
LLM組み込みデータ駆動型のE2E自動テスト

ソフトウェアのプログラム中にLLMのAPI呼び出しを埋め込んで、返ってきたデータをプログラムの中で動的に利用するという手法があります。
これをテスト自動化に応用したものを考えてみました。LLMで動的にテストデータを生成させて、データ駆動で自動テストに適用する、というものです。
まずは結果から
テスト自動化の練習のためのホテル予約サイト(https://hotel.testplanisphere.dev/ja/)のログイン画面を題材に、入力されたメールアドレスのフォーマット検証に対してテストデータを生成し、テストを実行します。なお、プログラムによって複数回テストを実行することになるので、実際のテストはlocalhostで行っています。
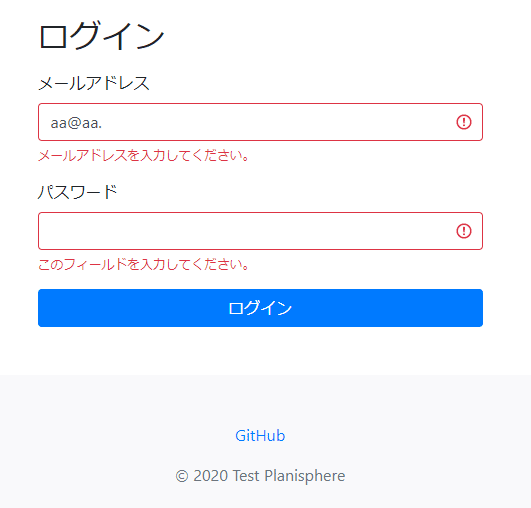
結果、練習サイトで使われているメールアドレス検証のライブラリに対しては、いくつかの「Failed=不正なメールアドレスに対して警告メッセージが表示されない」が検出できました。

上記の図では、 data_in にLLMが生成した「不正なフォーマットのメールアドレス」が指定されています=Failedとなるテストデータ。
GPT APIの呼び出し
現在、GPTのAPIは明示的にJSONで出力をするように指示ができるようになっていて、これまでコンテキストでお祈りしなければならなかったのに比べてLLMにデータを生成させることが格段にやりやすくなっています。
A common way to use Chat Completions is to instruct the model to always return a JSON object that makes sense for your use case, by specifying this in the system message. While this does work in some cases, occasionally the models may generate output that does not parse to valid JSON objects.
今回はメールアドレスの形式バリデーションをお題として、以下のような設定で、データを生成させてみました。
client = OpenAI()
completion = client.chat.completions.create(
model="gpt-4-turbo",
response_format={"type": "json_object"},
messages=[
{"role": "system", "content": "You are professional test engineer. You must only return test data. json_format is recommended. First level element of the format must be invalid_emails."},
{"role": "user", "content": "Generate 10 test data for email addresses that are not appropriate as a form of email address."}
]
)response_format={"type": "json_object"}, を指定することで、明示的にJSONで応答が返されますが、role メッセージにも、”出力はJSONで行うこと” といったテキストを含める必要があります。
openai.BadRequestError: Error code: 400 - {'error': {'message': "'messages' must contain the word 'jsone_format' of type 'json_object'.", 'type': 'invalid_request_error', 'param': 'messages', 'code': None}}
role メッセージにJSON指示がない場合、上記のBad Requestが返ります。
データ駆動テスト
LLMによってテストデータがJSONで得られるので、あとは pytest 用のデータ駆動テストフレームワークである、parametrize を使ってplaywrightのE2Eテストスクリプトにデータを受け渡すだけでデータ駆動のテストが実現できます。
※parametrizeはpytestの機能なので自動テストフレームワークは必ずしもplaywrightである必要はありません
@pytest.mark.parametrize("data_in", data['invalid_emails'])
def test_post_testdata_to_login_email_field(data_in, page: Page, playwright: Playwright):
browser = playwright.chromium.launch(headless=False,channel="chrome")
page = browser.new_page()
page.set_default_timeout(3000)
page.goto("http://localhost:8000/ja/login.html", wait_until='networkidle')
page.screenshot(path="screenshot.png")
print("test data: " + data_in + " is used.)")
page.get_by_label("メールアドレス").fill(data_in)
page.locator('button[type=submit]').click()
expect(page.locator(".invalid-feedback").first).to_contain_text("メールアドレスを入力してください。")このアプローチは自動テストに活用できるのか?
まず、LLMに直接生成させたテストケースは人間のテスト設計によって導出されたデータと比べて網羅性に難があります。正確には今回のような(広義の)モデルとその網羅アルゴリズムを指定しないプロンプトでは、なにをどう、網羅したのか確認する方法がありません。
逆に言うと、プロンプトでデータのモデルとその網羅方法を適切に指示できるならば、LLMに生成させることも可能かも知れません。例えば以下のようなアプローチです。
RFC920で定義されているgTLD(.com, .edu, .gov, .mil, .org)それぞれに対して2つ以上、フォーマットとして不適切なメールアドレスを生成してください
このような指示では「gTLDの一覧」という(広義の)モデルに対して「それぞれ2つ以上」の不正なフォーマットのデータが生成されることが概ね保証されます。
また、今回はdefault値を使っていますが、多くのLLMのAPIには応答のバラツキ度合いを指定できるオプション(GPTならtemperature)があり、このオプションの指定によりデータのバラエティを広く取ることが出来るかもしれません。
この記事が気に入ったらサポートをしてみませんか?