【keras 最初の1歩】Titanic dataset でkerasに慣れる。

ニューラルネットワーク系の動画を見まくったおかげで少しは理解が進んでいる気がするので、次は手を動かしながら理解を深めたい。使うライブラリはkerasで。データセットは懐かしのTitanicにした。適しているかはわかんなけど、馴染みがあるデータでやることで、関係ないつまずきを回避できればと思います。
ちなみに、初めて機械学習&Kaggleデビューしたときのスコアは、こちら。評価指標は、Accuracy。モデルはLightGBM。半年前か。

とりあえず作ってみる
さて、本来であれば、まずはデータの前処理をするのだと思う。けど、なんのために前処理するのかがわかってないと、チュートリアルをなぞるだけになってしまう(というかLightGBMのときにそうなった)。前処理って言ってもいろいろあるし。なので、あえて、さっそくNNモデルを作ってみる。学習するときにエラーがでるであろう。逆にそれでよい、と思ってます。
インポート系

使うパーツをそろえているって感じです。
3行目:Sequential(前から後ろへ 順番に処理していく)モデルを使います。
4行目:レイヤー(層)は、Activation(活性化関数)とDense(全結合層)を使います。(Activation層が作られるわけでないと思う。Denseの中に活性化関数が含まれるはず。)
5行目:optimizer(最適化アルゴリズム)※のちほどエラーあり。
6行目:評価指標 (binaryとなってるけど、のちほどcategoricalに変更)
モデルを作る


unit(ノード)数が16の全結合層が2層ある。活性化関数はrelu。
出力層は2unitで、softmax。出力層もDenseで表記するんですね。

学習するパラメーターは338個。上から見ていく。
最初の隠れ層denseのパラメータは32個。これは、なんなんだ??おそらく入力ノード数*受け取る側ノード数+バイアス数で32個なんだと思う。公式を見てみると、input_shapeは、(batch_size, input_dim).試しにinput_shapeを変えてみたら、パラメータも変わった。10x16+16ですね。納得。

dense_1は16x16の256+バイアス16個で272個なんじゃないかな。
dense_2、16x2+バイアス2個、かな。dense_2を図で表すと、

コンパイルする

コンパイル時にエラー発生。optimizerがインポートできなかった。どうやらoptimizerのファイル場所が変わったようで、keras.optimizerではインポートできず。以下でインポートできた。

っていうか、インポートせずにcompileするときの引数に(optimizer="adam")ってするだけで使えるようだ。
でもハイパーパラメータいじるなら、
optimizer=Adam(learning_rate=0.01)
みたいに書かないと無理。
loss関数も不安なので、再確認。今回は2値分類なので、選択肢は3つある。
1,binary_crossentropy
2,categorical_crossentropy
3,sparse_categorical_crossentropy
公式を見ると、1はloglossのようだ。つまり出力が1次元用。なので今回は使わない。
2,3の違いは、2はonehot用、3は整数用とのことだ。
んん、今回は、、、どっちでもいいのか???0と1しかないから変わらないよね???余裕があればどっちも試してみよう。いったん2、で。
※のちほどエラー。正解はsparseのやつでした。
metricは、公式にはないんだけど、['accuracy']とした。titanicの評価指標だし。なんでこんな書き方なんだろ。


さて、もう学習できるモデルができた。けど学習データが整っていない。
学習データを整える
どのような学習データをfitに渡せばよいかは、tensorflowの公式を見てみる。
Input data. It could be:
A Numpy array (or array-like), or a list of arrays (in case the model has multiple inputs).
A TensorFlow tensor, or a list of tensors (in case the model has multiple inputs).
Numpyのarrayを渡すようだ。
また、
特徴量は数値のみで、欠損値は無理。
特徴量の大きさがそろっていないとうまくいかないことがある。
なるほど。これはKaggle勝つ本で確認した。
ということでやってみる。
前処理はこんな感じ
1,欠損値をなんとかする。
2,カテゴリー変数を数値化する。
3,特徴量の大きさをそろえる。
4,Numpy arrayにしてfitに渡す。
という流れ。
今回の記事のメイン内容ではないので、簡単に。
1,Fareの欠損は、Pclassでグループした後の平均値で補完した。
Ageの欠損は名前敬称から平均をとり補完。
2,Nameは除外。
Ticketは除外。
cabinは欠損も多いので除外。
Sexは、labelencoding。
Embarkedは、labelencoding。
Pclassはそのままとした。
Age欠損補完の時にできた、敬称を特徴量とし、labelencodingした。

3,特徴量の大きさ
スケーリングを行うわけだが、現状はこう。

Fareだけ異様にデカくて、あとは100以下。
スケーリングって名前がややこしい(ってか統計って基本的に名称がややこしい)ので軽く整理すると、
まず、
データを変形して使いやすくすること → 正規化という。
正規化の手法の中で、
平均を0、標準偏差を1にする手法 → 標準化という
最小を0、最大を1にする →正規化という←これややこしすぎ。英語ではminmaxscalerというので、以後minmaxscalerということにする。
今回は標準化をする。英語では、StandardScaler。ライブラリは頼れるscikitlearn。


4,arrayに変換。
df.to_numpy()で終了。

ニューラルネットワークを学習させる
ようやくfit。さっそくエラー。インプットのshapeがダメっぽい。

input_shapeをinput_dimに変更。そして、特徴量の列数である8とした。
それでもエラーだったのでググったら、loss関数がsparseのほうのcategoricalcrossentrpyが正解だった。なぜ。

スコアは、0.8485。

ニューラルネットワークをいじってみる
とりあえずエポック数ふやしてみるか。100。
98回目で下がりきった?あと、上昇している。これって可視化できないの?あとearlystoppingは?ってかvalidationは?

validationについて。
fitのなかに、validation_split=0.15ってやるだけだった。簡単、ってか前回やったのに忘れてたー。学習データの最後の15%を検証用に使うってことのようだ。
earlystoppingについて。
これはあった。moniterが、どの指標を計測するか。patienceは、moniterが何回改善しないことを耐えるか。fitの引数にcallbacksを与える。

可視化も比較的簡単かも。
一旦earlysoppingをなしにして、model.fitをhistoryに入れる。
history.historyでlossとかaccuracyが取れる。これをグラフにする。

いろいろわかってきたところで、モデルをいじっていこうかな。
まずは、学習率。今まで0.001とかなり低い数字にしてしまっていたので
、0.01にしてみる。結果、Epoch20あたりでvalidation_lossが学習データのlossより悪くなっている。これが過学習ってやつですね!おおー。

次は、層を深くしてみる。とりあえず二倍。


あのトゲは、なんなんだ。大してスコアがよくなっていない。
二層に戻して、ユニット数を倍にしてみる。

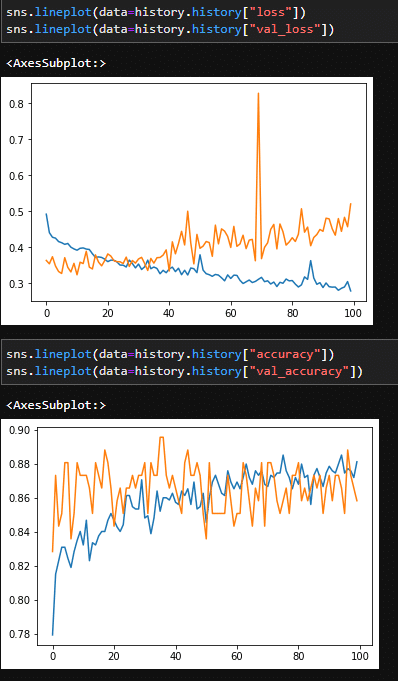
ふたたびトゲ。
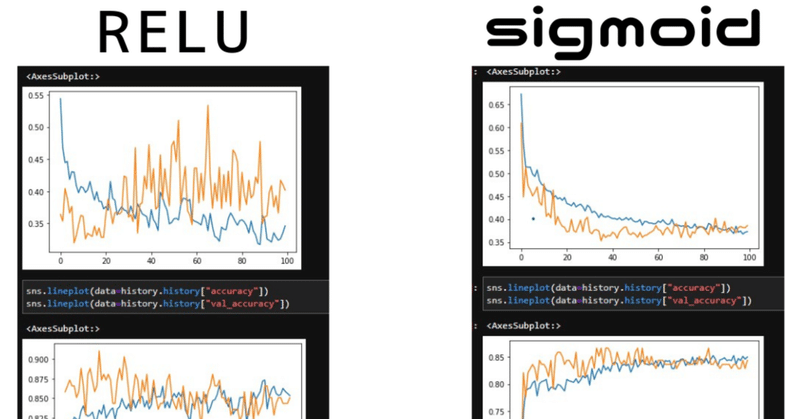
活性化関数を変えてみる。sigmoidのほうがなだらか、reluのほうが若干スコア高い。

やばい、次どうしたらいいのかわかんない。
一回予測してみてKaggleに投稿するとしよう。
予測する

np.argmaxはnumpyの関数で、「配列の中で一番大きな数字を持つインデックス番号」を返す。axisを-1にすることでカラム番号が返ってくる。これを利用し、2値分類に使っている。へーおもしろ。
予測はできたんだけど、学習ってもうほんとに済んでるんだっけ。パラメーターってlossが一番ちいさいところで最適化済みという理解でいいのかな?これは次回へ持ち越しにする。
さて、得点は、

0.76。大してよくなってないんだけどもw
kerasに少し慣れることができました。
持ち越しテーマは、
レイヤーの重ね方やノードの数をどうやって決めるか。
学習済みモデルの重みはどうなってるのか。
今回は以上。
この記事が気に入ったらサポートをしてみませんか?