
とちおとめ苺の糖度を写真から予測

はじめに
苺栽培において、苺に触れずに、手間なく、コストをかけずに糖度を予測できないかと考えました。
そこで、苺の写真から糖度の予測を行いました。
Windows10、GoogleColoboratory、Python 3.7.13を使用しました。
とちおとめ苺の糖度を写真から予測するアプリhttps://strawberry20220513.herokuapp.com/
予測の流れ
1.データ収集
①苺の画像を撮影
②苺の糖度を糖度計で測定
2.取得した画像と糖度を元に機械学習モデルを作成
3.作成したモデルを用いて糖度を予測
4.モデルのチューニング
1.データ収集
①苺の画像を撮影
とちおとめ苺の写真を右側面、ヘタ部分、左側面の3方向からiPhoneで撮影しました。
苺127個×3方向からの381枚の画像を撮影しました。

②苺の糖度を糖度計で測定
写真撮影後、糖度計で苺の糖度を測定しました。
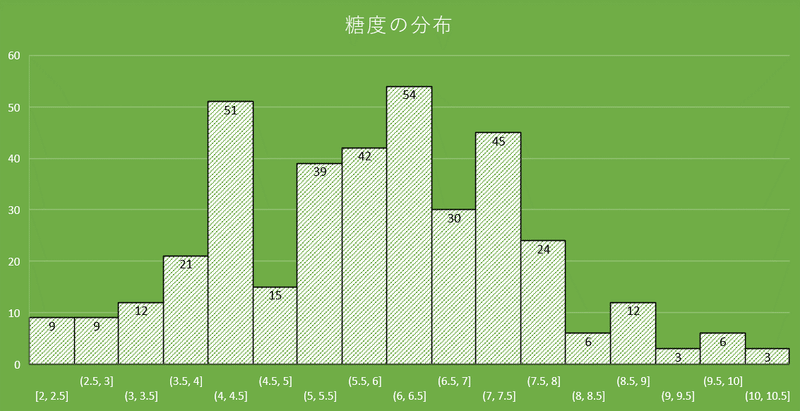
糖度の平均値は5.96、標準偏差は1.68、最大値は10.2、最小値は2.0でした。
データの分布は下図のようになりました。
正規分布と仮定しました。
2.画像と糖度から機械学習モデルを作成
目的変数 y 苺の糖度(数値)
説明変数 X 苺の画像
np.random.seed(444) #シード値の固定ディープニューラルネットワーク、VGG16の転移学習を使った機械学習モデルを作りました。
# モデルにvggを使います
input_tensor = Input(shape=(50, 50, 3))
vgg16 = VGG16(include_top=False, weights='imagenet', input_tensor=input_tensor)
top_model = Sequential()
top_model.add(Flatten(input_shape=vgg16.output_shape[1:]))
top_model.add(Dense(256, activation='relu'))
top_model.add(Dense(64, activation='relu'))
top_model.add(Dropout(0.5))
top_model.add(Dense(1))
# vggと、top_modelを連結します
model = Model(inputs=vgg16.input, outputs=top_model(vgg16.output))
# vggの層の重みを変更不能にします
for layer in model.layers[:19]:
layer.trainable = False
# コンパイルします
model.compile(loss='mse', optimizer=optimizers.Adam(learning_rate=1e-3))
# 学習を行います
model.fit(X_train, y_train, batch_size=32, epochs=40, validation_data=(X_test, y_test))3.作成したモデルを用いて糖度を予測
テストデータで糖度を予測し、正解値との平均二乗誤差を測定しました。
# テストデータで予測値を出力します。
y_pred = model.predict(X_test)
# 二乗誤差を出力します
mse= mean_squared_error(y_test, y_pred)
print("REG RMSE : %.2f" % (mse** 0.5))モデルのチューニング(後述)の結果、RMSEは1.40でした。
REG RMSE : 1.404.モデルのチューニング
最初に以下の条件で学習した場合、RMSEは5.01でした。
①全データを使用
②配分は訓練データ80%、テストデータ20%
③中間層ナシ
④ドロップアウト0.5
⑤評価関数adam、学習率e-5
⑥バッチサイズ100、エポック数10
以下のように変更した結果、RMSEが1.40に改善しました。
①全データを使用
②訓練データ90%、テストデータ10%
③中間層を1つ追加
④ドロップアウト0.5
⑤評価関数adam、学習率e-3
⓺バッチサイズ32、エポック数40
横軸をエポック数、縦軸をloss/val_lossとすると、下図のようになりました。
エポック数40の時点でlossは4.98、val_lossは1.96でした。

①使用するデータ
データ全体を使った場合、RMSEが1.40なのに対して
出現数の多い糖度4.0~8.0のデータのみを使った場合、RMSEは1.72でした。データ全体を使った方が精度が改善しました。
②訓練データとテストデータの配分
訓練データ80%、テストデータ20%とするよりも、
訓練データ90%、テストデータ10%の方が精度が改善しました。
③中間層
top_model.add(Dense(64, activation='relu'))
Denseの数は32より64の方が精度が改善しました。
また、中間層は複数よりも1つの方が精度が改善しました。
④ドロップアウト
top_model.add(Dropout(0.5))
Dropoutの率は0~0.6で試したところ、0.5が精度が改善しました。
⑤評価関数、学習率
model.compile(loss='mse', optimizer=optimizers.Adam(learning_rate=1e-3))
評価関数はSGD、adam、Rmspropで試したところ、adamが良い精度が出ました。
学習率e-2からe-5で試したところ、e-3が精度が改善しました。
⑥バッチサイズ、エポック数
model.fit(X_train, y_train, batch_size=32, epochs=40, validation_data=(X_test, y_test))
バッチサイズは16、32、64で試したところ、32が精度が改善しました。
エポック数は20、30、40、50、60で試したところ、40で精度が一定になりました。
おわりに
画像認識のAIを作って、チューニングを行い、精度を大きく改善することができました。
しかし、糖度の数値が2~10程度の数値であるのに対し、RMSEが1.40と誤差が高めです。
そのため、アプリでの表示は、糖度3.0未満:糖度が低め、3.0以上6.0未満:やや低め、6.0以上9.0未満:やや高め、9.0以上:高めと幅を持たせました。
今後、実際に苺を栽培されている方などにヒアリングして検討してゆきたいです。
この記事が気に入ったらサポートをしてみませんか?