
顔認識の実力:俳優はOK。政治家はダメ(Google Pixelを使う:その8)

◇Google Pixel 3は俳優の顔を認識する
Google Pixel 3は、人間の顔をどの程度識別できるだろうか?
まず、映画俳優を試して見た(PCの画面に出した写真を、グーグルレンズで撮影した)。
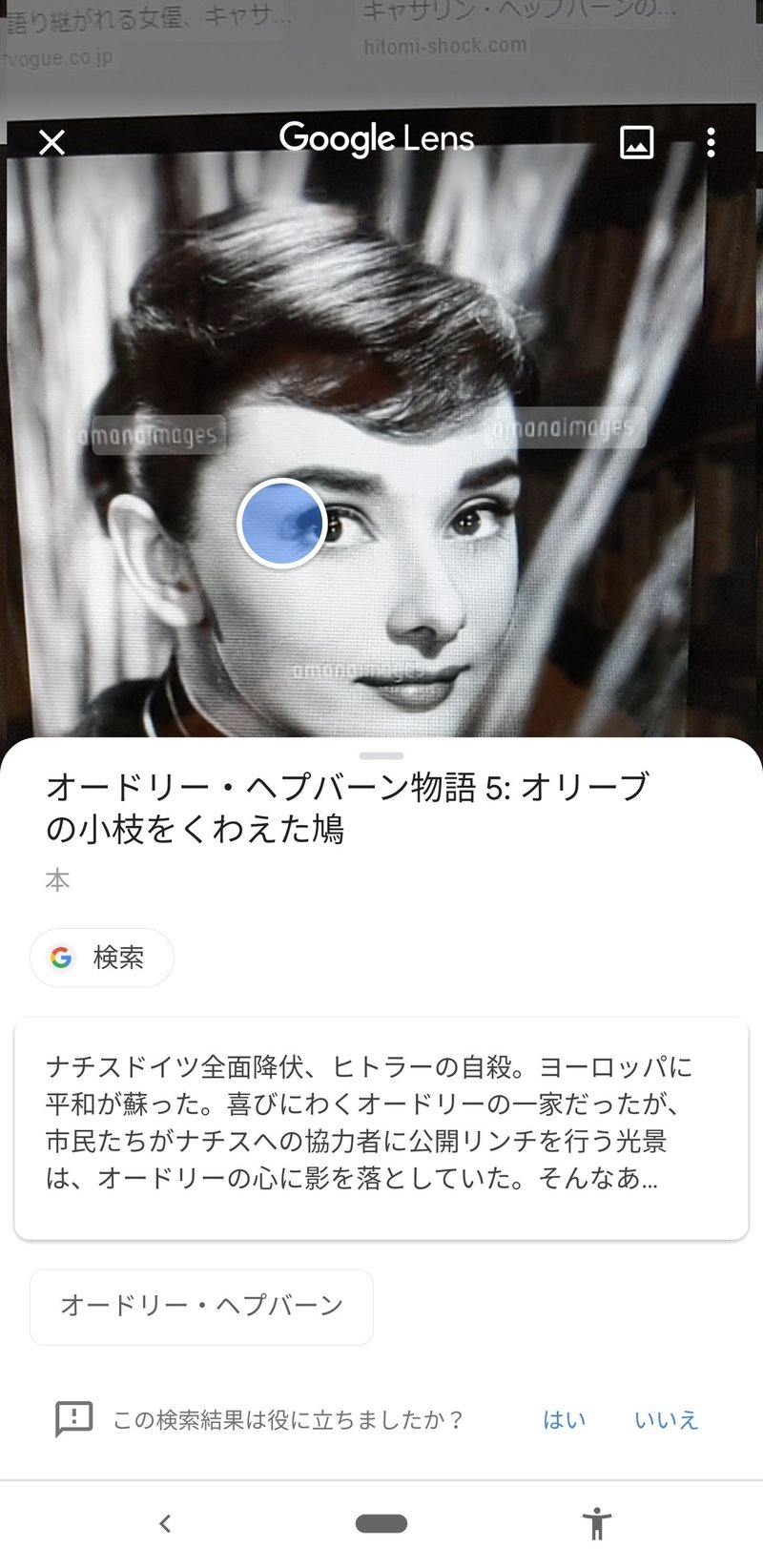
オードリー・ヘップバーン、キャサリン・ヘプバーンなどの有名女優は、難なく認識した。
男性でも、グレゴリー・ペックから始まって、名を知っている欧米の俳優はほとんど認識した。
いささか驚いたのは、それほど有名とはいえない女優の顔を認識したことである。下の写真は ジュリー・コックス。The Dune(砂の惑星:フランク・ハーバートの長編SFを原作としたアメリカのTVシリーズ)の主人公イルーラン姫を演じた。
Pixel 3は、見事「Princess Irulan」と言い当てた。
私は「砂の惑星」が好きで、コックスのファンだから、この写真を見ればすぐに分かるが、日本ではこの人のことはほとんど知られていないだろう。それを見事に特定しているのだから、すごい実力だ。

このように、欧米の俳優だと、Pixel 3の顔認識は、驚くほど成績がよい。
なお、日本の俳優では、三船敏郎は認識した。
ところが、それ以外は、私が試した限り、認識してくれなかった。
◇チャーチルの写真を見せたら、帽子と認識した
誰もが顔を知っている人となると、俳優のつぎは政治家だ。
ところが、政治家については、成績はガタンと落ちる。
スターリンは認識できなかった。毛沢東は、本の表紙として認識した。
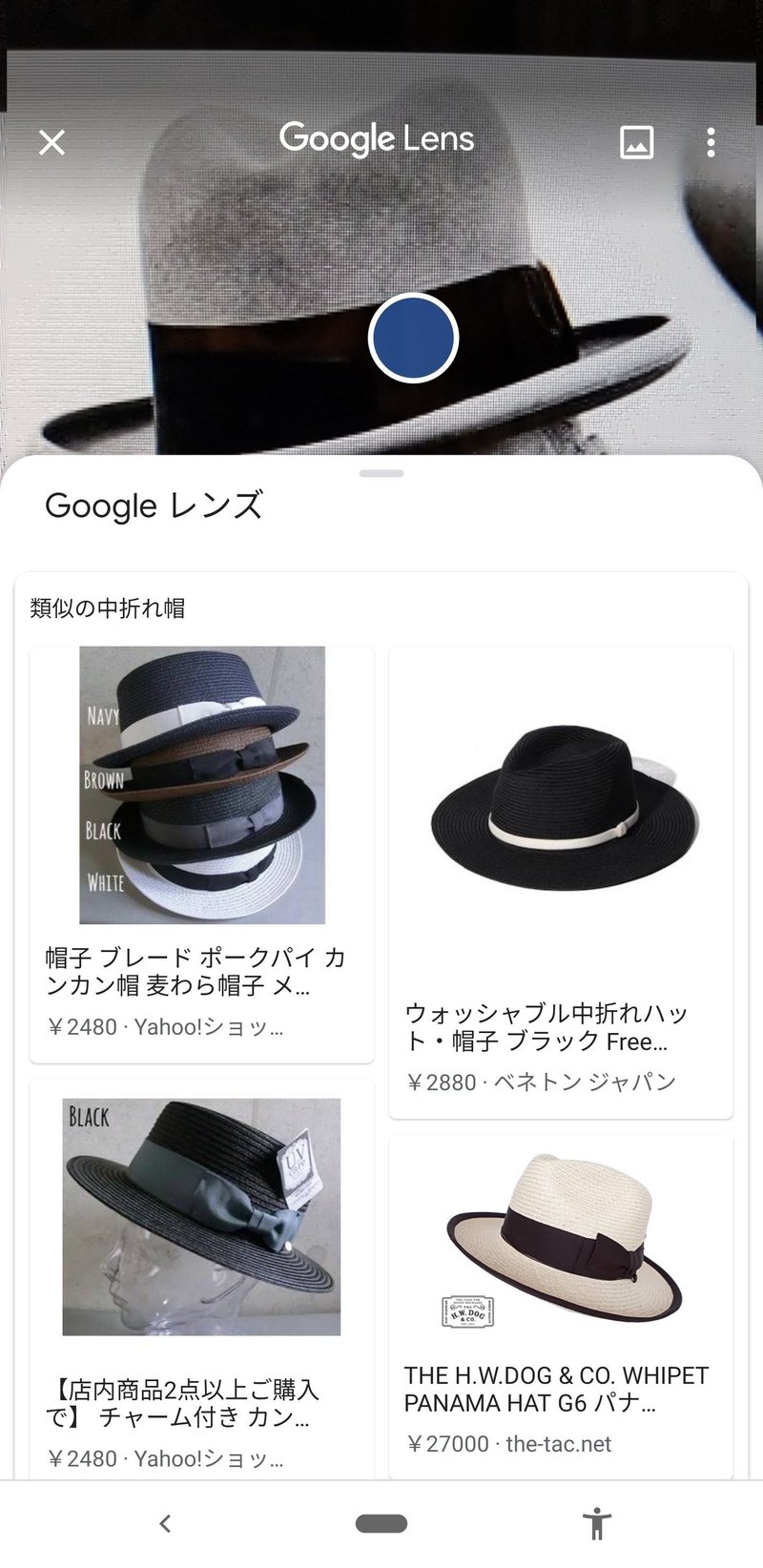
チャーチルは写真の2カ所を認識した。一カ所は、肖像画に描かれた人物として、もう一つは何と、人間チャーチルは無視して、中折れ帽であることを認識している。

最近の政治家となると、からきし駄目だ。トランプも、オバマも、ヒラリー・クリントンも、すべて認識できない。
レーガンは認識したが、これは元俳優だからだろうか?
もっとも、ヒッチコックを間違えたことをみると、「映画界の人間だから正しく認識できる」というわけではないようだ。
◇ポートレートでなく、書籍を参照している?
以上のように、Pixel 3の顔認識は、かなりミーハー的なバイアスを持っている。
どうしてこのようなことになるのだろうか?
顔だけしか写っていない写真も認識しているのだから、顔の特徴を掴んでいることは間違いない。
すると、参照するデータベースの問題か?どうもそうであるらしい。
では、どのような問題か?
それを知る手がかりが、ビートルズだ。写真を見せるとビートルズだと認識するのだが、個人名は間違える場合がある。
そして、ビートルズといっても、アルバムの名として出てくる場合が多い。
つまり、ビートルズのいずれかのアルバムとして認識しており、個々のメンバーとして認識しているのではないようだ。そのため、ポール・マカートニーやジョン・レノンでさえ、個人としては認識されていないようだ。
つまり、こういうことであろう。俳優や歌手は、映画の書籍やCDアルバムの表紙の写真をGoogleがデータとして保有している。
そして、俳優などの写真を見せると、顔を認識するが、個人を認識しているのでなく、映画やアルバムとして認識しているのではないだろうか?
上で見たオードリー・ヘップバーンの場合にも、『オリーブの小枝をくわえた鳩』という書籍として認識したようだ。
この推測を裏付ける証拠は、他にもある。
「ハリーポッター」のハーマイオニーの写真を見せたところ、「エンマ・ワトソン」とは認識せず、「ハーマイオニー」と認識した。

グーグル検索でimagesを選ぶと、政治家でもかなりの数の写真が出てくる。しかし、これらは、googleがデータとして持っているわけではない。だから参照できないのだろう。
つまり、バイアスは、ポートレートのデータベースではなく、本の表紙のデータベースを参照していることに起因するもののようだ(ひょっとすると、アマゾンのデータを見ているのだろうか?)。
そうだとすれば、バイアスは、ミーハー的なものではなく、逆のものであることになる。
◇「データベースが重要」ということの意味
以上で見たのは、静止画の認識である。しかもほぼ正面を向いた明瞭な写真を対象にしたものだ。これは、静態認証とか積極認証と呼ばれるもので、その技術は、暫く前に確立されていた。
いまAIで問題になっているのは、道を歩いている人、動いている人、横を向いたり下を向いている人などを認識できるかどうかという問題だ。これは、非積極認証と言われるもので、積極認証に比べると格段と難しい。
上で見たようにグーグルレンズが静態認証であるにもかかわらず、政治家の顔や日本人の俳優の顔を認識できなかったのは、顔自体が認識できないからではなく、参照すべきデータベースがないからであろう。
人間の顔以外の対象についても、問題はどれだけのデータベースを参照できるかということにあるようだ。
したがって、画像認識をどの程度実際に使えるかは、参照できる膨大なデータベースを持っているかどうかという問題に帰着するように思われる。
こうしたデータベースを利用できるのは、Google、amazon、Netflixなど、ごく1部の企業に限られてしまう。ということは、AI時代における経済活動が、このような企業によってコントロールされてしまうことを意味するわけだ。
一方、文字のテキスト化については、データベース参照の問題がないので、実用の範囲は広いと言えるだろう。
この記事が気に入ったらサポートをしてみませんか?