J-Quants APIを用いたファクター時系列の可視化(google colabコードあり)
はじめに
本記事では,日本株に関するデータを取得できるJ-Quants APIを用いてファクター分析を行います。
主要なファクターについて,それぞれの年次パフォーマンスを時系列で比較するgoogle colabで実行可能なコードを紹介します。
ファクター(投資)とは
ファクター投資は、ある特性や属性(ファクター)を持つ株式や債券に焦点を当てた投資手法です。これは、市場全体や特定のセクターに投資するのではなく、長期的にリターンをもたらすと考えられる特定の要因に基づいて投資する方法です。
ファクターには様々な種類がありますが、最も一般的なものは「バリュー(割安性)」、「サイズ(企業規模)」、「モメンタム(勢い)」、「クオリティ(企業の健全性)」、「低ボラティリティ(価格の変動が少ない)」などです。例えば、バリュー投資では、株価が本来の価値に比べて低いと判断される企業に投資します。一方、モメンタム投資では、価格が上昇傾向にある株式に焦点を当てます。
これらのファクターは歴史的に市場平均を上回るリターンを提供してきたという研究結果が多くあります。
ファクターリターンについて
今回,ファクターのパフォーマンスの計測には,ファクターリターンを使用します。
時刻tにおけるファクターリターンfは,銘柄iのリターンrを,銘柄iのファクター値(ファクターエクスポージャー)をxとして以下の通り線型回帰した時の回帰係数です。
$$
r _{i,t}= f_t×x_{i,t}+u_{i,t}
$$
ファクターリターンfを時系列で積み上げることで各ファクターがどの時期にアウトパフォームしていたかを確認することが出来ます。
補足:
例えば,時刻tにおけるfが正であればファクター値xとリターンrは正の相関を持つことになります。このfをt=1からTで時系列で積み上げて右肩上がりになれば,ユニバース全体のリターンは,そのファクターに対して安定的に正の相関を持つことになります。
それではファクターリターンを計算し,可視化するための実際のコードを記載していきます。コード全文は記事の末尾に記載していますので適宜ご参照ください。
コード部分
環境設定
必要なライブラリをインポートします。
これ以降のコードはgoogle colabでの実行を想定しています。
ローカル環境で実行する場合は適切に修正してください。
import os
from datetime import datetime, timedelta
import pandas as pd
import numpy as np
import os
import joblib
from sklearn.linear_model import LinearRegression
import matplotlib.pyplot as plt
from tqdm.auto import tqdm
# Googleドライブのパス
GOOGLE_DRIVE_DIR_PATH = "/content/drive/MyDrive"
# Googleドライブをマウント
from google.colab import drive
drive.mount('/content/drive')
! pip install jquants-api-client
import jquantsapi
cli = jquantsapi.Client()google drive上で保存するファイルのディレクトリとパスを指定します。
dir_path = f'{GOOGLE_DRIVE_DIR_PATH}/JQ_factor_analysis/'
if not os.path.exists(dir_path):
os.makedirs(dir_path)
filepath_stock_fin = os.path.join(dir_path, 'stock_fin_load.csv.gz')
filepath_stock_price = os.path.join(dir_path, 'stock_price_load.csv.gz')
filepath_stock_list = os.path.join(dir_path, 'stock_list_load.gz')各種データを新規取得する際に必要なデータ取得期間を指定します。
今回データ取得期間はJ-Quants APIのライトプランを前提として過去5年分にしています。無料プランの場合は過去2年分を取得できます。
# J-Quants API から取得するデータの期間
HISTORICAL_DATA_YEARS = 5
start_dt: datetime = datetime.now().replace(hour=0, minute=0, second=0, microsecond=0) - timedelta(days=(HISTORICAL_DATA_YEARS*365))
end_dt: datetime = datetime.now().replace(hour=0, minute=0, second=0, microsecond=0)データ取得
今回のユニバースは現時点でTOPIX500に採用されている銘柄とします。
これらの銘柄のコードを取得するために,上場銘柄一覧をAPIで取得します。
if os.path.exists(filepath_stock_list):
# ファイルが存在する場合、読み込む
stock_list_load = pd.read_csv(filepath_stock_list, compression='gzip')
else:
# ファイルが存在しない場合、新たに作成する
stock_list_load = cli.get_listed_info()
stock_list_load.to_csv(filepath_stock_list, compression='gzip', index=False)
# 株価情報のobject型をdatetime64[ns]型に変換
stock_list_load["Date"] = pd.to_datetime(stock_list_load["Date"])
# 普通株 (5桁で末尾が0) の銘柄コードを4桁にします
stock_list_load["Code"] = stock_list_load["Code"].astype(str)
stock_list_load.loc[(stock_list_load["Code"].str.len() == 5) & (stock_list_load["Code"].str[-1] == "0"), "Code"] = stock_list_load.loc[(stock_list_load["Code"].str.len() == 5) & (stock_list_load["Code"].str[-1] == "0"), "Code"].str[:-1]
stock_list_load
TOPIX採用銘柄のcodeを取得します。
# TOPIX500のtickerのみを取得する
categories = ['TOPIX Mid400', 'TOPIX Large70', 'TOPIX Core30']
codes = stock_list_load[stock_list_load['ScaleCategory'].isin(categories)]['Code'].unique()
codes = codes.astype(str)
codes
次に財務情報を取得します。時価総額,PBR,ROEの計算で必要になります。(詳細は後述)
if os.path.exists(filepath_stock_fin):
# ファイルが存在する場合、読み込む
stock_fin_load = pd.read_csv(filepath_stock_fin, compression='gzip')
else:
# ファイルが存在しない場合、新たに作成する
stock_fin_load = cli.get_statements_range(start_dt=start_dt, end_dt=end_dt)
stock_fin_load.to_csv(filepath_stock_fin, compression='gzip', index=False)
stock_fin_load = stock_fin_load.rename(columns={'DisclosedDate':'Date','LocalCode':'Code'})
# 普通株 (5桁で末尾が0) の銘柄コードを4桁にします
stock_fin_load["Code"] = stock_fin_load["Code"].astype(str)
stock_fin_load.loc[(stock_fin_load["Code"].str.len() == 5) & (stock_fin_load["Code"].str[-1] == "0"), "Code"] = stock_fin_load.loc[(stock_fin_load["Code"].str.len() == 5) & (stock_fin_load["Code"].str[-1] == "0"), "Code"].str[:-1]
stock_fin_load
次に価格情報を取得します。騰落率やリターンはこれを元に計算します。(詳細は後述)
if os.path.exists(filepath_stock_price):
# ファイルが存在する場合、読み込む
stock_price_load = pd.read_csv(filepath_stock_price, compression='gzip')
else:
# ファイルが存在しない場合、新たに作成する
stock_price_load = cli.get_price_range(start_dt=start_dt, end_dt=end_dt)
stock_price_load.to_csv(filepath_stock_price, compression='gzip', index=False)
# 普通株 (5桁で末尾が0) の銘柄コードを4桁にします
stock_price_load["Code"] = stock_price_load["Code"].astype(str)
stock_price_load.loc[(stock_price_load["Code"].str.len() == 5) & (stock_price_load["Code"].str[-1] == "0"), "Code"] = stock_price_load.loc[(stock_price_load["Code"].str.len() == 5) & (stock_price_load["Code"].str[-1] == "0"), "Code"].str[:-1]
stock_price_load
ファクター値の計算
データが取得できたので,各ファクター値を計算する準備をしていきます。
ここで,今回計算するファクターと,そのファクターを計測する特徴量の計算式を示します。
バリュー
割安な株は割高な株に対してアウトパフォームするというものです。今回はPBRの逆数を使います。
PBR = 株価 / 一株あたり純資産(BPS)クオリティ
収益性の高い株がアウトパフォームするというものです。今回はROEを用います。
ROE = 一株あたり利益 (EPS)/ 一株あたり純資産(BPS)サイズ
小型株が大型株をアウトパフォームするというものです。今回は時価総額の逆数を使用します。(時価総額が小さい方がアウトパフォームするから)
時価総額 = 株価 × 発行済株式数モメンタム
価格が上昇している株は,さらに上昇し続けるというものです。今回は252日騰落率を使用します。
252日騰落率 = 当日終値 / 252日前の終値
時価総額,PBR,ROEの計算に使用するBPS,来期予想EPS,期末発行済株式数を抽出し,df_finとします。
def get_fundas(stock_fin_load, code):
df_fin = stock_fin_load.loc[stock_fin_load['Code'] == code].copy()
df_fin = df_fin[['Code','Date','BookValuePerShare','ForecastEarningsPerShare','NumberOfIssuedAndOutstandingSharesAtTheEndOfFiscalYearIncludingTreasuryStock']]
return df_fin
list_fin = []
for code in tqdm(codes):
buf = get_fundas(stock_fin_load, code)
list_fin.append(buf)
df_fin = pd.concat(list_fin)
df_fin
続いて価格情報をもとに,各銘柄のリターンと騰落率を計算し,df_priceとします。
window = [ 1, 25, 75, 252 ]
def get_label(stock_price_load, code):
df_price = stock_price_load.loc[stock_price_load['Code'] == code].copy()
for fw in window:
df_price[f'mom{fw}'] = df_price['AdjustmentClose'].pct_change(fw).fillna(0)
df_price[f'ret{fw}'] = (df_price['AdjustmentClose'].shift(-fw) / df_price['AdjustmentClose'] - 1.0).fillna(0)
return df_price
list_label = []
for code in tqdm(codes):
buf = get_label(stock_price_load, code)
list_label.append(buf)
df_price = pd.concat(list_label)
df_price
財務情報(df_fin)と価格情報(df_price)をmergeします。
df_fin['Date'] = pd.to_datetime(df_fin['Date'])
df_price['Date'] = pd.to_datetime(df_price['Date'])
df_merge = pd.merge(df_price, df_fin, on=['Date','Code'], how='left')各ファクター値を計算します。
サイズファクターでは時価総額が小さい方が優位,バリューファクターではPBRが低い方が優位であるとされていることから,時価総額とPBRは逆数を取ります。BPRとはPBRの逆数です。
また,財務指標は四半期決算の日以外はNaNになっているので,ffillします。
df_merge['BookValuePerShare'] = df_merge.groupby('Code')['BookValuePerShare'].ffill()
df_merge['ForecastEarningsPerShare'] = df_merge.groupby('Code')['ForecastEarningsPerShare'].ffill()
df_merge['NumberOfIssuedAndOutstandingSharesAtTheEndOfFiscalYearIncludingTreasuryStock'] = df_merge.groupby('Code')['NumberOfIssuedAndOutstandingSharesAtTheEndOfFiscalYearIncludingTreasuryStock'].ffill()
df_merge['BPR'] = 1 / (df_merge['AdjustmentClose'] / df_merge['BookValuePerShare'])
df_merge['ROE'] = df_merge['ForecastEarningsPerShare'] / df_merge['BookValuePerShare'])
df_merge['1/market_cap'] = -np.log(df_merge['AdjustmentClose'] * df_merge['NumberOfIssuedAndOutstandingSharesAtTheEndOfFiscalYearIncludingTreasuryStock'])
df_merge = df_merge.dropna()
df_merge
重回帰分析
「ファクターリターンについて」で前述した式の通り,時刻tごとに各銘柄のリターンrを各ファクター値xで重回帰し,その回帰係数(ファクターリターンf)の時系列を取得します。
# 分析に使用するファクター
factors = ['1/market_cap', 'BPR', 'mom252', 'ROE']
target = 'ret1'
# 線形回帰モデルの初期化
model = LinearRegression()
# 時刻tごとに線形回帰を行い、各ファクターのリターンを計算
factor_return = {}
for date in tqdm(df_merge['Date'].sort_values().unique()):
# 当該日のデータ
daily_data = df_merge[df_merge['Date'] == date]
# daily_dataが十分な数存在しない場合はスキップ。今回は10とした。
if len(daily_data) < 10:
continue
# 説明変数と目的変数を定義
X = daily_data[factors].rank(pct=True)
y = daily_data[target]
# モデルの訓練
model.fit(X, y)
# 係数(ファクターリターン)を記録
factor_return[date] = model.coef_ファクターリターンの可視化
計算したファクターリターンを可視化します。
# ファクターリターンのDataFrameを作成
df_factor = pd.DataFrame(factor_return.values(),
index=factor_return.keys(),
columns=factors,
)
# ファクターリターンの累積和をプロット
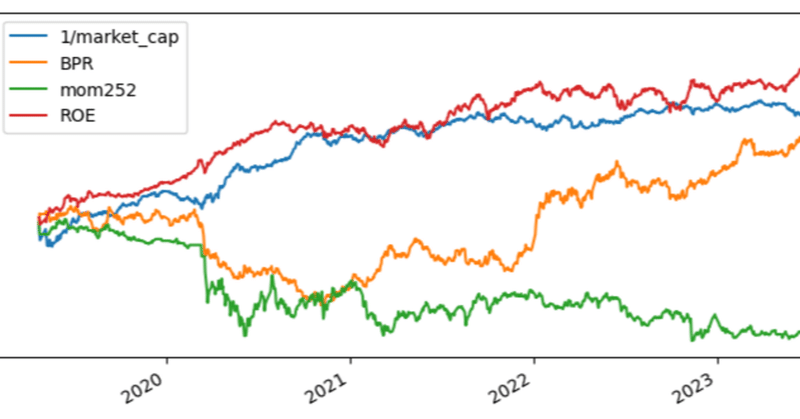
df_factor.cumsum().plot(figsize=(10, 4))
plt.show()
# 年次の平均ファクターリターンを計算
df_factor['Year'] = pd.to_datetime(df_factor.index).year
mean_values = df_factor.groupby('Year').mean()
# 年次の平均ファクターリターンの棒グラフをプロット
mean_values.plot(kind='bar', capsize=4)
plt.show()

ファクターリターン時系列の分析
1/market_cap, BPR, mom252, ROEはそれぞれサイズ,バリュー,モメンタム,クオリティを表しています。
ファクターリターンの時系列から例えば次の傾向が確認できます。
サイズ:2020年頃までは小型株優位であったが,徐々に大型株優位な相場になってきている。(外国人投資家の影響?)
バリュー:2020年まではグロース相場であったが,2021年以降はバリュー株優位になっている。(米国長期金利上昇の影響?)
モメンタム:2024年を除いてマイナス推移。すなわち逆張り優位。一方,まだ3ヶ月弱ではあるが2024年はモメンタムが強い?(外国人投資家の影響?)
クオリティ:2022年を除いてクオリティの高い銘柄がアウトパフォーム。
まとめ
この記事では、J-Quants APIを使用してTOPIX500に採用されている銘柄の財務および価格データを取得し、バリュー、クオリティ、サイズ、モメンタムの四つのファクターを用いてファクターリターンを計測し,その時系列を可視化するコードを紹介しました。
このコードを元に,他のファクターも計測してみる,年次ではなく月次で集計しアノマリーを観察してみる(sell in May等),セクターで基準化してみるなど,更なる検証にご活用ください。
コード全文
import os
from datetime import datetime, timedelta
import pandas as pd
import numpy as np
import joblib
from sklearn.linear_model import LinearRegression
import matplotlib.pyplot as plt
from tqdm.auto import tqdm
# Googleドライブのパス
GOOGLE_DRIVE_DIR_PATH = "/content/drive/MyDrive"
# Googleドライブをマウント
from google.colab import drive
drive.mount('/content/drive')
! pip install jquants-api-client
import jquantsapi
cli = jquantsapi.Client()
dir_path = f'{GOOGLE_DRIVE_DIR_PATH}/JQ_factor_analysis/'
if not os.path.exists(dir_path):
os.makedirs(dir_path)
filepath_stock_fin = os.path.join(dir_path, 'stock_fin_load.csv.gz')
filepath_stock_price = os.path.join(dir_path, 'stock_price_load.csv.gz')
filepath_stock_list = os.path.join(dir_path, 'stock_list_load.gz')
HISTORICAL_DATA_YEARS = 5
start_dt = datetime.now().replace(hour=0, minute=0, second=0, microsecond=0) - timedelta(days=(HISTORICAL_DATA_YEARS*365))
end_dt = datetime.now().replace(hour=0, minute=0, second=0, microsecond=0)
if os.path.exists(filepath_stock_list):
stock_list_load = pd.read_csv(filepath_stock_list, compression='gzip')
else:
stock_list_load = cli.get_listed_info()
stock_list_load.to_csv(filepath_stock_list, compression='gzip', index=False)
stock_list_load["Date"] = pd.to_datetime(stock_list_load["Date"])
stock_list_load["Code"] = stock_list_load["Code"].astype(str)
stock_list_load.loc[(stock_list_load["Code"].str.len() == 5) & (stock_list_load["Code"].str[-1] == "0"), "Code"] = stock_list_load["Code"].str[:-1]
categories = ['TOPIX Mid400', 'TOPIX Large70', 'TOPIX Core30']
codes = stock_list_load[stock_list_load['ScaleCategory'].isin(categories)]['Code'].unique()
codes = codes.astype(str)
if os.path.exists(filepath_stock_fin):
stock_fin_load = pd.read_csv(filepath_stock_fin, compression='gzip')
else:
stock_fin_load = cli.get_statements_range(start_dt=start_dt, end_dt=end_dt)
stock_fin_load.to_csv(filepath_stock_fin, compression='gzip', index=False)
stock_fin_load = stock_fin_load.rename(columns={'DisclosedDate':'Date','LocalCode':'Code'})
stock_fin_load["Code"] = stock_fin_load["Code"].astype(str)
stock_fin_load.loc[(stock_fin_load["Code"].str.len() == 5) & (stock_fin_load["Code"].str[-1] == "0"), "Code"] = stock_fin_load["Code"].str[:-1]
if os.path.exists(filepath_stock_price):
stock_price_load = pd.read_csv(filepath_stock_price, compression='gzip')
else:
stock_price_load = cli.get_price_range(start_dt=start_dt, end_dt=end_dt)
stock_price_load.to_csv(filepath_stock_price, compression='gzip', index=False)
stock_price_load["Code"] = stock_price_load["Code"].astype(str)
stock_price_load.loc[(stock_price_load["Code"].str.len() == 5) & (stock_price_load["Code"].str[-1] == "0"), "Code"] = stock_price_load["Code"].str[:-1]
def get_fundas(stock_fin_load, code):
df_fin = stock_fin_load.loc[stock_fin_load['Code'] == code].copy()
df_fin = df_fin[['Code','Date','BookValuePerShare','ForecastEarningsPerShare','NumberOfIssuedAndOutstandingSharesAtTheEndOfFiscalYearIncludingTreasuryStock']]
return df_fin
list_fin = []
for code in tqdm(codes):
buf = get_fundas(stock_fin_load, code)
list_fin.append(buf)
df_fin = pd.concat(list_fin)
window = [1, 25, 75, 252]
def get_label(stock_price_load, code):
df_price = stock_price_load.loc[stock_price_load['Code'] == code].copy()
for fw in window:
df_price[f'mom{fw}'] = df_price['AdjustmentClose'].pct_change(fw).fillna(0)
df_price[f'ret{fw}'] = (df_price['AdjustmentClose'].shift(-fw) / df_price['AdjustmentClose'] - 1.0).fillna(0)
return df_price
list_label = []
for code in tqdm(codes):
buf = get_label(stock_price_load, code)
list_label.append(buf)
df_price = pd.concat(list_label)
df_fin['Date'] = pd.to_datetime(df_fin['Date'])
df_price['Date'] = pd.to_datetime(df_price['Date'])
df_merge = pd.merge(df_price, df_fin, on=['Date','Code'], how='left')
df_merge['BookValuePerShare'] = df_merge.groupby('Code')['BookValuePerShare'].ffill()
df_merge['ForecastEarningsPerShare'] = df_merge.groupby('Code')['ForecastEarningsPerShare'].ffill()
df_merge['NumberOfIssuedAndOutstandingSharesAtTheEndOfFiscalYearIncludingTreasuryStock'] = df_merge.groupby('Code')['NumberOfIssuedAndOutstandingSharesAtTheEndOfFiscalYearIncludingTreasuryStock'].ffill()
df_merge['BPR'] = 1 / (df_merge['AdjustmentClose'] / df_merge['BookValuePerShare'])
df_merge['ROE'] = df_merge['ForecastEarningsPerShare'] / df_merge['BookValuePerShare']
df_merge['1/market_cap'] = -np.log(df_merge['AdjustmentClose'] * df_merge['NumberOfIssuedAndOutstandingSharesAtTheEndOfFiscalYearIncludingTreasuryStock'])
df_merge = df_merge.dropna()
factors = ['1/market_cap', 'BPR', 'mom252', 'ROE']
target = 'ret1'
model = LinearRegression()
factor_return = {}
for date in tqdm(df_merge['Date'].sort_values().unique()):
daily_data = df_merge[df_merge['Date'] == date]
if len(daily_data) < 10:
continue
X = daily_data[factors].rank(pct=True)
y = daily_data[target]
model.fit(X, y)
factor_return[date] = model.coef_
df_factor = pd.DataFrame(factor_return.values(), index=factor_return.keys(), columns=factors)
df_factor.cumsum().plot(figsize=(10, 4))
plt.show()
df_factor['Year'] = pd.to_datetime(df_factor.index).year
mean_values = df_factor.groupby('Year').mean()
mean_values.plot(kind='bar', capsize=4)
plt.show()
参考
本記事を作成するにあたって,参考にした本を次の記事で紹介しています。
次の一歩になりそうな考え方も記載しておりますのでご参考までに。
この記事が気に入ったらサポートをしてみませんか?