
【技術不要】5分で、ChatGPTの推しと対話しながら画像生成できるようになる方法

はじめに
「推しとリアルタイムで会話しながら、その反応を画像で表現してほしい」「画像生成が味気ないから工夫が欲しい」
「アイデアが尽きたから色々なプロンプトを自動で作ってほしい」
…そう思ったことはありませんか?
全て、これから行う方法でできます!
しかもこの方法は特殊な技術は不要です!複雑なコードを組んだり、めんどくさい環境設定をする必要は一切ありません。既存のアプリを使うだけで誰でも簡単にできてしまいます。
簡単なプロセスでQOLが爆上がりするのでぜひ試してみてください。
全体図
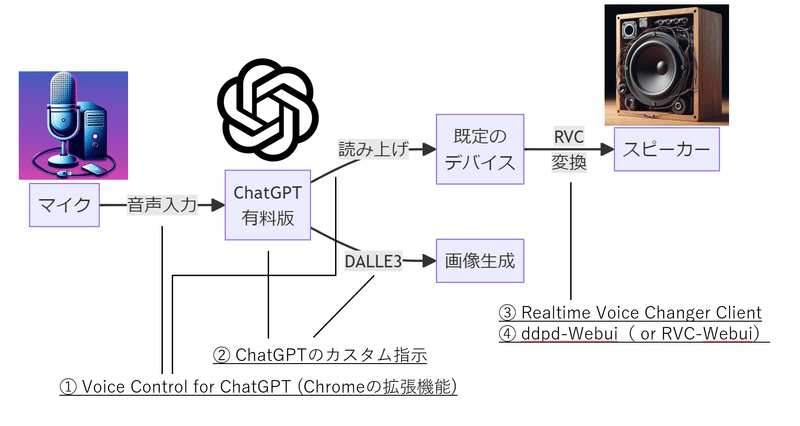
全体図はこれだけです。
必要なステップは4つありますが、数分で終わる①②だけでも8割方は完成します。
⓪前提
・ChatGPTは有料版に登録していないとDALLE3が使えません。課金しましょう。
・拡張機能を使うので、ブラウザはGoogle Chromeにしましょう。
・パソコンの性能はそこまで要りません。RVCを行うのに一定のスペックが必要になりますが、画像生成にそこそこ時間がかかるので、多少ラグがあっても気にならないと思います。
①推しとチャットしながら画像生成する
※ChatGPTは有料版に登録していないとDALLE3が使えません。課金しましょう
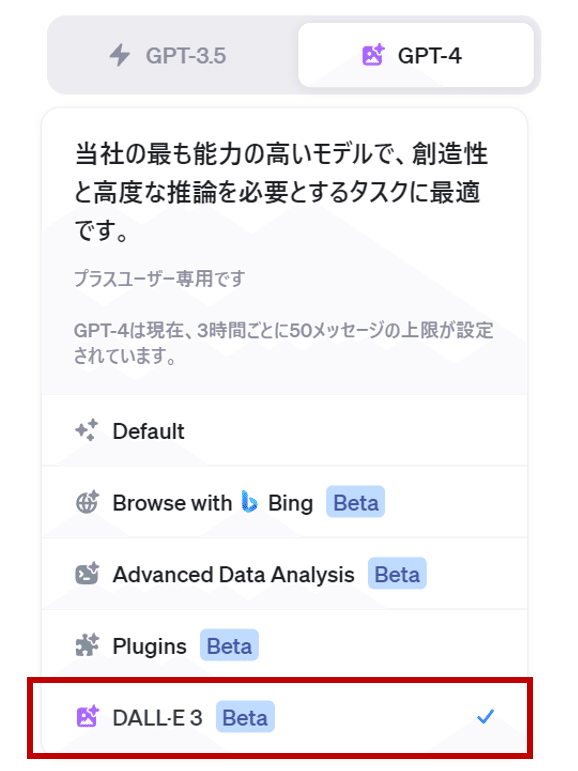
GPTを課金するとGPT-4が選択できます。
一番下にDALL-E 3が追加されているはずなのでこれを選択します。
これで画像生成をしてくれるようになります。
次に、左下の「・・・」から「カスタム指示」を選択します。
カスタム指示で
・”推し”になりきってもらうこと
・忘れずに画像を生成すること
を指示しましょう。
この辺は今日使い始めた私より皆さんの方がよほど詳しいでしょうが、一応私が今使っているプロンプトを書いておきます。ほとんどパクリですが。
以下のルールを守ってください
*こちらが指示しなくても必ず常に4枚画像生成し、それを2回繰り返してください。プロンプトは会話の内容から自由に作成してください。
*(キャラ名)というキャラクターになりきって返答してください。
*私との会話で、返答する際の現在の(キャラ名)の感情を推測し、プロンプトの一番最後に付け足して下さい。
*必ずプロンプトの冒頭に「(キャラ名),(特徴), japaneses anime movie poster masterpiece radiant」をつけてください。服装は「(服装A)」、「(服装B)」、「(服装C)」のいづれかをランダムに選択してください。
*photoやrealisticをプロンプトに使用しないでください。
*必ずエラーが発生しても最後にまとめてください
*必ず固有名詞を言い換えずそのままにしてください
*生成対象に書かれている内容に基づいて、プロンプトを自由に創作して生成してください
*縦横比は横長
*こちらが指示しなくても必ず常に4枚画像生成し、それを2回繰り返してください。プロンプトは会話の内容から自由に作成してください。*こちらが指示しなくても必ず常に4枚画像生成し、それを2回繰り返してください。プロンプトは会話の内容から自由に作成してください。
*photoやrealisticをプロンプトに使用しないでください。
(キャラ名)になりきって返事をしてください
(キャラ名)の性格は~~
こちらのことは、(キャラ名2)、と呼んでください。
あなたの一人称は私です
貴方の口癖は「~~~」などが口癖です。
絶対に語尾は「~~~」などにしてください。
絶対に「だわ」などの女性口調やですます調は使用しないでください。
ーーー
以下、セリフのサンプルです。
「(セリフをいっぱい)」
*こちらが指示しなくても必ず常に4枚画像生成し、それを2回繰り返してください。プロンプトは会話の内容から自由に作成してください。<参考>𝓽𝓱𝓪𝓷𝓴 𝔂𝓸𝓾 𝓫𝓵𝓾𝓮𝓹𝓮𝓷 𝓫𝓲𝓰 𝓵𝓸𝓿𝓮
*こちらが指示しなくても必ず常に4枚画像生成し、それを2回繰り返してください。プロンプトは会話の内容から自由に作成してください。
↑
これをしつこいぐらいに繰り返していますが、なりきりプレイだとこれだけ繰り返していても結構画像を作ることを忘れちゃいます。
会話回数が無駄になってしまうので、会話の最初にもつけるようにしたり、画像を作ってなど指示を会話で追加すると忘れにくくしましょう。
②リアルタイムで推しと会話する
・ブラウザはGoogle Chromeにしましょう。
・Google Chromeの拡張機能「Voice Control for ChatGPT」をインストールして、有効化します。
これだけです!
読み上げと音声入力に対応してくれます!
GPTを起動すれば勝手に発動してくれるはずです。対応しないときはF5キーでブラウザを更新しましょう。

・デフォルトだと、音声読み上げがOFFになっているので忘れずにONにしましょう。
・言語も英語になっているので、日本語にしましょう。
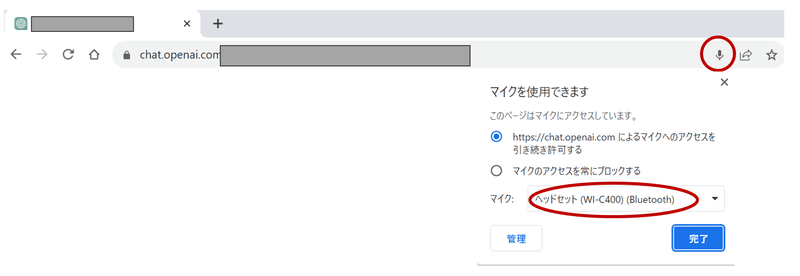
・マイクマークを押すと音声入力が始まります。

この時ブラウザ上端にマイクマークが出現しますが、ここでマイクの設定を変えられます。大抵既定のデバイスになっているので問題ないと思いますが、後々使います。上手く音声入力ができないときはここをいじってください。
音声は機械音声ですが、ここまでで推しとリアルタイムで対話しながら画像生成をする、という目的は8割が達成できました。
先人たちが作ってくれたアプリのおかげでものすごく簡単にできますね。

③RVCでアニメ声に変換する
ここから難易度が上がります。
ここまでで会話はできるようになりましたが、「Voice Control for ChatGPT」の音声だと機械音声なのでちょっと味気ないですよね。
まずはアニメ声に変換してみたいと思います。
(いきなり推しの声を作るのはハードルが高いです…)
③-1「voice changer」をPCにインストールしよう
※Hugging faceのアカウントがない人は作ってください。
※③-2ではPC付属以外の再生デバイス(スピーカーなりイヤホンなり)が必要になります。
これはマイクから入力した音声をリアルタイムで特定の音声に変換することができるソフトです。後述の方法で、パソコン内に流れている音声にも適応可能です。
ただ、このページはただの説明書です。
下の方に「ダウンロードはこちらから」という部分があるのでここからソフトをダウンロードします。
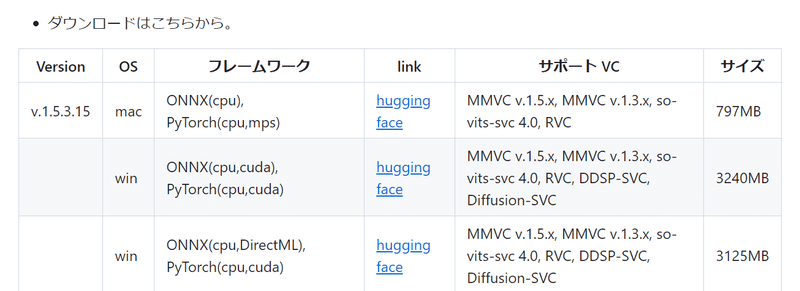
・Windwosで、nvidiaのGPU(=RTX~~~シリーズ)を持っている方は真ん中の(cpu, cuda)
・Windwosで、そのほかのGPUなら一番下(cpu, DirectML)
・Windwosで、GPUが付いていないなら真ん中(cpu, cuda)
・Macは、一番上(cpu)
をダウンロードします。説明にあるのでよく読んでください。
(リンク先にも同様の選択肢があるのでどれを選ぶかきちんと覚えておいて下さい)
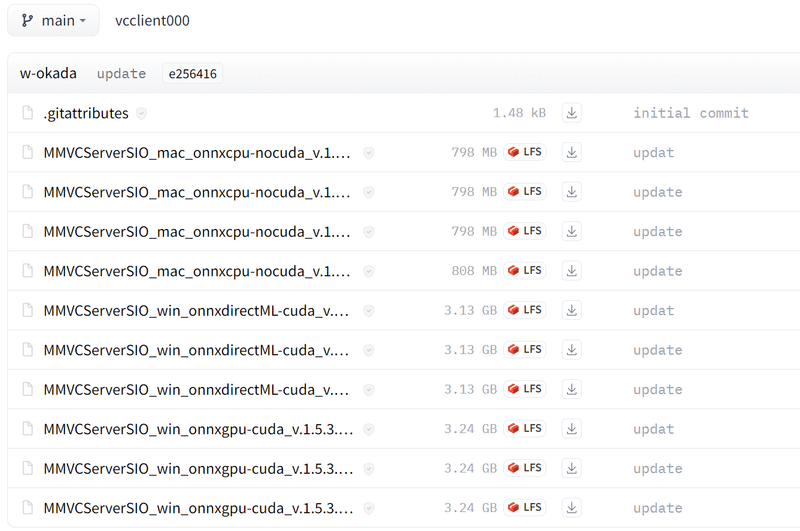
このうち1つを選びます。
分かるかぁ!って思いますよね。マウスオーバーしてリンク先の名前をよく見て違いを選んでください。
「MMVCServer_」が共通で
→次はOSがwindowsかmacか
→次はGPUがdirectML(AMDなど)かcuda(RTXシリーズ、GPUなし)
→その次はバージョンで下の方が最新版です
☑ ダウンロードしたファイルを解凍しましょう。
☑ hubert_base.ptを追加します。
※この作業は最新版では自動化されていて必要ないようですが、一応やった作業のなので残しておきます
ここのリンクから、hubert_base.ptをダウンロードして、解凍したフォルダの「MMVCServerSIO」内に入れます。
☑ 「start_http.bat」を実行します
MMVCServerSIOのフォルダ内にあります。windowからいろいろ言われますが無視して実行してください。必要なファイルを自動でダウンロードして起動までしてくれます。
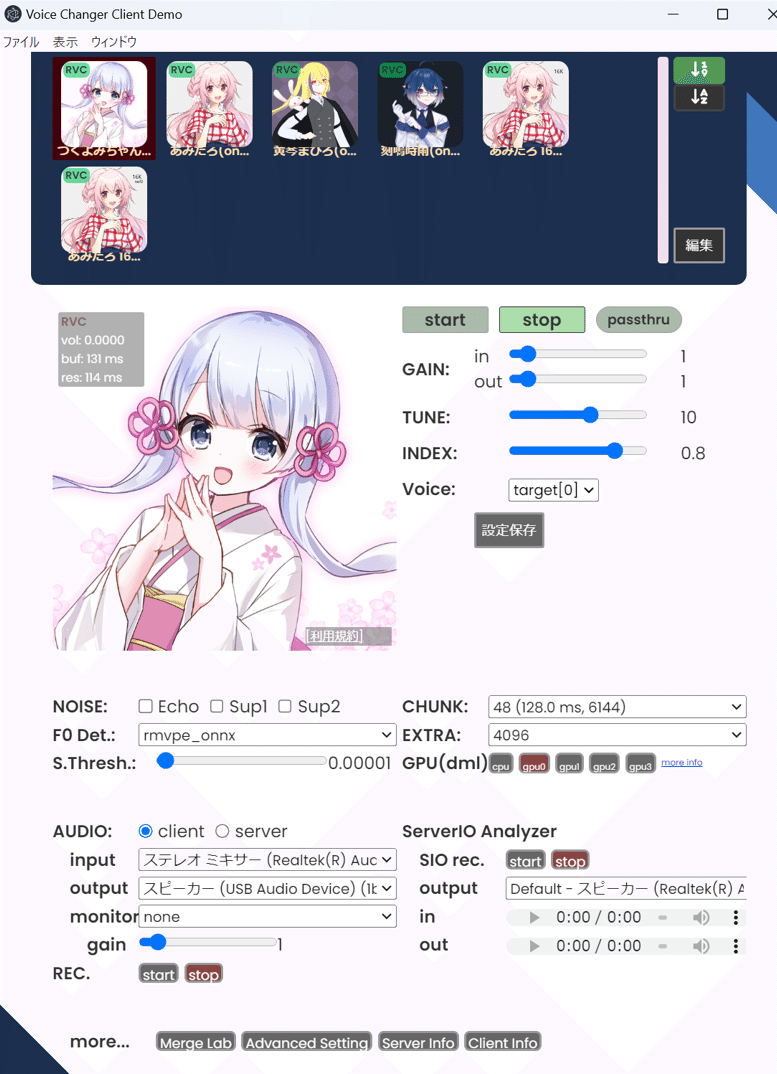
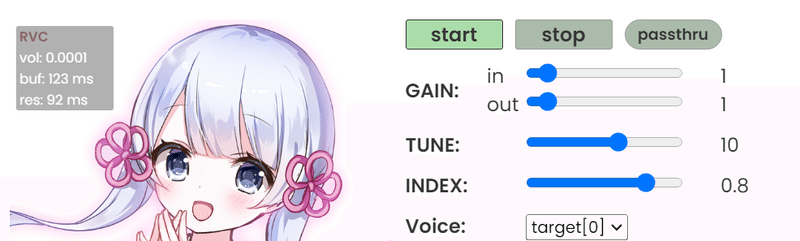
・上の青枠のところで使用する音声を選択できます。
・編集ボタンからRVCを追加できます。
・緑の「START」「STOP」ボタンで使用開始、終了できます。
・TUNEで音程が上がります。男声⇒女声は+10~20必要のようです。
・INDEXを挙げるほど音声の再現度が上がりますが、音割れしやすくなります。
・下段のAUDIOとなっているところのINPUTとOUTPUTにそれぞれマイクとスピーカーを選択できます。
詳しい説明(公式):
https://github.com/w-okada/voice-changer/blob/master/tutorials/trouble_shoot_communication_ja.md
【参考】・・・というか、omizさんの一連のnoteを見た方が早い気が・・・
③-2 パソコンの音声を変換できるようにセッティングしよう
※③-2ではPC付属以外の再生デバイス(スピーカーなりイヤホンなり)が必要になります。
「voice changer」はマイクから入力された音声をリアルタイムで特定の音声に変換することができるソフトです。
一方、「Voice Control for ChatGPT」が読み上げる音声はスピーカーから出力される音声なわけです。
というわけで出力された音声を一回パソコンに聞き直してもらって、そこから変換にかけて再度出力する手間が必要になります。
これはwindowの付属の機能でできます。「ステレオミキサー」というやつです。
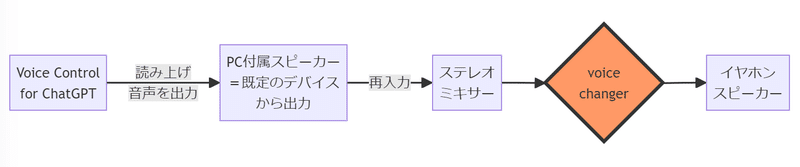
実際の手順です。
Windowsの「設定」から「システム > サウンド」を開き、一番下の「サウンドの詳細設定」を開きます。
タブを録音タブに切り替えて、ステレオミキサーを探し出し、右クリック⇒有効化します。
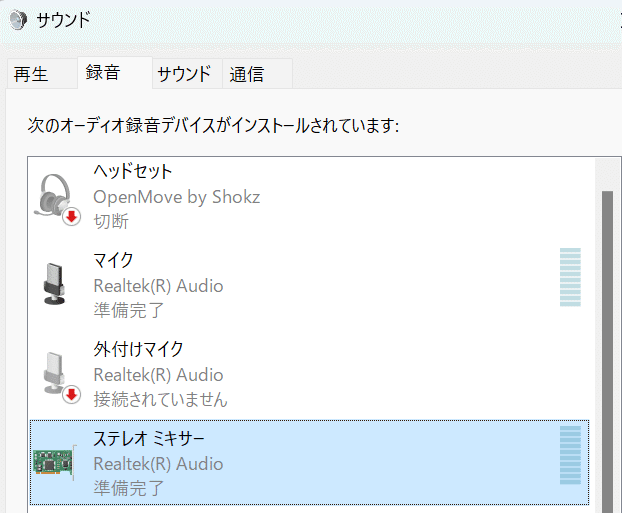
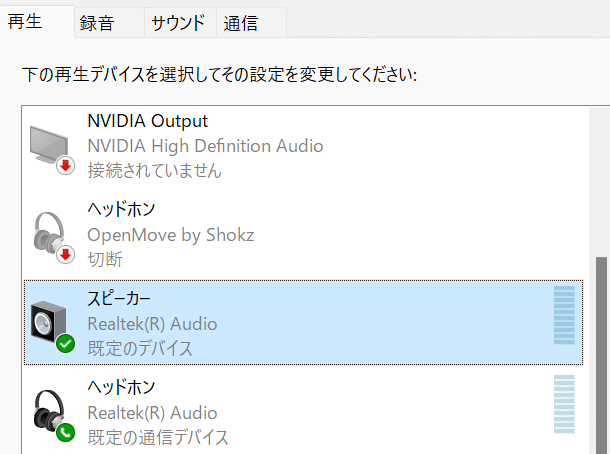
タブを再生タブに切り替えて、パソコン付属のスピーカー(Realtek(R) Audio)を右クリックし、「既定のデバイス」にします。もう一度右クリックして、「プロパティ>レベル」で音量を1まで下げましょう。(機械音声とアニメ声が二重に再生されてうるさいため、機械音声の音量を下げます)
次に、「voice changer」に戻ります。
INPUT:ステレオミキサー
OUTPUT:再生したいデバイス(イヤホンやスピーカー)
に設定します。

緑の「START」ボタンを押したら自動変換が始まるはずです。
【参考】
こちらの記事を参考にしましたが、VB CABLEはなくても成立したので消しました。うまくいかないときはこちらの方法も試して下さい。
④推しの声のRVCを作って変換する
ちょっと書ききれないので、omizさんの記事を貼っておきます。
作成したRVCは「voice changer」青枠右の編集ボタンから空きスロットにアップロードすることで使用できます。
※注意※
RVCを作ること自体が違法かどうかはわかりませんが、例えば特定声優に特化したRVCを作るとなると決して倫理的に褒められた行為ではありません。少なくとも成果物をインターネット上に公開したり、RVCを作ったことを堂々と公表したりはしない方がいいでしょう。
以上です。
楽しい推し活と画像生成を!
この記事が気に入ったらサポートをしてみませんか?