。少なくとも、平均ペア回数より2を超えてペア回数を記録するペアはありませんでした。
これをもしランダムで実装したら、前の人と2回連続ということも起こり得たと思うのでだいぶ最適化されたと思います。
まとめ
遺伝的アルゴリズムは、比較的簡単に遺伝子の設定や評価関数の作成が行えるので、ぜひ実装に何かしら簡単な最適化機能を盛り込みたい場合は、候補として検討してみてはいかがでしょうか。