
noteの機械学習フローを共通化してレコメンデーションで成果をあげた話

こんにちは.noteの基盤開発グループ機械学習チームに所属している安井です.普段は機械学習を活用したシステムの開発から運用までトータルでおこなっています.
noteでは記事の分類やレコメンデーションに機械学習を用いて作成されたモデルが使われています.いくつか例を挙げますと,noteに投稿された記事をカテゴリごとにまとめて見るために,記事をカテゴリごとに機械学習で分類しています.また,”あなたへのおすすめ”としてユーザごとにパーソナライズされたおすすめ記事をとどけるためにも機械学習が活用されています.
それらサービスで活用されている複数の機械学習モデルには記事の内容から分散表現を獲得する似たような仕組みが存在しました.今回はそれらを共通コンポーネントとして切り出し,分散表現を推論・保存まで行う仕組みを構築しました.また,その分散表現を活用したレコメンデーションにより,既存のレコメンデーションの仕組みよりCTRを上昇させることに成功しました.
この記事では記事の分散表現を保存する仕組みとその活用としてのレコメンデーションにおいて構築したシステムについて説明します.noteのサービスと機械学習システムってこうやって連携しているんだなという部分が少しでも伝われば幸いです.
noteにおける機械学習タスクの課題
一般的には機械学習タスク,特に教師あり学習のタスクは次のような流れで処理が実行されます.
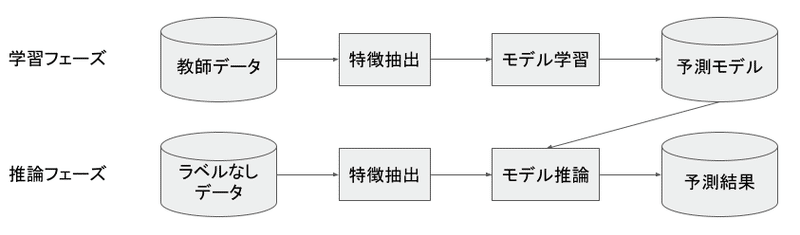
noteでも記事のカテゴリ分類や属性の推論,類似記事のレコメンデーションに図3のような流れで機械学習のタスクは実行されます.特徴抽出では記事のタイトルや文章のテキストデータを事前にGensimやfastTextで学習しておいたモデルを使用して分散表現に変換しています.ただし,分散表現のモデルを運用していく中で次のような課題にぶつかりました.
基本的に分散表現の獲得はタスク間で共通な処理であることが多く,タスクごとに推論するのは非効率である
分散表現のモデルサイズと文章のデータサイズが大きく,一度に扱える記事の数に制約が発生する
ユーザの行動データと記事の内容を同時に扱う処理では,タスクの実行時間が非常に長くなり,施策として実施しづらい
そこで,記事の分散表現を事前に計算・保存することで課題の解決を図りました.保存した分散表現は,その後の機械学習タスクで活用することを想定しています.これにより,機械学習タスクのサービス早期適用と機械学習で扱える記事量の増加,記事データと他のデータを統合する処理の実現を狙っています.
記事に対する分散表現推論と保存の仕組み
それでは分散表現を推論,保存する仕組みについて説明します.大まかなフローは次の図のようになっています.
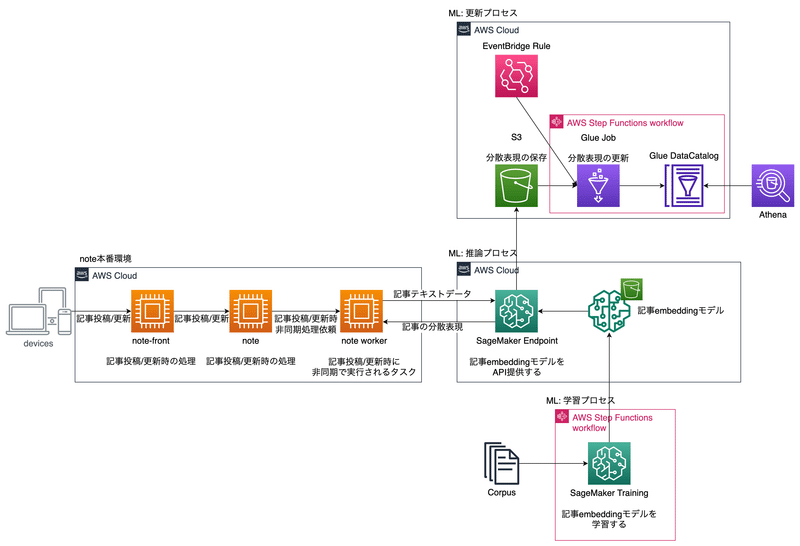
分散表現の推論フローは大きく分けると3つのフェーズに分解できます.
学習フェーズ
noteの記事群から構築されたコーパスからDoc2Vecを用いて記事の分散表現を計算するモデルを学習(このモデルを記事Embeddingモデルと呼ぶ)
学習したモデルをS3に保存
推論フェーズ
学習フェーズで保存した記事EmbeddingモデルをSageMaker EndpointからAPI経由で提供
APIは記事の投稿・更新をトリガーとして呼び出されS3に分散表現を保存
加えてレスポンスとして分散表現を返し,後続のタスクで活用
更新フェーズ
S3に保存された分散表現はGlue Catalogに定期的に登録され,Athenaから参照可能になる
Athenaで参照できる分散表現は記事の分析やその他機械学習タスクで活用されます.この仕組みについて,この記事では2つのフェーズについて詳しく説明していきます.
[学習フェーズ]Doc2Vecによる記事Embeddingモデルの学習
今回,記事Embeddingモデルの学習にはDoc2Vecを活用しています.選定理由としてはこれまで採用実績があり,いくつかのnoteにおける機械学習タスクにも活用されていたというのが理由です.必要であればこのモデルは入れ替えることが可能なため,安定かつ実績があるという面を重視しました.
Doc2Vecの論文では2つの手法が提案されていますが,Distributed Memory Model of Paragraph Vectors(PV-DM)という手法を適用しました.この手法によるモデル学習の概観は次の図のようになっています.
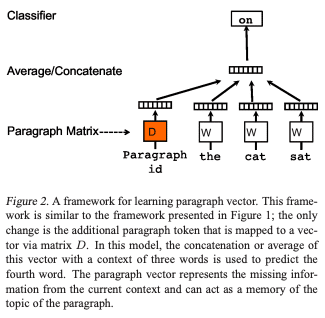
簡単に説明すると,文章に含まれる単語をその周辺の単語とその文章idに紐づく分散表現から推測するように学習を行います.なぜこのような学習で適切な分散表現を獲得できるか例を用いて説明します.次のような一部の単語が抜けている文を考えます.

この□(四角)に入る単語を想像してみてください.単純に考えると雨が入りそうに思えます.しかし,傘は帰り道で雨に降られた時のために持っていくとすると曇りが入るかもしれません.もしくは明日は晴れなので傘を持って行かないという文章も考えられます.とはいえなんとなく天気にまつわる単語であることがわかります.
このように文章中の単語はその周辺の単語によって意味づけられると考えることができ,天気にまつわる単語は分散表現のベクトル空間上で近しい距離に位置するようにモデルが学習されると考えられます.この”文章中の単語はその周辺の単語によって意味づけられる”という考え方と,同一文章中はトピックが一貫しているという考え方からDoc2Vecの学習が行われています.詳しく知りたい場合はこちらの論文を参照ください.
[更新フェーズ]一時テーブルと永続テーブル
ここでは更新フェーズについて詳しく説明します.記事EmbeddingモデルのAPIは記事の投稿・更新をトリガーとして呼び出されます.ゆえに,S3に保存される記事の分散表現は同一記事に対して重複して存在する可能性があります.これは,分散表現の活用時にどれが最新の推論結果か判定する必要があり非効率的です.また,Glue Catalogで構築されるテーブルはデフォルトだと記事idを指定したアップデートはできません.これらの問題を解決して記事に紐づく最新の分散表現のみをテーブルから参照するために一時テーブルと永続テーブルの2つのテーブルを次の図のように運用しています.
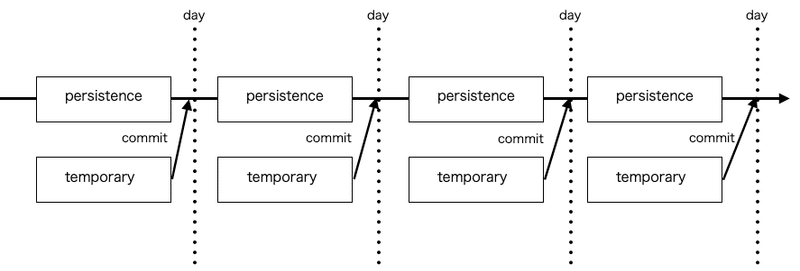
一時テーブル(temporary)
記事Embeddingモデルの推論結果を参照できるテーブル
記事に対して複数の分散表現が存在する可能性がある
永続テーブル(persistence)
記事の分散表現を保存するマスターテーブル
記事に対して唯一最新の分散表現のみが保存されている
dailyで前日の一時テーブルの結果により更新が行われる
このような仕組みを構築することで,前日までに投稿・更新された記事の分散表現のみ活用する場合は永続テーブルのみを,当日投稿・更新された記事の分散表現まで必要となる場合は当日に作成された一時テーブルまで参照すれば最新の分散表現を取得できるようになりました.
今回はデフォルトのGlueの仕組みのみで構築しましたが,最近では更新可能なデータウェアハウス(DWH)の技術も出現してきています.
Apache Hudiは別の仕組みで活用していたりするので,記事の分散表現の保存にもこれらの技術を今後活用したいと考えています.
記事の分散表現を活用したタスク事例
今回作成した記事の分散表現の仕組みを活用してアップデートしたタスクについて説明します.noteでは記事の下に"こちらもおすすめ"という形で記事のレコメンデーションを行なっています.こちらいくつかの仕組みで記事をレコメンドしているのですが,その一つに表示されている記事と内容が似ている記事をレコメンドしている仕組みが存在します.(以下類似記事レコメンデーションと呼ぶ)
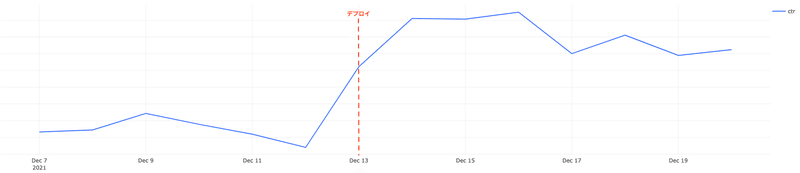
こちらの類似記事レコメンデーションの仕組みは以前よりgensimのDoc2Vecを活用して学習・推論まで行っていました.こちらを今回保存した分散表現 + 近傍探索(faiss)による仕組みで置き換えました.置き換えた結果,最初に提示した図2のとおりCTRが劇的に上昇する結果となりました.
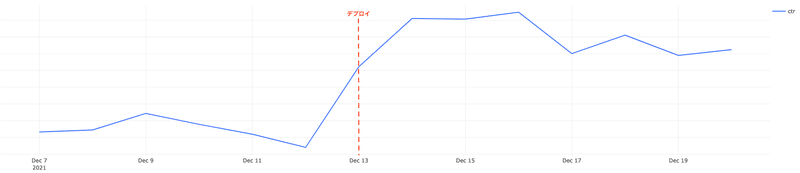
とはいえこのCTRの上昇は分散表現の表現力が向上したためではなく,新しい分散表現の仕組みにより,過去に投稿された記事も多くレコメンドできるようになった結果だと考えています.理由としては,分散表現の獲得には新旧どちらの仕組みでもDoc2Vecが使われている点,本番適用前の同条件でのABテストでは両者に差が見られなかった点があげられます.本番適用時の変更点としてはこれまで投稿されたすべての記事をfaissのindexに載せることで,より記事と近しい内容の記事をレコメンドできるようになった点になります.以前の類似記事レコメンデーションの仕組みでは学習・推論をすべてgensimのDoc2Vecで実行しており,定期的に再学習する必要がありました.ゆえに,レコメンデーションするためのモデルに含められる記事の量に制約がありました.今回は,この制約を突破することでCTRの上昇につながったと考えています.
記事の分散表現を保存することで可能になったこと
今回は記事の分散表現を記事の類似記事レコメンデーションに活用しましたが,他にも次のようなメリットがあると考えています.
機械学習タスクの本番適用までを高速化できる
図2における特徴抽出は完了している状態でタスクを開始できるので,機械学習タスクにおけるいくつかのフェーズをスキップすることが可能になります.また,類似記事レコメンデーションの結果から察するにある程度細かい粒度でのカテゴリ分類問題も比較的容易に解けそうに感じているので,モデル自体もLogistic Regression等の簡易な仕組みで構築できるのではないかと思っています.
ユーザの行動データと組み合わせて活用できる
レコメンデーションには協調フィルタリングと呼ばれるユーザの行動データからアイテムの類似度を計算したり,ユーザに対しておすすめするアイテムを推測したりするアルゴリズムが存在します.これはアイテムの情報を直接使わなくても,ユーザの行動データのみからレコメンデーションができるため,広く使われています.こういった協調フィルタリングには付加情報を追加できるアルゴリズムが存在し,その付加情報として記事の分散表現が活用できるのではないかと考えています.また,ユーザの行動データから作成されたグラフデータにおいて記事の分散表現をnodeの情報として考えればグラフニューラルネットワークのアルゴリズムも活用できるかもしれません.このように,ユーザの行動データと記事の分散表現を組み合わせることでより性能の高いモデルの作成を狙えるのではないかと思っています.
記事以外の分散表現も計算できる
noteでは色々なデータが記事と紐づいています.そういった記事との関係性を活用すれば簡易的に記事以外にも分散表現を付与することができます.例えば,
クリエイターの分散表現
クリエイターが投稿した記事に紐づく分散表現の平均
ハッシュタグの分散表現
同一ハッシュタグがついている記事に紐づく分散表現の平均
このようにすれば記事の近さだけでなく,クリエイターの近さも計算できるようになると考えられます.
おわりに
今回は,記事の分散表現を推論・保存する仕組みについて説明しました.現在はまだ応用先のタスクは多くはありませんが,今後活用できる部分に対しては積極的に活用していければと思っています.また,この分散表現を保存する仕組みにもいくつか課題が残っています.
分散表現のGlue Datacatalogのアップデートの複雑化
先に述べたようにDWHの技術を応用することで解決したい
分散表現自体の性能
文章だけでなく画像の情報も組み込みたい
必要があればBERT等のContextual Embeddingを活用したい
もちろんnoteというサービスが,よりクリエイターにとってより良いサービスになることを目的とすることが前提ですが,技術的にもチャレンジできていければと考えています.
noteではクリエイターが自分の理想を実現できる,記事が読んで欲しい人たちに適切に届くことを目的とした機械学習システムを運用する仲間を募集しています!興味がある方は是非下のリンクからご応募ください!
エンジニア
プロダクトマネージャー
感想等も合わせて送られてくると嬉しいです!