Googleを欺いたOpenAIの戦略

※※※※※※※※※※※※※※※※※※※※
※初めに言っておきますがすべて妄想です※
※※※※※※※※※※※※※※※※※※※※
2024年3月14日 chatGPT4の発表で世界が湧いたのを覚えているだろうか。
あの時、誰もが口をそろえていたのが
・chatGPT4は100兆のパラメーターを持つ
という事だ。(のちにでたらめであると否定された)
そして、大規模データを学習することがAIにおいて重要だという風潮が生まれた。
大規模データを学習すれば全知全能のAIが生まれるという幻想である。
その熱に浮かされるように大手の企業は次々にAI制作に乗り出した。
Googleは2023年5月10日にGenimiの開発を宣言した。ネット上のあらゆるデータを学習するまさにビックテックならでは超大規模AIだ。しかし、2023年12月6日 Gemini 1.0を発表するも結果はさんざんである。2024年2月6日に発表したGemini1.5で1年かけてようやくGPT4に追いついたとされているが、大企業Googleの成果としては期待外れと言えるだろう。
2023年11月3日にはイーロンマスクがX(旧twitter)上のデータを利用したGrokの開発を宣言するも、オープンソースにすることを宣言しておりこちらも期待した性能は発揮できなかったのだろう。3月18日に公開されたが、家庭用PCではまず動かない容量であるのに性能は低くとても使い物にならない。
2023年7月にはAppleも自社製のLLM(appleGPT)の開発がささやかれたが、2024年3月18日には自社テストでAppleGPTは期待した性能にならずGoogle・OpenAIとの協力を協議しているとの記事が出た。
とまぁ結果を見ればどこも散々である。
他にGPT4に匹敵するとされたAnthropicのclaude3があるが、こちらは元OpenAIのメンバーであり、やり方を熟知していた結果と言える。
そもそも、大規模データを学習すれば全知全能のAIが生まれるのだろうか?
冷静に考えるとこんなはずはない。
推論器はあくまで推論器にすぎない。誤ったデータをいくら学習しても仕方ないのだ。
「1+1=3」という類のデータを100TB学習したAIに計算をさせたところで決して正しい答えを返してはくれないだろう。
学習データと量と質を両立しなければ人々が求めるAIはできないはずなのだ。いやむしろ『正しい返答』を返すように偏らせる必要すらあるだろう。
これは画像生成AIを使っていると良くわかる。
microsoftが開発したDALLEは非常にプロンプトの効きが良く、かなり広い画風を作ることができ、文章を正確に絵に反映することができる。しかし、人気なのはmidjourneyなどのいわゆる神絵を簡単に出力してくれるAIだ。
当たり前だがあらゆる画風を作ることができるという事は『外れの』画風を高い確率で作ってしまうということでもある。そんなAIはほとんどの人にとって役に立たないのだ。
その観点で考えるとネットなんてデマだらけのデータを無作為に全部学習したら使えないAIがでてくるのは必然だろう、さらにはX(twitter)なんてもっとひどい。何の意味もない呟きやデマであふれかえっているのだから。
しかし、いったい私たちはいつからデータ量至上主義なんて幻想にとらわれてしまったのだろうか。
翻って考えるとOpenAIの戦術だったのではないだろうか?
つまり、あらかじめパラメータ数に関するデマを流し、あたかも『学習データの量が多ければ多いほどすごいAIが生まれますよ!』と喧伝したことで、学習データの質や学習手法に関する秘密を守ったのではないだろうか。
…といったところで何の根拠もないのであるが。
しかし大企業Googleも黙ってはいない。
OpenAIが秘伝のたれを公開しないなら盗めばいいのである。
というわけでLLMの隠れ部分をStealするという論文までだしてしまった。
おおよそ大企業がすることとは思えない野蛮な戦術だが、それだけ追い詰められているという事だろうか。
とはいえ、対するOpenAIも動画生成モデルSoraで注目を集めたものの肝心のGPT4の方は去年の2月からモデル自体の大規模アップデートは行われていない。(4Vでマルチモーダルにはなったり、マイナーアップデートはされているようだが、むしろ性能劣化の噂の方が多い)
これらのことを考えるとAIの進化は思っていたよりも簡単にはいかないのかもしれない。
昨年末から今年にかけて大手企業が次々と生成AIの開発を宣言した。
しかし、GoogleやOpenAIができていないこと(GPT4を大きく超えた新たなAI)を今から手掛けてできるのか、あまり期待はしないで見守っていきたい。
softbankは2023年3月に、LLM開発を担う「SB Intuitions」を設立
2023年10月31日に国内最大級となる3500億パラメーター(350B、GPT3.5ノ2倍)のLLMを開発すると発表している。今更GPT3.5と競っても仕方ないのだが。
https://toyokeizai.net/articles/-/729458
https://www.nikkei.com/article/DGXZQOUC31AWI0R31C23A0000000/
2024年3月18日にMicrosoft(要はOpenAI系)とコールセンター業務を効率化するAIを共同開発すると発表。上のLLMとは別だろうか?
https://www.softbank.jp/corp/news/press/sbkk/2024/20240318_01/
2023年7月にはAppleもAppleGPTを開発中との記事があった。
https://www.bloomberg.co.jp/news/articles/2023-07-19/RY1WO7T0G1KW01
⇒しかし、どうも新たに作るのは諦めてGeminiとOpenAIのどちらかと組むようだ。
https://www.livemint.com/technology/tech-news/googles-gemini-could-power-generative-ai-features-on-iphone-16-tim-cook-heres-what-we-know-11710739843784.html
⇒MM1を作っていたようだが、下の記事はかなり誇大広告気味。どうも大した性能ではなさそうだ。画像認識はとがっているが、他の性能はかなり劣っている。上の記事ではAjax (AppleGPT)というAIモデルも作って社内テストしていたとあるが、それもGoogleやOpenAIを超えられず、技術協力という形になっているので、Appleも沈んだという事だろう。で、もったいないので論文で公開。どこもやることは同じだ。どうもAppleは秘密主義らしく、論文公開するは異例のことらしい。
https://ascii.jp/elem/000/004/189/4189761/
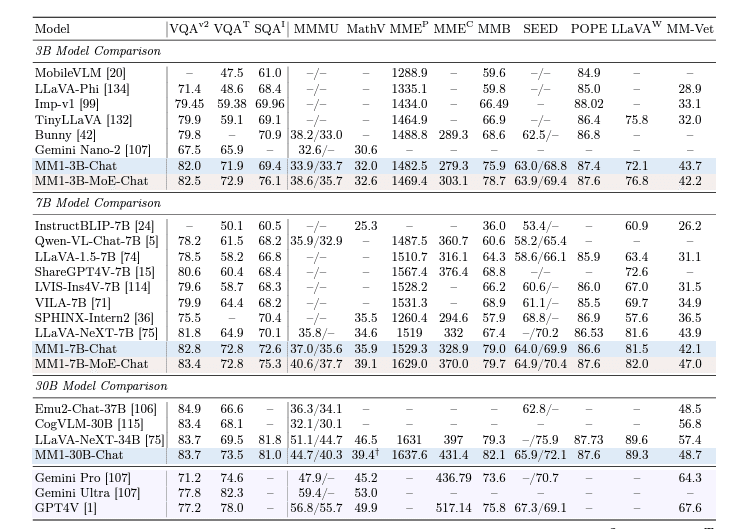
Emu2は中国、LLaVaやCogVLMはOSSらしい。OSSがそこそこ結構頑張っている。
7BではOpenchat-3.5-1210というLLあまのがGPT3.5を超えるとして話題になっていた。
auはelyza(東大松尾研究所の日本語LLM)と手を組んだようだ。
https://prtimes.jp/main/html/rd/p/000000043.000047565.html
elyza自体は13BでGPT3.5と競っているので(頑張ってはいるが)はっきり言ってそこまでの性能ではない。GPT3.5と比肩するLLMは今現在吐いて捨てるほどある。代表格はOpenchat-3.5-1210であり、7Bという軽量でGPT3.5を初めて超えたとされ、これがOSSなのでこれ以降のAIはすべてこれが基準になる。fusechatなどOpenchatを組み合わせた新たなOSSもできてきており、かなり高性能なようだ。
楽天はRakuten 7Bという日本語特化のOSSモデルを3月21日に出していた。性能はElyza同様大したことなさそう。LLama2(meta)をfinetuneしたElyzaに対して、こちらはMistral 7B(仏mistral社)をfinetuneしたらしい。日本語特化をうたうモデルはそういう小賢しいモデルばかりだ…。
https://corp.rakuten.co.jp/news/press/2024/0321_01.html
いわゆる日本語LLMを鋭く切り裂いたこのnoteは必見の価値があるので是非見てほしい。日本語特化のLLMが幻想であることが良くわかる
・日本語LLMの大半は選択式問題を解けない
— 畠山 歓 Kan Hatakeyama (@kanhatakeyama) April 2, 2024
・解答能力とモデルサイズは相関しない
・おそらく、事前対策をしたモデルのみ解答できる
等の事項を書いています(追記中)
ーーー
(10b程度の)大規模言語モデルが「種々のスキル」を身につけるために必要な要素や学習量を考えるメモhttps://t.co/vywrjnprr0 pic.twitter.com/5Hp2wQbarg
metaはNVIDIA H100を65万基分使ってすごいAIを作るつもりらしい。
これも大量データ至上主義の極致だろう。
どうせろくなものは生まれない…というか、そんなもん作ったところでろくに動かないのでは…?という気がしないでもない。
2024年2月9日の記事なので成果はこれからだろう。
https://xtech.nikkei.com/atcl/nxt/column/18/00692/020800125/
・・・とおもったが、考えてみたらmetaは2023年7月18日 Llama2を出しているので期待してもいいのかもしれない。Llama2は今となってはさほどの性能ではないが多くのOSSモデルの基盤になっている。
microsoftはOpenAIと手を組んでいる。
amazonはclaude3にベットしたようだ。これは期待
・・・あとどこがあるっけ?
Chatbot Arenaというサイトがあり、ランダム化比較試験でAIモデルの比較ができる。LLMの性能はどこも誇大広告をするのでこういう比較サイトの情報が一番ありがたい。
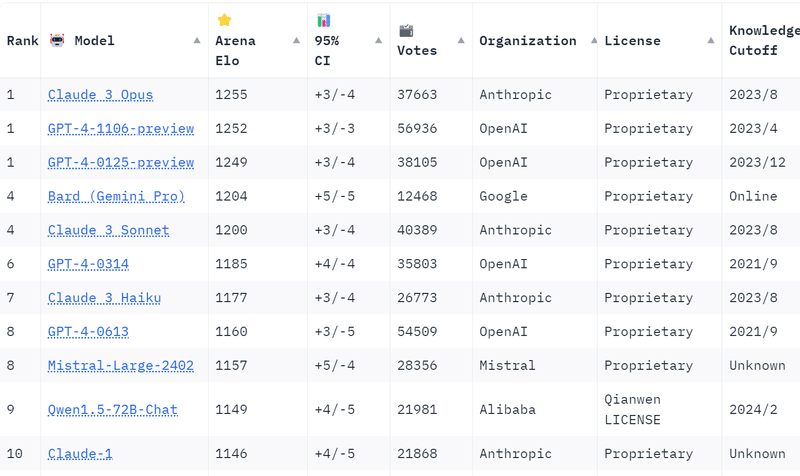
性能はやはり、Claude 3 Opus、GPT-4、Gemini Proが圧倒的だ。
それにはやや及ばないが、Mistral large(フランスMistral社の有料モデル)うやQwen1.5 72B(中国のAlibaba Cloud GroupがだしたOSS=無料モデル)がいい位置につけている。Command Rはトロント発のスタートアップCohereのモデル、CC-BY-NC 4.0という非商用利用可能なライセンス)
Qwen 1.5を日本語でfinetuneしたモデルが「ao-Karasu」(東大発スタートアップのLightblue社)
https://prtimes.jp/main/html/rd/p/000000057.000038247.html日本人は人の褌で相撲をry
結果からみるともうLLM王者は、OpenAI(あるいは元OpenAIのAnthropic)とGoogleの一騎打ちというところだろうか。
検索エンジンで生きてきたGoogleは企業の母体がつぶれかねないので必死だ。
まだ手の内を見せていないのが、metaとsoftbank。
metaはここでこけたら再起できるのか?って意味では必死かもしれない。
他の企業はまぁワンチャン作れたらいいけど大変ならどっかのを載せればいいかな~ぐらいのノリな気がする。正直低容量開発ではOSSが強すぎてほぼほぼ無駄になるが、高容量ではこの2社がしのぎを削りまくっているので、リターンはでかいもののかなり分の悪い博打になっており、リスクをかけて参入する価値はほとんどないような状態になってきている。
高容量に求められているのはGPT4を超える性能だが、どうも適当に学習させただけでこれを超えるのは難しそうだ。かといってそんな大きなデータの質を保つというのは人力ではほぼ不可能だろう。どのデータに偏って学習させ、データをどこから持ってくるのか、というデータの質をめぐる部分が今後の企業争いの争点になってきそうだ。
また運用面の問題もある。高容量になりすぎるとGPUを大量に必要とするため運用コストもとんでもないことになる。覇権を狙うならいかに運用コストを減らすかも考えていかなければならない。
いずれのノウハウも間違いなく、現時点ではOpenAIとGoogleに集中しているので、ここからどうやって情報をかすめ取るか、あるいは諦めて勝ち馬にのるか、の勝負になってきそうだ。
~自分用メモ~
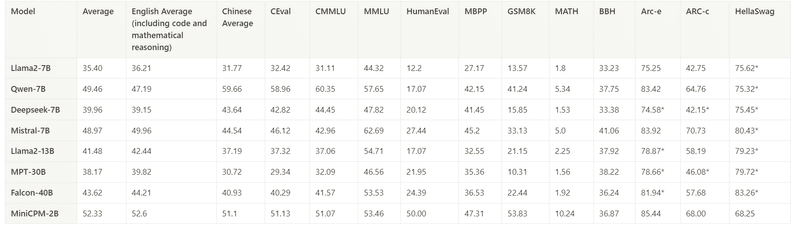
比較表
この記事が気に入ったらサポートをしてみませんか?