【Stable LM】エロもアングラも教えてくれる禁断のLLMとは?使い方〜実践まで徹底解説!

こちらの記事では、Stable LMについて、概要や導入方法、実際に触ってみた感想をまとめています。
弊社のエンジニアによると、Stable LMはChatGPTより規制が少なくいとのこと。
例えば、
エッチな質問、使い方
悪用の可能性がある情報(例:ハッキング、爆弾の作り方、等)
その他、アングラ系やグレーな質問
にも、答えてくれる可能性が高いそうです!
確かに、ChatGPTやBardを使っていると、Googleで聞けるような少しグレーな内容でも「その質問には答えられません」ってなりますよね?
どうやら、StableLMはなかなかそういったことが少ないらしいのです。
加えて、この記事ではStable LMと同じStability AI社が開発した、画像生成AIのStable Diffusionとの違いについても解説しています。
噂の真相を確かめるためにも、最後まで記事を読んでください。
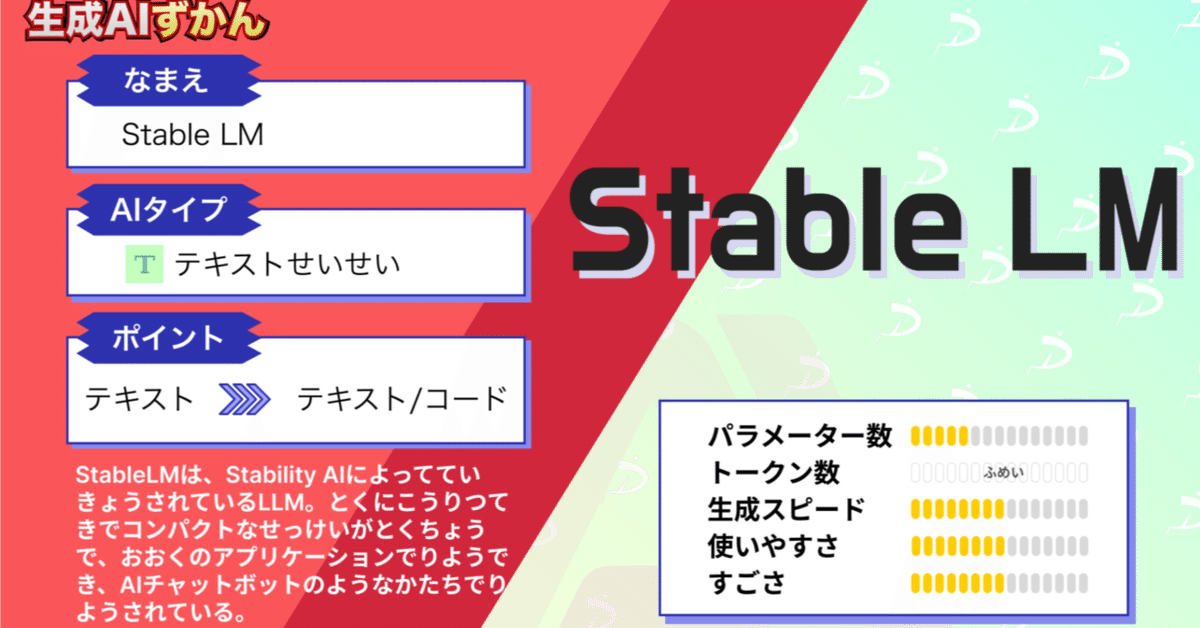
Stable LMの概要
Stable LMとは「大規模言語モデル(Large Language Model, LLM)」の一つです。開発元はStability AI社で、同社は「Stable Diffusion」で知られています。
Stable LMは今年の4月19日に公開され、現在はアルファ版がGitHubで公開されています。
このモデルは、30億から70億個のパラメータを持つという大規模さが特徴です。
それだけでなく、将来的には150億から650億個のパラメータを持つモデルも公開される予定だそうです。
このStable LMについて、詳細な技術レポートが近日中に公開予定です。
Stable LMの特徴
それでは、Stable LMの主な特徴を見ていきましょう。
大きく分けて3つあります。
LLMとしては比較的小規模なモデルです。
しかし、その小規模さにも関わらず、その精度は高いです。
会話やコーディングタスクなど、様々な用途で優れたパフォーマンスを発揮します。
これらの特徴は、1.5兆トークンが含まれる「The Pileベースのデータセット」を元にして生み出されました。
Stable LMの利用条件
Stable LMを商用や研究目的で利用する場合、CC BY-SA-4.0ライセンスの条件に従う必要があります。
具体的には、「原作者のクレジットを表示すること、改変した部分に元の作品と同じライセンスを継承すること」が必要です。
[ad_tag id="20905"]
Stable LMの導入方法
導入方法は無料と有料の2種類があります。
無料で使う方法:Hugging Faceのサイトから使う
手軽に、コーディング無しでアルファ版を利用するなら、HuggingFaceのサイト上から実行しましょう。
「Chat Message Box」のところに、メッセージを打ち込むと、StableLMが回答を返してくれます。
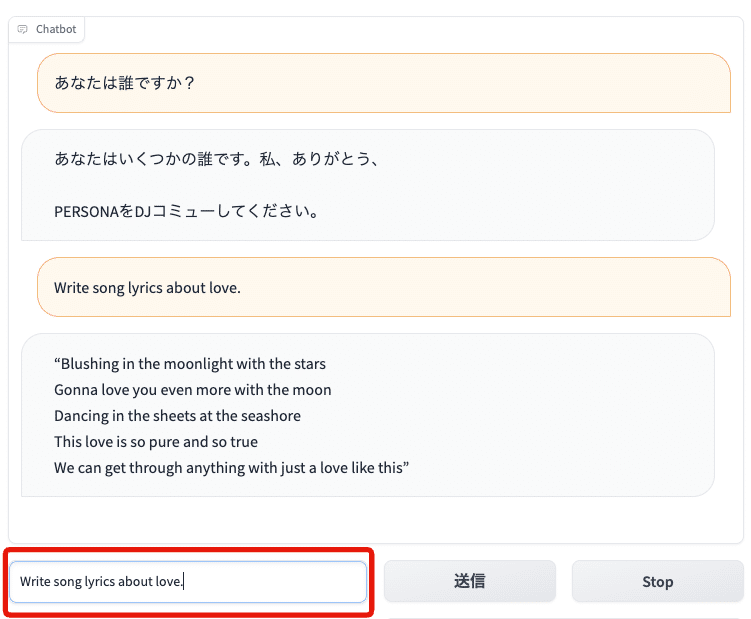
今のところ日本語の対応はしていないため、英語での入出力となります。
こちら↓では、「あなたは誰ですか?」と質問しました。
それに対して、StableLMは意味不明な文章を返してきました。
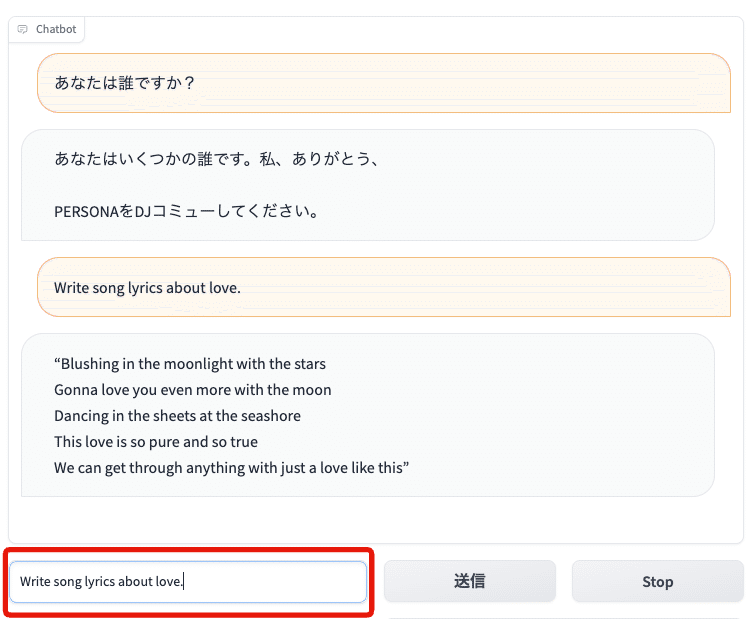
今のところ日本語の対応はしていないため、英語での入出力となります。
こちら↓では、「あなたは誰ですか?」と質問しました。
それに対して、StableLMは意味不明な文章を返してきました。
有料で使う方法:Google Colabを使う
Google Colab上で始めるには、以下のPythonプログラムを実行してみます。
細かい設定(出力する文字数など)を自身で変えたい場合は有用です。
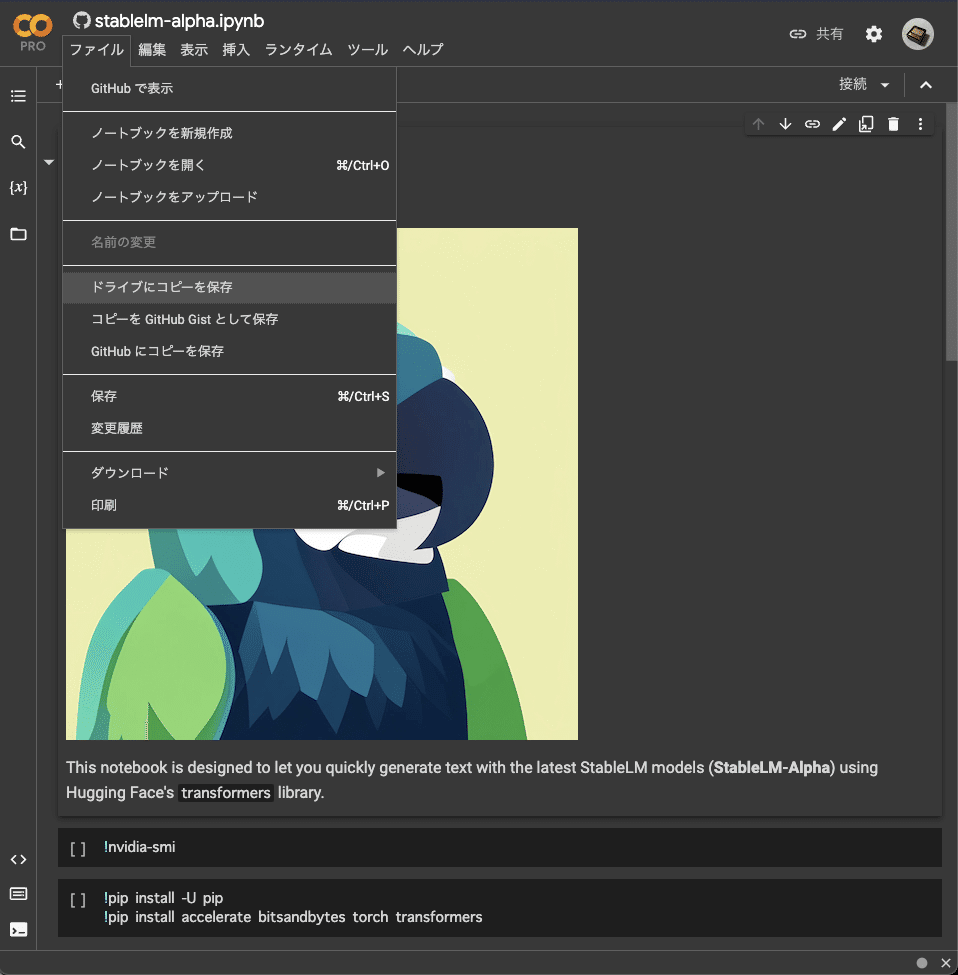
こちらのリンクから、Google ColabのNotebookを開きましょう。
https://colab.research.google.com/github/Stability-AI/StableLM/blob/main/notebooks/stablelm-alpha.ipynb?authuser=1
このファイルをGoogle Driveにコピーします。
GPUを使うために「ランタイム」→「ランタイムのタイプを変更」から設定を変更する。
今回は、以下のように設定しました。
ハードウェアアクセラレータ:GPU
GPUのタイプ:A100
ランタイムの仕様:ハイメモリ
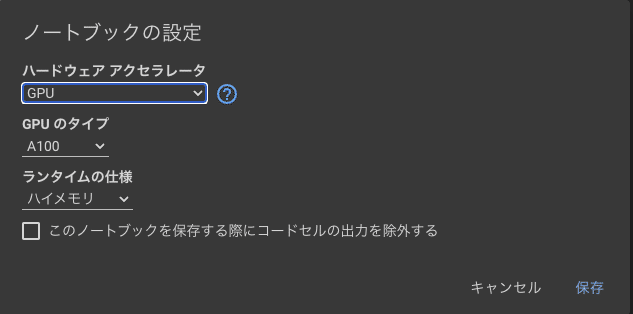
準備はOK.
以下のnvidia-smiコマンドを実行して、NVIDIAのGPUの使用率やメモリ使用量、消費電力、温度などを確認しましょう。
!nvidia-smi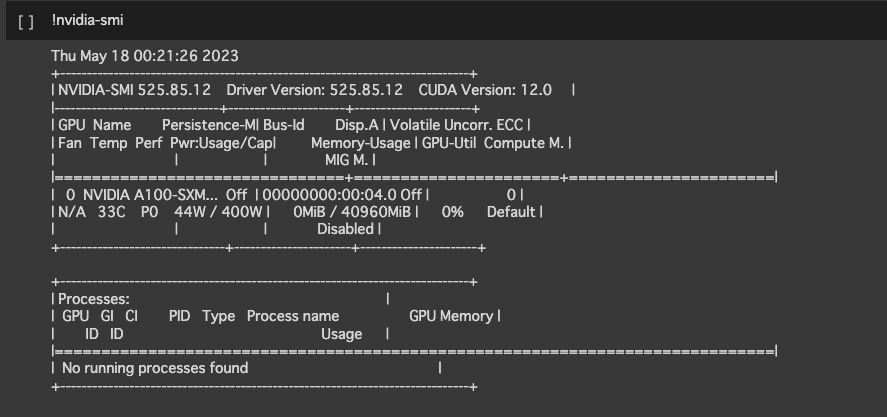
以下のコマンドで、必要なライブラリをインストールします。
!pip install -U pip
!pip install accelerate bitsandbytes torch transformersインストールの完了には、数分ほど時間がかかります。

ライブラリのインストールが完了したら、次はライブラリのインポートや、関数の定義をします。
#@title Setup
import torch
from transformers import AutoModelForCausalLM, AutoTokenizer, StoppingCriteria, StoppingCriteriaList
from IPython.display import Markdown, display
def hr(): display(Markdown('---'))
def cprint(msg: str, color: str = "blue", **kwargs) -> str:
if color == "blue": print("\033[34m" + msg + "\033[0m", **kwargs)
elif color == "red": print("\033[31m" + msg + "\033[0m", **kwargs)
elif color == "green": print("\033[32m" + msg + "\033[0m", **kwargs)
elif color == "yellow": print("\033[33m" + msg + "\033[0m", **kwargs)
elif color == "purple": print("\033[35m" + msg + "\033[0m", **kwargs)
elif color == "cyan": print("\033[36m" + msg + "\033[0m", **kwargs)
else: raise ValueError(f"Invalid info color: `{color}`")
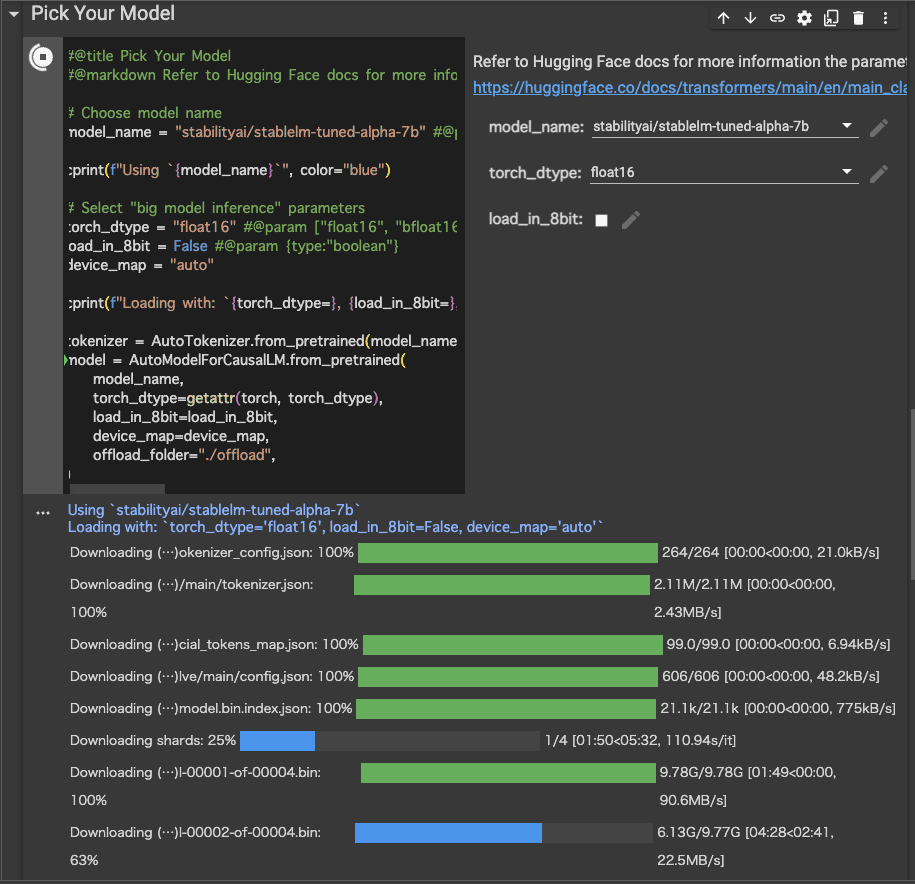
タスクに合わせた事前学習済みモデルの選択に移ります。
ここでは、HuggingFaceから、StableLMを選択します。
#@title Pick Your Model
#@markdown Refer to Hugging Face docs for more information the parameters below: https://huggingface.co/docs/transformers/main/en/main_classes/model#transformers.PreTrainedModel.from_pretrained
# Choose model name
model_name = "stabilityai/stablelm-tuned-alpha-7b" #@param ["stabilityai/stablelm-tuned-alpha-7b", "stabilityai/stablelm-base-alpha-7b", "stabilityai/stablelm-tuned-alpha-3b", "stabilityai/stablelm-base-alpha-3b"]
cprint(f"Using `{model_name}`", color="blue")
# Select "big model inference" parameters
torch_dtype = "float16" #@param ["float16", "bfloat16", "float"]
load_in_8bit = True #@param {type:"boolean"}
device_map = "auto"
cprint(f"Loading with: `{torch_dtype=}, {load_in_8bit=}, {device_map=}`")
tokenizer = AutoTokenizer.from_pretrained(model_name)
model = AutoModelForCausalLM.from_pretrained(
model_name,
torch_dtype=getattr(torch, torch_dtype),
load_in_8bit=load_in_8bit,
device_map=device_map,
offload_folder="./offload",
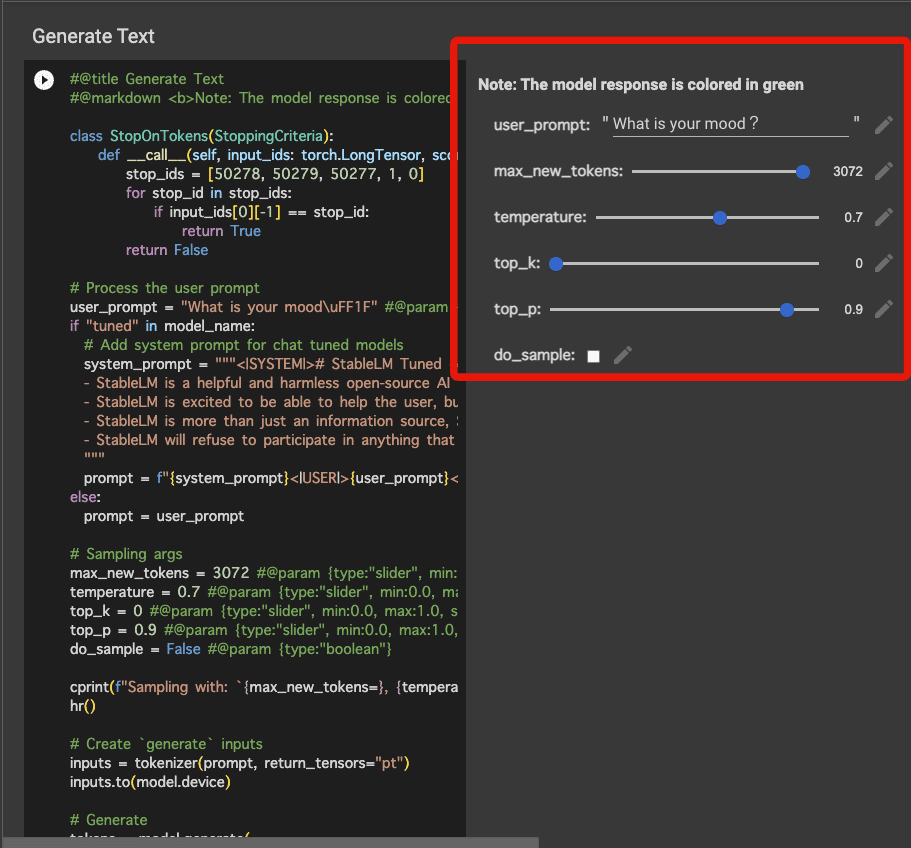
)下記の画像の右側にある、各プルダウンメニュー・チェックポイントで、各パラメータを変更することが可能です。
それぞれのパラメータの意味は、下記の通りです。

下記のコードを実行して、文章生成を行いましょう。
#@title Generate Text
#@markdown <b>Note: The model response is colored in green</b>
class StopOnTokens(StoppingCriteria):
def __call__(self, input_ids: torch.LongTensor, scores: torch.FloatTensor, **kwargs) -> bool:
stop_ids = [50278, 50279, 50277, 1, 0]
for stop_id in stop_ids:
if input_ids[0][-1] == stop_id:
return True
return False
# Process the user prompt
user_prompt = "What is your mood\uFF1F" #@param {type:"string"}
if "tuned" in model_name:
# Add system prompt for chat tuned models
system_prompt = """<|SYSTEM|># StableLM Tuned (Alpha version)
- StableLM is a helpful and harmless open-source AI language model developed by StabilityAI.
- StableLM is excited to be able to help the user, but will refuse to do anything that could be considered harmful to the user.
- StableLM is more than just an information source, StableLM is also able to write poetry, short stories, and make jokes.
- StableLM will refuse to participate in anything that could harm a human.
"""
prompt = f"{system_prompt}<|USER|>{user_prompt}<|ASSISTANT|>"
else:
prompt = user_prompt
# Sampling args
max_new_tokens = 3072 #@param {type:"slider", min:32.0, max:3072.0, step:32}
temperature = 0.7 #@param {type:"slider", min:0.0, max:1.25, step:0.05}
top_k = 0 #@param {type:"slider", min:0.0, max:1.0, step:0.05}
top_p = 0.9 #@param {type:"slider", min:0.0, max:1.0, step:0.05}
do_sample = False #@param {type:"boolean"}
cprint(f"Sampling with: `{max_new_tokens=}, {temperature=}, {top_k=}, {top_p=}, {do_sample=}`")
hr()
# Create `generate` inputs
inputs = tokenizer(prompt, return_tensors="pt")
inputs.to(model.device)
# Generate
tokens = model.generate(
**inputs,
max_new_tokens=max_new_tokens,
temperature=temperature,
top_k=top_k,
top_p=top_p,
do_sample=do_sample,
pad_token_id=tokenizer.eos_token_id,
stopping_criteria=StoppingCriteriaList([StopOnTokens()])
)
# Extract out only the completion tokens
completion_tokens = tokens[0][inputs['input_ids'].size(1):]
completion = tokenizer.decode(completion_tokens, skip_special_tokens=True)
# Display
print(user_prompt + " ", end="")
cprint(completion, color="green")下記の画像の右側にある、各プルダウンメニュー・スライダー・チェックポイントで、各パラメータを変更することが可能です。
それぞれのパラメータの意味は、下記の通りです。

また、各パラメータはHuggingFaceのドキュメントに、詳細な説明が載っています。
以上で、Google Colab での実行手順は終了です。
実際に触ってみた
これ以降は、以下の記事からご確認ください。
他の記事もご覧になりたい方は、こちらをご覧ください。
この記事が気に入ったらサポートをしてみませんか?