
日刊 画像生成AI (2022年11月15-16日)

ジェネレーティブAI界は、今とても早いスピードで進化し続けています。
そんな中、毎日時間なくて全然情報追えない..!って人のためにこのブログでは主に画像生成AIを中心として、業界変化、新表現、思考、問題、技術や、ジェネレーティブAI周りのニュースなど毎日あらゆるメディアを調べ、まとめています。

📣大事なお知らせ
ジェネレーティブAIで事業を沢山考えた中で、どうしてもやりたい事業が見つかり、Webアプリケーション開発ができ、今後一緒に取り組める方を探しています。小さく短期的なものは考えていません。
本気で一緒に取り組めて、ジェネレーティブAIに深い興味のある方、
フロントとバックが高いレベルでかける方を探しています。
(費用は捻出します)
もし興味がありましたら、TwitterでDMをいただけますと幸いです。
何卒よろしくお願いいたします🙇
過去の投稿はこちら
開発
Runwayに動画文字起こし、字幕、ノイズ除去が搭載
Runwayに新しいAIツールが搭載。ワンクリックで動画の文字起こしと字幕を自動生成。動画からノイズの削除ができるとのこと。
Introducing new audio and text AI Magic Tools
— Runway (@runwayml) November 16, 2022
Generate subtitles and transcripts automatically. Remove noise and silence from your videos. All with just one click.
Get started now: https://t.co/vsP0D05845 pic.twitter.com/XXoqeIEIgS
Deforum Stable Diffusionが0.6vに更新
コンディショニング、ローカル動作、k-samplers搭載、2D、3Dビデオのマスキング、xformers対応、git動画生成など、沢山機能が追加されているようです。
Deforum Stable Diffusion v0.6
— deforum (@deforum_art) November 16, 2022
- conditioning
- local runtime
- new k-samplers
- masking 2d and 3d videos
- xformers efficient attentionhttps://t.co/WILFzn7Vbc
Galacticaが公開
(画像生成AIじゃないけど、話題だったので紹介。)
MetaAIが科学用に論文や科学的コーパスで学習させた大規模言語モデルを公開。テキストを入力したら、関連する参考、数式、論文を生成してくれます。また、学術文献の要約、数学の問題解決、Wiki記事の生成、科学コードの記述、分子やタンパク質の注釈など、様々なことが可能なようです。
🪐 Introducing Galactica. A large language model for science.
— Papers with Code (@paperswithcode) November 15, 2022
Can summarize academic literature, solve math problems, generate Wiki articles, write scientific code, annotate molecules and proteins, and more.
Explore and get weights: https://t.co/jKEP8S7Yfl pic.twitter.com/niXmKjSlXW
Paellaが公開
10ステップ以下のステップで高忠実度画像のサンプリングが可能なt2iモデル「Paella」が公開。

573Mのパラメータを持ちながら、1つの画像を500ms未満でサンプリングできる速度最適化アーキテクチャを用いた、10ステップ未満で高忠実度の画像をサンプリングできる新しいテキストから画像へのモデル。このモデルは圧縮・量子化された潜在空間上で動作し、CLIP embeddingを条件とし、従来のものより改良されたサンプリング関数を用いています。
Fast Text-Conditional Discrete Denoising on Vector-Quantized Latent Spaces
— AK (@_akhaliq) November 15, 2022
abs: https://t.co/iX3hg5HOVn
github: https://t.co/TPwZNSJgaD
t2i model requiring less than 10 steps to sample high-fidelity images pic.twitter.com/veHSlEmkaG
なんかまたヤバそーだぞコレ。ベクトル量子化潜在空間におけるテキスト条件付き離散ノイズ除去の高速化。要するに高速な画像生成AI。A100を使って16バッチの画像生成を1秒で終わらせるらしい?秒間16枚生成がマジならもうリアルタイムアニメ生成出来ちゃえると言っていいだろう →RT pic.twitter.com/5Ph8Fit7sF
— うみゆき@AI研究 (@umiyuki_ai) November 15, 2022
MinD-Visが公開
脳の記録から再構築
— やまかず (@Yamkaz) November 17, 2022
ある画像を見てる人の脳をMRIスキャンし、脳信号に基づいて画像を再構築する「MinD-Vis」が発表https://t.co/zKGZZsdUCu pic.twitter.com/b6y5tGuPu6
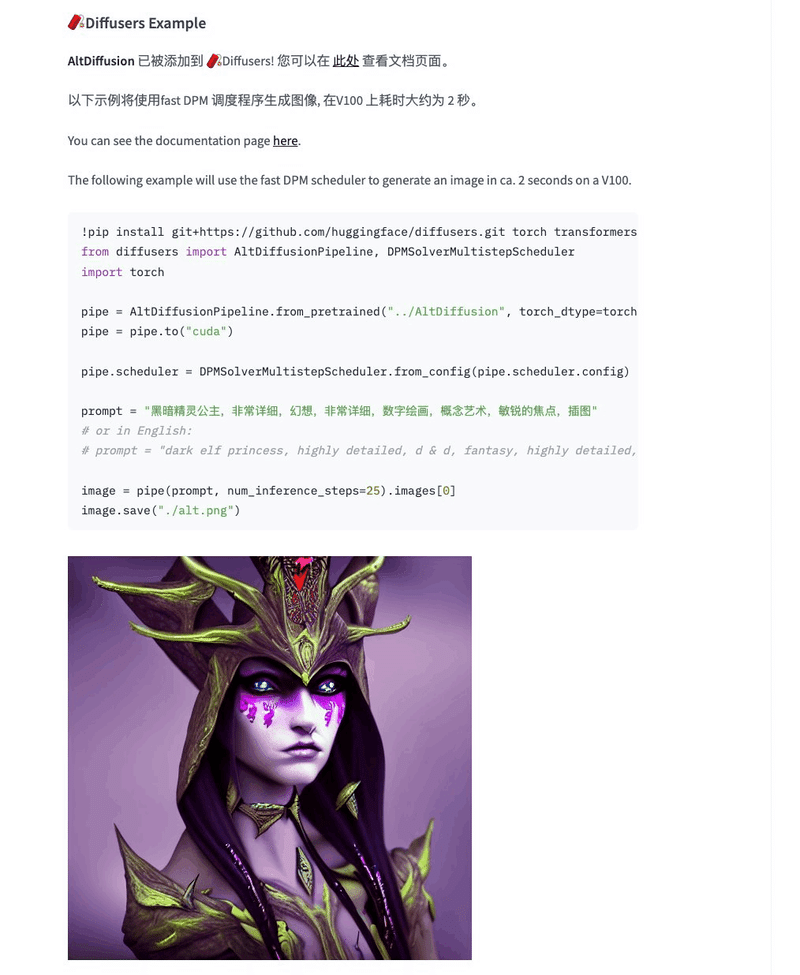
AltDiffusion
中国語と英語の両方のテキストから画像を生成できるAltDiffusionが公開。
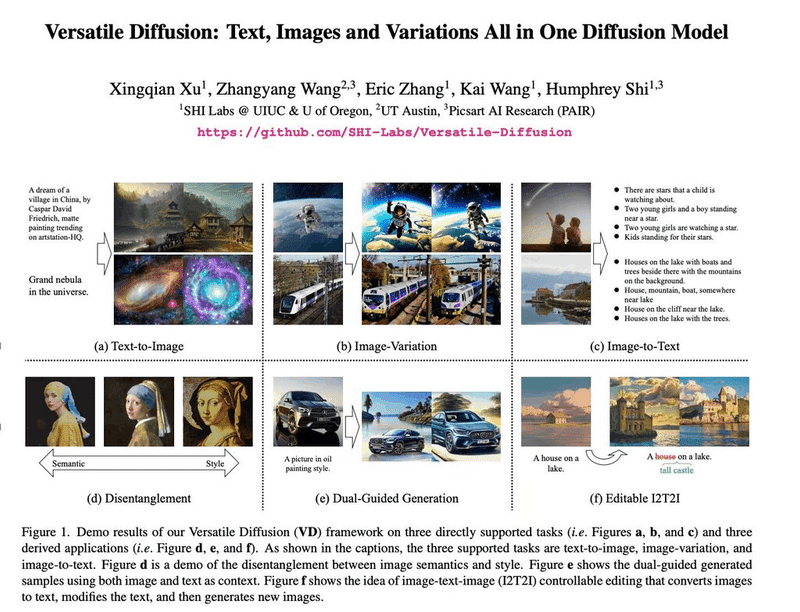
Versatile Diffusion
Versatile Diffusionが発表。テキストから画像生成や、バリエーション生成、画像からテキスト生成、(この辺り理解できていないです。)セマンティックスタイルの異種混合、テキストデュアルガイド生成、他幅広いことが可能なオールインワンDiffusionモデル。
CLAP
(結構前に公開されていた..かもです?)LAIONがオーディオ版のデータセットを公開。Stability AIが予告しているAudio Diffusionに使われそう。
ついに来た。巨大な画像×テキストデータセットでおなじみの LAION が今度は 63万ペアの「オーディオ×テキスト」で訓練した CLIP 的なモデル「CLAP」を OSS としてリリース。
— ステート・オブ・AI ガイド (@stateofai_ja) November 16, 2022
画像生成 AI で起こった CLIP 主導の革命がオーディオ分野でも起こりつつある。目が離せない https://t.co/wGzejJvOsn
二重露光モデルが公開
Midjourney v4の出力を30枚学習させたモデル。トークンは「dbl_ex」を利用。Euler aかDDIMで20-30steps、CFG 4-5の設定が適切とのこと。

Retro_SF モデルが公開



Macro Bugモデルが公開
プロンプトにキーワード「macro_bug」を利用すると使えるとのこと。

StableDiffusion Sprite SheetのDemoが公開
以前載せた、4つの異なる角度からのピクセルアートスプライトシートを生成できる「PixelArt_SpriteSheet_Generator」を試せるDemoが公開されています。よかったらぜひ
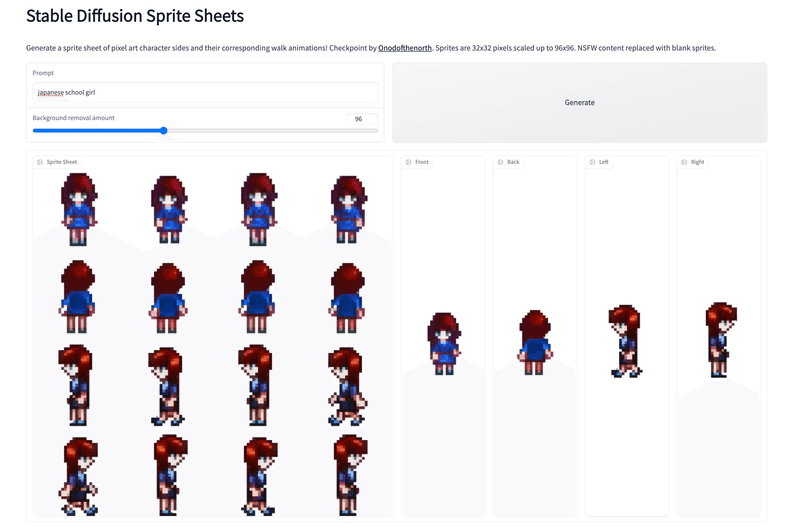
(うみゆきさんも一緒の結果だった)
Built with diffusers for inference, PIL for extracting/cleaning/constructing the images and Gradio for the UI. Play with it here! https://t.co/4kZx6o1MvK
— Ron Au 🦆 (@ronvoluted) November 15, 2022
魔咒百科词典
中国で作られた、クリックするだけで高精度なプロンプトを作成できるウェブアプリ魔咒百科词典(呪文百科事典)が公開されているようです。Gigazineさんが使われていました。(追えてなかった、、)
画像生成AIユーザーの英知を結集させた高品質呪文辞典「魔咒百科词典」を使って高品質な画像を生成してみたhttps://t.co/a6CKaiMbFU
— GIGAZINE(ギガジン) (@gigazine) November 14, 2022
UnivAICharGenの使い方まとめ (Gigazine)
あらかじめ作り込まれた美しい画像を生成するプロンプトをランダムで生成しまくることができる拡張機能、UnivAICharGenの使い方をGigazineさんがまとめられています。
画像生成AI「Stable Diffusion」でガチャガチャ感覚で美麗画像を生成しまくれる拡張機能「UnivAICharGen」の使い方まとめhttps://t.co/Xbbu3CIlrf
— GIGAZINE(ギガジン) (@gigazine) November 15, 2022
Notion AIが公開
(画像生成AIじゃないけど話題だったので紹介。)
NotionがついにAIツールを導入。AIでブログ投稿、議事録、メール、ブレインストーミング、文法を修正、テキストを翻訳が可能になったようです。機能豊富すぎて強い..!

shodaiさんがわかりやすくまとめられていたのでどうぞ😊
Notionから新機能「Notion AI」が発表されたので簡単に機能や注意点をスレッドにまとめてみました👇
— shodai | NotionとCanvaと京大起業部の人 (@shodaiiiiii) November 16, 2022
👉https://t.co/lQRbcDim3m pic.twitter.com/O9xP0sLgcp
Huggigfaceが色々プチアップデート
複製(dupliication)と、裏側で動いているハードウェアが表示されるように仕様が変更。
Hugging Face Spaces now supports dͩuͧpliͥcͨaͣtͭiͥoͦn!
— Abubakar Abid (@abidlabs) November 16, 2022
Take your favorite machine learning demo and edit the code, customize the look, or run it on different hardware. With just a few clicks ⚡️ pic.twitter.com/0MdoapkQDq
🚀 Wow, why this space runs so fast?
— Bertrand Chevrier (@kramp) November 16, 2022
You can now see the hardware used to power @huggingface 🤗 spaces.
Try it out on https://t.co/yrCuCOAjCQ#machinelearning #gpu #huggingface pic.twitter.com/so5se13YE0
Stability AIが今年初め4000から5408GPUに 🫢
Stability AI (people behind Stable Diffusion and an upcoming Chinchilla -optimal code model) now have 5408 GPUs, up from 4000 earlier this year - per @EMostaque in a Reddit ama
— Jack Clark (@jackclarkSF) November 16, 2022
USP.ai - ROYALTY FREE AI Image Generator
StableDiffusionが使えるChrome拡張が登場。
音楽をリアルタイムのAI生成画像に変換するツール
We collaborated with Teenage Engineering to create a tool that translates music into real-time AI generated imagery. Together with @BureauCool, we connected the OP–Z to @StableDiffusion@jugendingenieur #teenageengineering #stablediffusion pic.twitter.com/8td6f6nCas
— MODEM (@modem_works) November 15, 2022
表現
AI生成画像と信じ難い..
Anything V3.0と思われるいくつかの投稿。もうよく見ても分からなくなってる。というかAIか人間が書いたかどうよりすごい魅力的な絵が多すぎて..リークモデル使いたいけど使えないジレンマ。あと絵師の友人に聞いたらかなりこの画風に似ている絵師さんがいて、あの人のだなぁ..って感じらしいです。
それはきっと、こんな形#AIart #stablediffusion #イラスト pic.twitter.com/mKKwHtkl2w
— はかな鳥 (@hcanadli12345) November 15, 2022
ツイートした瞬間に妙案をひらめいた結果こんな感じのイラストが生成できた。十分使えそうだAV3君🙃
— アオまる🐏AIも使える絵師 (@ao_illust) November 16, 2022
(たぶん再現できないけど呪文はaltに入れてあります)#AIart pic.twitter.com/Uhyq6ivbJk
anything v3.0、何が凄いかっていうと、このpromptでこれが生成されるんですよ…
— kaz (@tkaz2009) November 16, 2022
恐るべし…
というわけで、prompt大公開。 pic.twitter.com/UC7wBumqxd
存在しないトンチキスチームパンク嘘日本の存在しないプリント写真
久しぶりのMidjourneyでの大バズ投稿。精度上がってるから高度な面白画像もっと出てきていいと思う
ヤ,ヤッタァ〜〜〜!!!
— 猫黒夏躯 (@NatsukuPhoto) November 15, 2022
進化した #midjourney V4の力により,存在しないトンチキスチームパンク嘘日本の存在しないプリント写真が,無限に作れる…!!! pic.twitter.com/o9nfK1Akmr
研究、検証
State of AI Report 2022
AI投資家の方が制作している、AIにおける最も興味深い開発を分析する今年で5年目のレポート。「私たちは、AIの現状と将来への影響について、十分な情報を得た上で会話をするきっかけを作ることを目的としています。」とのこと。ちゃんと読まなきゃ
bioshokさんやなんかさんなどが一部日本語で取り上げられてます。メモ
AIスタートアップとテック大手の連携一覧。参考になる。https://t.co/zqvaxw60uu pic.twitter.com/2vVYrShoMG
— bioshok(INFJ) (@bioshok3) November 16, 2022
State of AIの2022年レポート読んでたら各組織ごとのA100保有数ランキング出てきた、21世紀版の核弾頭保有数ランキングみたいでおもしろいhttps://t.co/Mzd0a9Y42A pic.twitter.com/mqTWFEMyJL
— なんか (@_determina_) November 15, 2022
birdManさんのDAAM検証
Stable Diffusionで「どの呪文がどこに効いているか」を可視化する手法、DAAM試してみました!
— birdMan (@birdMan710Nika) November 16, 2022
(要するにStable Diffusion用のGrad-CAMみたいなもん)
詳細はALTに記載。
これは呪文研究に効果を発揮しそう…!https://t.co/loE3uYkbzc pic.twitter.com/2sxF2nE5N0
ミクさんベースで全く別キャラのプロンプトで生成するi2i動画検証
AIのi2i動画をひたすら検証されている方の1人、猩々 博士さんの検証。
少しずつ浅いimg2imgを繰り返したらいけないかな..気になる。
昨晩の結果。
— 猩々 博士🧪学術系Vtuber (@Mega_Gorilla_) November 16, 2022
ミクさんベースで、プロンプトを元動画と一致させずにアスカを錬成できないかのテスト。
むー、元動画と構図が一致しないのでi2iが暴れてるねー pic.twitter.com/Qek3xI1930
++, ¥¥
最近生成から離れているので生成技術に関してしっかり読み込んでいなかったりするんですが、今プロンプトこんな感じになってるんですか? リプ欄を確認した所、前後のPromptと切り離してAIに描いてもらうという機能があるようです。

NovelAIの作品指定の絵柄テスト
NovelAIの作品指定の絵柄テスト(もっといっぱいある)。情報まとめてくれてるサイト色々あるけど女の子生成向けばかりなので…#NovelAI #NovelAIDiffusion pic.twitter.com/RDnoR4TDCf
— にくまん@AIお絵描き中 (@29man_birds) November 13, 2022
(11/13に追えていなかったもの)
思想・ムーブメント
洞察に満ちたインタビュー@l2kと@EMostaqueの@StabilityAI
Prompt: "Insightful interview between @l2k and @EMostaque of @StabilityAI" 🤝
— Weights & Biases (@weights_biases) November 15, 2022
• Teaching Literacy ➡️ AI Art; Stability's origin
• How to generate business from generative art 🎨
• Ethics and regulation of open source ML and models ⚖️https://t.co/R9lLpUvr9D pic.twitter.com/5LHjKnfzs8
Stability AIがRedditでAMA開催
Starting an AMA on /MachineLearning, come ask questions of the team. https://t.co/DLOdjAHttz
— Emad (@EMostaque) November 15, 2022
Scale AIのアレックス・ワン氏が、AIの現状、スタートアップの構築、防衛におけるAI+倫理、考えることの学習について語る。
NovelAIDiffusionを使用して既に1億2000万を超える画像が作成
It has been thrilling to see everyone sharing their text and image generations. We are absolutely stunned that over 120,000,000 images have been created with #NovelAIDiffusion since the Image Generation release.
— NovelAI (@novelaiofficial) November 15, 2022
生成AIはインターネットを汚染し、死に至らしめるかもしれない
Diffusionの90日
Daniel Eckler氏のいつものAI系スレッドまとめ投稿。
90 Days of Diffusion
— Daniel Eckler ✦ (@daniel_eckler) November 15, 2022
90 🤯 AI Advances 👇
気になるツイート
AI画像の倫理性、未来にどう決着つくのかなぁという話。
— 深津 貴之 / THE GUILD / note.com (@fladdict) November 15, 2022
AIを労働者として考えた場合、「ミッキーを描くのがうまい労働者を雇う」のはOK。「ミッキーを描くのがうまい労働者、海賊版ミッキーを描かせて自社で売る」のはNG。
という感じになるのではないかと思う。
https://t.co/QP1HqNW8su
— bioshok(INFJ) (@bioshok3) November 15, 2022
2022年10月時点での現状の投資家によるAIレポートでの来年AIに起こる10の予測。
来年は音生成AIの時代になり、マルチモーダルモデルや言語モデルはさらに洗練され大きくなるという予測。 pic.twitter.com/tWcI1ROkfe
勉強
Huggig Faceコース Transformerについて
Hugging Faceから日本へのお知らせです!
— Hugging Face (@huggingface) November 15, 2022
Hugging Faceコースの日本語翻訳を始めました。東北大学のStudent Ambassadorsの皆さんのお陰で第一章の翻訳が終了しました。
今後もコツコツと翻訳していきます。
是非コースを読んでHugging Face Tranformersについて学んで、使ってみてください!
マルチモーダルVAE
松尾研の鈴木先生によるマルチモーダルVAE関係のサーベイ。とりあえずマルチモーダルVAE周りはこれを読んで追いつきましょう。各位。
— Tanichu/たにちゅー (Tadahiro Taniguchi, 谷口忠大) (@tanichu) November 15, 2022
>A survey of multimodal deep generative models https://t.co/igR9VDDaLm
拡散モデルがどのように機能するか?
I will attempt to explain the basic idea of how diffusion models work!
— Tanishq Mathew Abraham (@iScienceLuvr) November 16, 2022
... in only 15 tweets! 😲
Let's get started ↓
Sonyの生成モデルの講義シリーズ
ソニーがYouTubeに無料公開している、生成モデルの講義シリーズ。GANやVAEからDiffusion modelまで丁寧に解説してくれる。
— QDくん⚡️Python x 機械学習 x 金融工学 (@developer_quant) November 16, 2022
【Deep Learning研修(発展)】データ生成・変換のための機械学習https://t.co/6iveoI2Bys pic.twitter.com/2Y0WMcfGLL
最後に
Twitterに、毎日製作したものや、最新情報、検証を載せたりしています。
よかったら見ていただけたら嬉しいです。
画像生成AIの実験, 最新情報のまとめはこちら
過去の号はこちら
次の号はこちら
サポートいただけると喜びます。本を読むのが好きなので、いただいたものはそこに使わせていただきます