optunaによるrandom forestのハイパーパラメータ最適化

Introduction
今年12月2日にPreferred NetworksからリリースされたPython言語における機械学習向けハイパーパラメータ自動最適化フレームワークoptuna(開発者はあの秋葉氏)の紹介記事です。主にsklearnを触ったことがある人向けに、optunaの使い方を簡単に紹介します。今回は、例としてensembleモジュールのRandomForestClassifierクラスを用います。
1. optunaのインストール
インストールは以下をターミナルで叩くか、もしくはjupyter notebookを使っている方であればコードブロックで半角!マークを追加して実行することでoptunaをインスト―ルできます。
# optunaのインストール
pip install optuna # jupyter notebookの場合: ! pip install optuna
今回は、ランダムフォレストのハイパーパラメータをoptunaを用いて自動最適化してみましょう。
2. データの生成とタスクの設定
今回は、2値ラベルの分類問題moonsデータセットをsklearn.datasetsモジュールのmake_moons関数で生成し、random forestで分類します。以下のようにデモデータを生成しましょう。
# デモデータの生成
from sklearn.datasets import make_moons
X, y = make_moons(n_samples = 1000, shuffle = True, noise = 0.3)もし、このデータセットの様子を確認したい場合は、次のスクリプトを実行してください。
# データの可視化
import matplotlib.pyplot as plt
plt.scatter(X[:,0], X[:,1], c = y, alpha = 0.5)
plt.show()生成したデータを訓練データとテストデータに分割しておきます。
# 訓練データとテストデータに分割する。
from sklearn.model_selection import train_test_split
X_train, X_test, y_train, y_test = train_test_split(X, y)ランダムフォレストを特定のハイパーパラメータのもと訓練データで学習し、テストデータでの正答率を確認します。この正答率が最も高くなるような、ハイパーパラメータをoptunaを用いて求めるのが今回のタスクです。
3. 試してみよう
ランダムフォレスト分類器は、sklearn.ensembleモジュールのRandomForestClassifierクラスで実装できます。RandomForestClassifierには以下のような3つのハイパーパラメータがあり、それぞれ次の候補のなかから解を求めてみましょう。
・min_sample_split:8, 9, ..., 16までの整数値
・max_leaf_nodes:4, 8, 16, ..., 64までの整数値
・criterion:"gini", "entropy"
手順は大変シンプルです。目的関数とハイパーパラメータの候補を定義します。ハイパーパラメータの候補はtrialインスタンスによって定義されます。
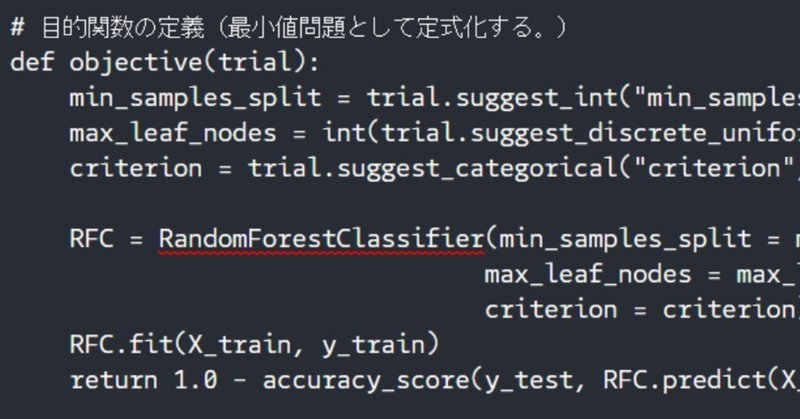
# 目的関数の定義(最小値問題として定式化する。)
from sklearn.ensemble import RandomForestClassifier
from sklearn.metrics import accuracy_score
def objective(trial):
min_samples_split = trial.suggest_int("min_samples_split", 8, 16)
max_leaf_nodes = int(trial.suggest_discrete_uniform("max_leaf_nodes", 4, 64, 4))
criterion = trial.suggest_categorical("criterion", ["gini", "entropy"])
RFC = RandomForestClassifier(min_samples_split = min_samples_split,
max_leaf_nodes = max_leaf_nodes,
criterion = criterion)
RFC.fit(X_train, y_train)
return 1.0 - accuracy_score(y_test, RFC.predict(X_test))あとはstudyインスタンスを建て、optimizeメソッドで最適化を行います。
# ハイパーパラメータの自動最適化
import optuna
study = optuna.create_study()
study.optimize(objective, n_trials = 100)結果は以下のようにして確認できます。
study.best_params # 求めたハイパーパラメータ
1.0 - study.best_value # 正答率4. おわりに
開発者ブログによれば、ハイパーパラメータを求める過程を可視化するダッシュボードを実装中とのこと。とても楽しみですね。Enjoy!
5. 謝辞
ピースオブケイクの加藤さんから、スクリプトのミスについて2点ほどご指摘をいただきとても助かりました。とても感謝しております。ありがとうございます!
サポートをいただいた場合、新たに記事を書く際に勉強する書籍や筆記用具などを買うお金に使おうと思いますm(_ _)m