英語で征く深層学習1:ニューラルネットワークのオーバービュー


「深層学習の勉強をしたいけど、何なら英語でやりたい!」そんな方にお送りするニッチな企画、「英語で征く深層学習」。今回は第一回、「ニューラルネットワーク」のお話です。
深層学習の最小単位であり、最初に理解すべき概念であるニューラルネットワーク。なるべく分かりやすく書いていきます。
# What is a neural network
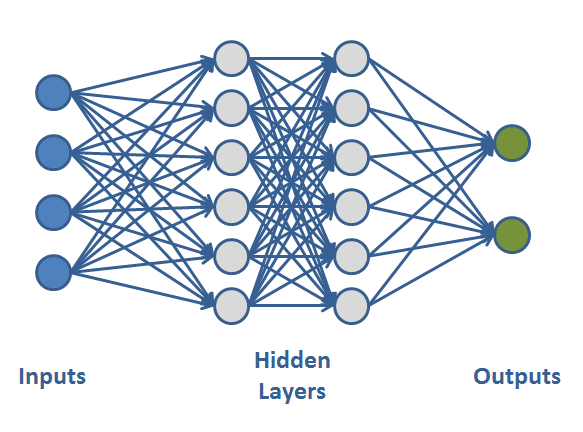
Neural network is a basic architecture of deep learning network. As a usual network, it is formed by group of edges and nodes, but its overall architecture is formulated by stratified structure called "layer" (as you can see in the image above). Simplest deep learning network can be formed with several layers, connecting all nodes between them. Now, with the brief introduction, I will introduce you a theoretical part of neural network.
# Artificial Neuron Overview
Shortly, artificial neuron (shortly neuron) is a single unit of object which forms neural network. It is analogous (precisely, hinted by) to brain neurons, and structured by node and edges.
Let us closely look at it. Basic architecture of neuron is formed by "input(s)", "weight(s)", "linear combination (sum)", and "activation" as shown in the image below.

Mathematically, in a single neuron, all the corresponded values and weights are multiplied, then added together (if you are familiar with linear algebra, you can think all inputs and weights as a vector, and neuron is just taking a dot product of those). Also, there exists some biased weights that we need to add. This sequence of process is mathematically called "linear combination", which some of you might be familiar with. Furthermore, our goal is to optimize those parameters (weights and biases) to improve accuracy of the model. As you can see, a single neuron itself is just doing a simple linear computation. However, this does not differ as much from a standard linear regression. In order to differentiate neuron from other regular regression processes, we need to talk about a process called “activation”.
Activation is a process that non-linear function (often called activation function) returns “activated” data, based on a processed (linear transformed) data. The main purpose of activation is to improve the expressiveness of the model, meaning it fits the model to complex task which cannot achieved with simple linear computations. For example, sigmoid function (i.e. logistic function) is one of them. This entire process of linear transformation and activation is called forward propagation, which is the way that neural network computes the outputs based on inputs.

Notice that this forward propagation is not a limited process for single neuron, but for all neurons in the network you form. Thus the same process recurrently occurs until data reaches to the output layer.
Now, I guess you get a basics of neurons and how it works. Up next, we will dive into more technical parts of neural network. First comes first, the loss function.
# Loss function 101
You now have the basic architecture of neuron and connected multiple of them in gentle order to form a neural network. Although the forward propagation ultimately derives the output, we still do not have any system to “train”. What I mean here to train, is to optimize the unknown parameters (which are weights and biases). To train, we will introduce the idea of “loss function” as did in machine learning. With given output by neural network, loss function computes “loss” between the outputs and the ground-truth (target) values. Minimizing (or sometimes maximizing) this loss simultaneously indicates optimization of parameters we are interested in. I will touch this loss functions and training methods in another note entry since there is a lot of technical and practical things with little bit of complex concepts.
# This is pretty much it for the brief overview of neural network! Next time, I will write about the training methods and techniques. Thanks for reading.
Reference: L2 - UCLxDeepMind DL2020
この記事が気に入ったらサポートをしてみませんか?