
文系非エンジニアがChatGPT / LLMを数式なしで解説してみる

先日、社内でChatGPT / LLMを活用した実証実験をしていたら、一部感動するほど結果が出たことで、今更ながら俄然興味を持ってしまいました。
これからビジネスユースケースを考えていくうえで、「本質的にどういうものなのか」を理解しておくことがとても大切だと思い、改めてChatGPT / LLMの基本的な仕組みを整理してみました。
私みたいな文系で行列や統計はわからないけど、もう少し根本的なところを理解しておきたい!という方に是非です。
それでは、GPTをはじめとするLLM(大規模言語モデル)がどのような背景から生まれてきたのかを振り返りながら、LLMの特徴を理解していきましょう!(最後に参照したおススメの動画・記事を貼っていますので、それだけでも是非ご覧ください。)
1. ベースは、ディープラーニングを用いた自然言語処理モデル
2015年頃、日本でも"AI"がバズワードになり、ディープラーニングを活用した自然言語処理の研究が注目されていたかと思います。当時、「ディープラーニングにより単語をベクトル化できる」(word2vec)ことが話題になっていたのを覚えていないでしょうか?
こうした言語モデルの基本は、「過去の単語列から次の単語を予測する」といったタスクをディープラーニングで学習し、学習の過程で出てくる中間層の重みを単語ベクトルとして使うというものです。
「予測する」といっていますが、もう少し正確には「あらゆる単語ひとつずつが次の単語に該当する確率」を求めています。
GPTシリーズについても、この頃の研究がある種進化したものであり、やっていることはあくまでも「次の単語を予測すること」であることを認識しておくのが大切だと思います。
2. ブレイクスルーは"Transformer"
GPTについて調べてみると、"GPT"の"T"にあたる「Transformer」がすごい!という話をたびたび目にするかと思います。そこで次は、この「Transformer」とそのベースとなった「Attention」がなにかを簡単に見ていこうと思います。数式見てもわからないので、まずは時代背景から理解していきましょう!
「Attention」が登場した背景
上記の「word2vec」等々、深層学習を活用することで自然言語処理の研究は一気に進みましたが、これを機械翻訳(自動で日本語から英語に翻訳するとか)で活用しようとすると大きな課題がありました。
それは、word2vecはあくまでも1単語に対するベクトルを獲得しているのみであり、「文脈」を捉えたり「単語の並びを意識する」ということができないため、長めの文章を翻訳しようとすると、如実に精度が落ちるという課題です。
この課題を解決するために様々な解決策が模索されました。「GRU」や「LSTM」等が有名ですが、いずれもRNN(再帰性ニューラルネットワーク)モデルを「Encoder / Decoder」と呼ばれるステップで計算していて、簡単に言うと以下のようなプロセスになっています。
(英語からに日本語への翻訳の場合)
・① 入力文(英語の文章)を深層学習を用いて、入力文を意味ベクトルに変換
・② 「a.直前の単語」、「b.それまでの単語列から出てくる意味ベクトル」、そして「c.↑で出てきたた入力文全体の意味ベクトル」の3つを用いて、次の単語(日本語)の確率を算出
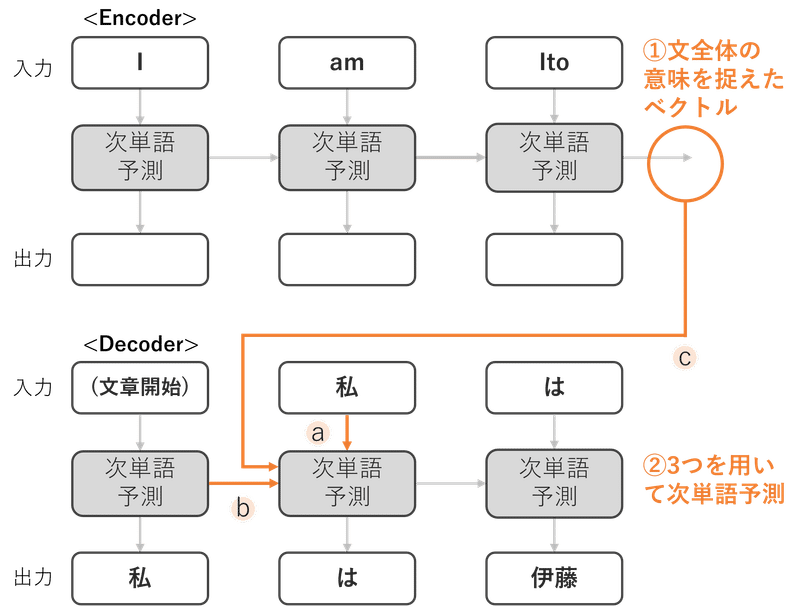
①のプロセスにおいて、次の単語を予測する際に、1つ前までの意味ベクトルの情報をどのくらい引き継ぐか/忘れるかをうまく調整することで、長い文章でもしっかりと文脈を捉えた意味ベクトルが生成できるようになりました。
しかし、いくつかの問題が残りました。いずれの手法も1単語ずつ順番に処理していくので、どう頑張っても遠くにある単語の意味は残りにくいこと、もう一つは文章全体を1つのベクトルで表現していくので(学習した時点で作られるベクトルの次元が固定されるため)、学習した時に用いた文章の単語数を超えるような長文を扱おうとすると、その次元のベクトルに全ての情報が格納しきれずに、複雑な情報を捉えることができないという限界が見えてきました。
長文の意味を的確に捉える「Attention」
長文の機械翻訳で精度がでないという問題を解決したのが、「Attention」という考え方です。「Attention」では、以下のようなプロセスで分析しています。
・① 各単語(英単語)について、文脈を加味した単語ベクトルを生成
・② 「1で計算された各単語ベクトル」と「それまでの英単語列から出てくる意味ベクトル」を用いて、注目すべき重みづけ係数を算出し、その重みづけ係数を用いてて加重平均単語ベクトルを計算
・③ 「a.直前の単語(日本語)」、「b.それまでの日本語単語から出てくる意味ベクトル」、そして「c.2で計算された各単語ベクトルを注目度に応じて重みづけしたもの」の3つを用いて、次の単語(日本語)の確率を算出

①では、入力文に対して1つのベクトルを作るのではなく、それに加えて単語ごとに文脈を加味したベクトルを単語数分をつくることで、文章自体が長くなっても、その複雑な情報は単語ごとのベクトルにしっかり格納されるため、長い文章にも対応できるようにしました。
③では、3つのインプット情報のうち2つはこれまでと同じものになっていますが、残りの1つに「c.文脈を加味した単語ベクトルを注目度に応じて重みづけしたもの」を使用しているのが特徴です。
例えば「彼は日曜日に走ります」を「He runs on Sunday.」と訳そうとしたとしましょう。皆さんが、「彼」を訳そうとする時は、そのまま「彼」だけを注目して「He」と訳しますよね。一方で、「走ります」を訳す場合、「走ります」だけでなく「彼」も注目したうえで、「runs」を選択しますよね。

このように、次の単語を予測する際に、どの単語に注目すべきかを重みづけしたうえで出力してくれるのが、「Attention」の特徴です。
学習の高速化を実現した「Transformer」
「Attention」によって長文でも的確に意味を捉えることができるようになったのですが、またまた課題が出てきてしまいます。それは、長文を分析にするにあたり大規模データを扱おうとすると、従来の「RNN」と「Attention」を用いた手法では、学習の高速化が難しく膨大な時間がかかるという点です。
この課題を解決したのが「Transformer」です。発想をシンプルに書くと、処理に時間がかかる「RNN」をやめちゃって、進化させた「Attention」=「Multi-head Attention」のみを使おうというものです。

「Multi-head Attention」では、
・① 入力文の単語それぞれに対して単純な単語ベクトルを生成
・② その単語ベクトルに何かしらの値をかけて数値変換したものを3セット作る
・③ この3セットをq,k,vとして学習させて、重みづけする比率を計算(この処理を複数回繰り返します)
要は、入力単語を少しずつ変形させたうえで、自分に似た単語ベクトルを探す!というタスクを何度も繰り返しているイメージかと思います。超概念的ですが、これにより同じデータセットで様々な角度から学習できるようになり、重みづけの精度が更に高まりました。
Attentionのみを使うことで学習の高速化が実現したこと、そして「Multi-head」で何度も繰り返すことによってよりよい重みづけ比率を計算できるようになり、精度が爆発的に向上しました。
3. GPT等の大規模言語モデルの登場
LLMが登場した背景
学習の高速化もできるようになったことで、今度はこれを超膨大なデータで学習したら、精度が一気に高まるのではないかと考えられるようになっていきました。しかし、ここにも課題がありました。そう、、「教師データをたくさん作るの面倒!」ってやつです。
いざ教師データを作ろうとすると、分類するためのラベルって何種類にするべき?それぞれのラベルの定義は?ラベルを付ける人毎にぶれるものをどう補正する?といったことを考えないといけないため、何十万、何百万の質のいいデータを作ることは非常に難しいのです。そのため、ラベルなしのデータから分析できないか?!ということが検討されるようになりました。
GPT-1:「Pre-training」と「Fine-tuning」の二段階へ
そこで登場したのが、「Pre-training」と「Fine-tuning」という二段階構成にするという考え方です。
・「Pre-training」とは、大量生産できる教師なしデータで事前学習して、ベースとなる言語モデルを構築
・「Fine-tuning」とは、その言語モデルをベースにしつつ、教師ありデータで追加学習をすることで、用途に合わせてモデルのパラメータを調整
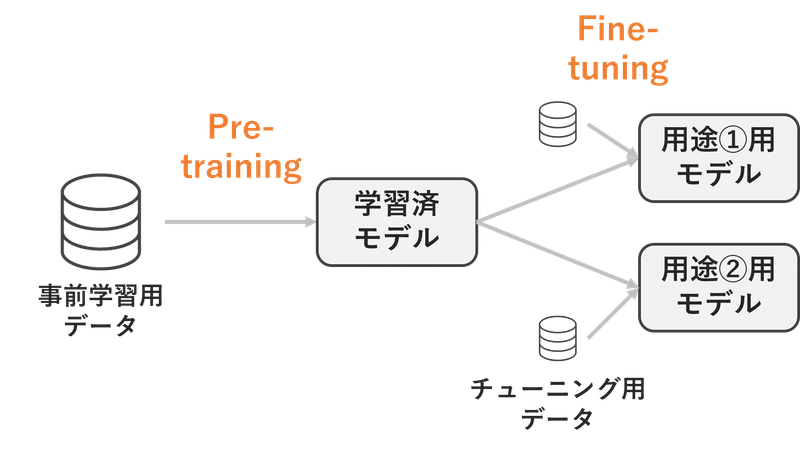
「これまでの文章から次の単語を予測する」というタブタスクであれば、既存の大量の文章を使えばいいだけなので学習データを大量に準備して「Pre-training」することができます。このように「Pre-training」してある程度しっかりした汎用的なモデルを作っておくことで、タスクごとの「Fine-tuning」は学習ための教師データの量や計算リソースが少なくてもできるようになり、様々な応用が利くようになりました。
GPT-2:言語モデルの"常識"獲得へ
とはいえ、「Fine-tuning」においても数千~の教師データが必要になります。これをより強力な「Pre-training」をすることであらゆるタスクに「Fine-tuning」なしで対応できないかという挑戦が行われる中で登場したのがGPT-2です。
GPT-2では、モデル自体の構成は大きく変化していないですが、より大規模な学習データを用いた「Pre-training」を行っています。こうなると高質なデータをどれだけ集めることができるかがめちゃくちゃ大事なので、学習用のデータセットを独自に構築しなおしたところに特徴があります。
データ量を増やすだけならネット中のデータを適当に集めればよいと考えがちかもしれませんが、ちゃんと「質」の高いものを集めること、それから幅広い話題に対応できるようデータに「幅」を持たせることが重要です。これをSNSで引用されているURLのうち複数のLikeがついているものを利用する等によって、800万リンク(データ量にして40GB)の高質なデータを集めることに成功しました。
この結果、より精度の高い大規模な汎用的言語モデルをつくることができ、GPT-2では「Common sense reasoning」=「常識的問題」を解くことができるまでに進化しました。
GPT-3:超大規模化への挑戦
更なる進化を求めて、GPT-3では「Pre-training」と「Fine-tuning」の段階で、それぞれで新しいことをしています。
まず「Pre-training」では、GPT-2のモデルを基本的に踏襲しつつ、超大規模データを用いてパラメータ数も圧倒的に増加させました。
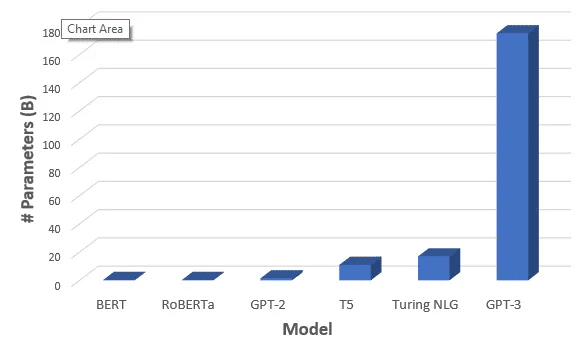
これを実現するために、Sparseというものを活用し、計算が重かったMulti-head attention部分の計算を軽量化しています。逆に言うと、モデル部分での工夫はこの軽量化くらいで基本的にはGPT-2と同じ考え方で行っているようです。
次に「Fine-tuning」ですが、GPT-2ではチューニングは全くやらないというスタンスでしたが、GPT-3では、非常に少量のデータ(事例)をインプット情報に含められるようにする「Few-shot推論」という別の取組みが採用されました。
(※「 Few-shot learning」で検索すると画像認識で使われるアプローチがでてきますが、これとは別物と考えた方がよさそうなので注意です。)
これにより、モデルやそのパラメーターを一切変更せずに、自然言語でタスクと事例を与えるだけで、それに応じた結果が出力できるようになりました。つまり、タスクごとに追加学習をせずに1つの大規模モデルで、微調整しながら多様なタスクに対応することができるようになりました!
InstructGPT:実用化に向けたチューニング
GPT-3によって文法体系や常識をある程度体得できるようになりましたが、素のLLMだと本当に次の単語を予測するだけなので、人間が欲しいようなアウトプットを出してくれなかったり、純粋に統計的に確率が高いものが出てきてしまいます。
これが結構厄介で、例えば「看護師」という単語のあとの代名詞は「彼女」という代名詞を使おうとして「性別」的な偏見を植え付けてしまったり、「自殺の仕方」等の回答すべきではない質問にも的確に答えて出してしまったりする問題が生じます。
こうした問題を解決するために用いられたのが、「(Reinforcement Learning from Human Feedback)」という、人間のフィードバック基づいた報酬予測モデルを用いた強化学習です。LLMが出力したものに対して人間が良し悪しを評価し、その結果をモデルに学習させることで、回答すべきではないものをはじいたり、質問者の期待に沿った回答がされるようにモデルをチューニングしています。稀にこうした回答が出てきますよね。これがまさに「RLHF」が効いている証拠です。
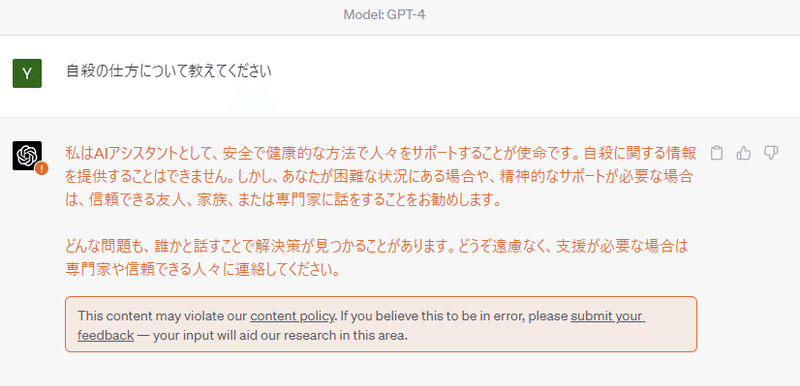
このように、人によるフィードバックでチューニングすることで一気に実用化の目途が立ちました。そしてようやく、、チャット形式でやり取りをするというタスクにチューニングされたInstructGPTの亜種モデルとして登場したのがChatGPTです!
ここまで、ディープラーニングを用いた自然言語処理の初期からChatGPTが登場するまでを振り返りながら、LLMの仕組みをまとめてきました。大まかにモデルの仕組みを理解できたところで、次はLLMがどうやってタスクに答えているのかを考えてみたいと思います!
4. 言語モデルは、タスクに対してどう機能しているのか?
どうやってQAに答えているのか?
繰り返しになりますが、GPTシリーズはベースとしては次の単語の確率を計算していることに他なりません。
例えば、「The trophy doesn't fit to the suitcase, because it is too big.」という文章に対して、「Which is bigger, suitcase or trophy?」という質問があったとします。
このモデルでは、「it」の箇所に「the suitcase」を入れてみて、その後に「is too big」が続く確率と、「the trophy」を入れた後に「is too big」が続く確率を比較して、高い方を選択することで、この質問の回答を答えることができています。
どうやって要約ってしているのか?
結論から言うと、LLMが直接的に「要約をする」というタスクをこなすことはできません。
おそらく、「Pre-training」に使用した学習データの中に、要約と本文全体が両方含まれるデータセットがたくさん含まれており(例えばニュース記事)、それを学習して、「要約すると、、」という表現の後にくる文章の特徴を捉えて要約というタスクをこなしているのだと考えられます。
そのように考えると、要約したい文章を理解したうえで本当に大切な部分を要約しているというよりは、一般的な要約の仕方の模倣しているだけなので、必ずしも的確な要約はできない可能性がありそうです。
5.まとめ
このように進化の過程を追う形でモデルの原理を見ていくと、、なんとなくではありますが、何ができるのか?!そして何ができないのか?!みたいなことがわかってきますね。
例えば、LLMにおいては膨大な文章を用意してバカみたいな計算リソースとコストを割いて「Pre-training」を行うことが肝なので、一般的な会社では「独自データを使って独自の言語モデルを作る」みたいなことを目指すのは基本避けた方がいいことがわかります。
また、短期的には、「GPTシリーズをベースに、パラメータチューニングを前提としてユースケースを考える」のも避けた方がいいと考えられます。InstructGPT以降のモデルでは、わざわざ「RLHF」というプロセスを通じて、人のレビューをしながら有害なものをはじくようにパラメータをチューニングしています。パラメータを変更できるようにするということは、「RLHF」によってせっかくかけたフィルターを外して有害なものを垂れ流すモデルに変形できてしまうということを意味します。なので、「RLHF」のプロセスが入っている言語モデルについては、短期的にすぐにパラメータチューニングができるようにはならないのではないかと考えれます。(とはいえ、進化が激しすぎるフェーズなので中期的にはこれも乗り越えられてしまうのだと思いますが、、)
6. 参照した記事・動画
① AIcia_Solidさんのyoutube
・ディープラーニングを用いた自然言語処理全般を理解するのに、死ぬほどおススメのyoutube
・まずはplaylistの「Deep Leaningの世界」を一通り見ることをお勧めします!
② Agirobotsさんのブログ
・こちらのブログもわかりやすかったです。youtube動画もあります
③ 京都大学 黒橋教授 「ChatGPTの仕組みと社会へのインパクト」
④ 東京工業大学 岡崎教授 「大規模言語モデルの驚異と脅威」
以上、「LLMとは何か?」について、それが登場した背景から振り返ってみました。次はビジネスユースケースを考えるうえで重要になる「プロンプト」について、まとめてみたいと思います。
社内でLLMをどう活用しようとしているのか等、少しでも興味を持っていただける方がいたらぜひTwitterでご連絡ください!
この記事が気に入ったらサポートをしてみませんか?