中心極限定理

中心極限定理をご存知でしょうか。
あまり聞いたことがないかも知れません。
どの様なものかというと・・・
特定の条件下であれば
サンプルサイズnが大きくなるにつれて
サンプル平均の分布が・・・
正規分布に近似する
というものです。
ただし、勘違いしないでください。
データを沢山集めれば良いわけではないのです。
サンプル平均を集めないといけません。
例えば、1000日分の輸液ポンプ貸出し台数を
記録していたとします。
n = 1000ですね。
しかし、このデータをヒストグラムにしたところで
正規分布にはなることは保証されていません。
輸液ポンプの貸出台数について発表したかったのに
発表に必要な統計手法が正規分布を前提にしたもの
だったら悲しすぎますよね。
一方、中心極限定理では、1000個のデータの中から
無作為に5個のデータを抽出して平均値を算出する。
(抽出する数に決まりはありません)
これをサンプル平均と呼びます。
そしてサンプル平均を沢山集めれば・・・
正規分布に近づくというのです。
そんな馬鹿なと思うでしょう。
眉唾です。
その気持ちはわかりますので
pythonで実装してみたいと思います。
今回、サンプル平均算出に使用したデータは平均値算出後
元に戻しています。
いわゆる復元抽出を採用します。
#仮想1000日分の輸液ポンプ貸出台数(ランダムな1000個のデータを生成)
randoms = [int(np.random.random() * 100) for i in range(1000)]
#1000日分の輸液ポンプ貸出台数から5個を無作為に抽出し平均値算出
#これを1000回繰り返してサンプル平均1000個を用意
randoms_mean = [np.mean(np.random.choice(randoms, size=5, replace=True)) for i in range(1000)]1000日分の輸液ポンプ貸出データであるrandomsと
randomsから5個を無作為に抽出して平均を算出。これを
1000回行ったrandoms_meanを用意できました。
randoms、randoms_mean両者ともn = 1000です。
それではヒストグラムで確認してみましょう。
plt.figure(figsize = (10,5))
plt.subplot(1,2,1)
plt.hist(randoms)
plt.grid()
plt.title(f'{len(randoms)}日分の輸液ポンプ貸出台数 n = {len(randoms)}')
plt.subplot(1,2,2)
plt.hist(randoms_mean)
plt.grid()
plt.title(f'サンプル平均 n = {len(randoms_mean)}')このコードを実行すると下の様な図になりました。
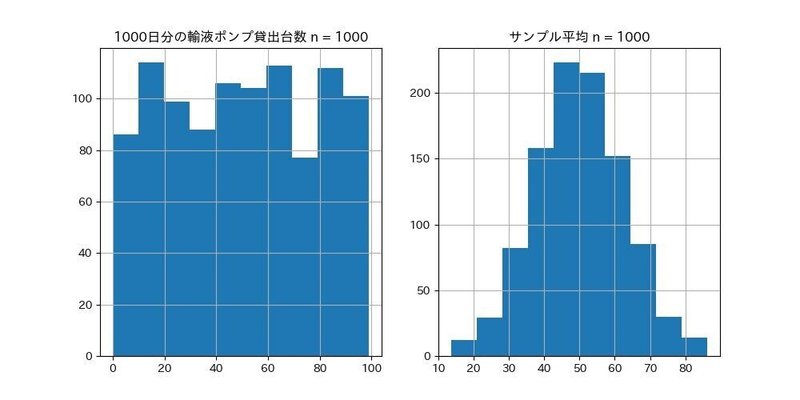
同じデータなのに不思議ですよね。
中心極限定理が気になった方は深掘りしてみて、
是非、色々と教えてください。
この記事が気に入ったらサポートをしてみませんか?