
投資戦略サーベイのための機械学習手法

1.はじめに
計量的・実証的な投資におけるアルファは質の高いサーベイからもたらされるものであり、近い将来その分析手法の殆どが機械学習に置き換わるものだと考えています。この提言が正しいとすると、現行のシステムトレーダーはすべからく機械学習を学ぶ必要があります。
筆者はこれまでの知見から、投資における機械学習はそれ自体で予測モデルを構築するのではなく、サーベイを効率的・効果的に行うために使うほうが良いと考えています。質の高いサーベイによって一般に知られていないアルファ(アノマリー)を抽出することができれば、実際の予測モデルやトレーディングモデルは条件分岐でも十分事足ります。
本noteでは、投資戦略サーベイのための実践的な機械学習手法について紹介します。
2.関連文献
「Ten Applications of Financial Machine Learning」 Marcos Prado, 2019
機械学習のフィナンシャルデータへの適用事例で最も分かりやすいのは、上記の論文だと思います。この論文では、以下のように10の適用分野が紹介されています。今回のnoteはこのように包括的なまとめではなく、個人投資家向けの実践的な手法について紹介します。
Ten Applications of Financial M/L
(1) Asset Pricing(価格予測)
(2) Risk Management and Portfolio Construction(ポートフォリオ構築)
(3) Outlier Detection(異常検知)
(4) Bet Sizing(ベットサイズ最適化)
(5) Sentiment Analysis(センチメント分析)
(6) Feature Importance(特徴選択)
(7) Credit Rating and Analyst Recommendations(レーティング)
(8) Execution(取引執行)
(9) Big Data Analysis(ビッグデータ分析)
(10) Controlling Effects and Interactions(因果分析)
3.サーベイのための機械学習手法
(1)Feature Importance
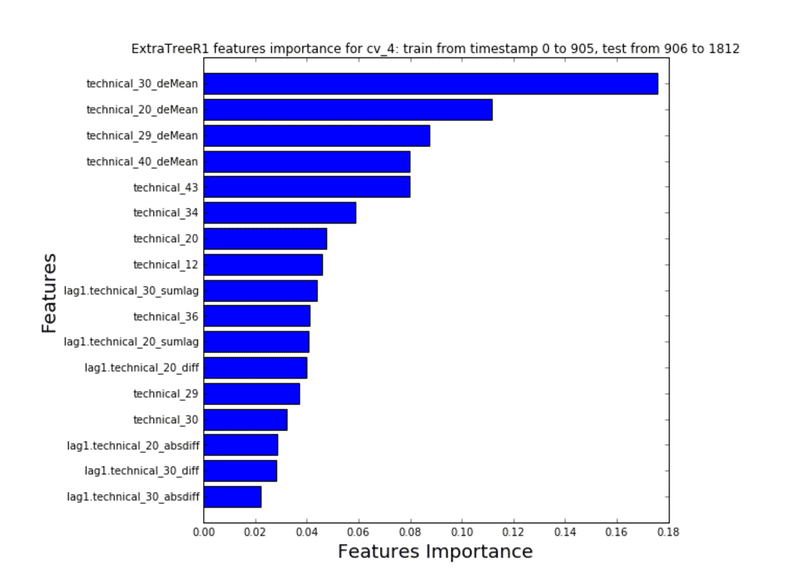
XGBやランダムフォレストなどのツリー系手法を使うことで、どの特徴量の重要度が高いか簡単に評価することができます。論文等のP値による評価に対して優れている点は、交互作用が自動的に考慮される点と、手法中にランダム化が行われている場合には多少なりともバイアスに対する効果があることです。
Feature Importanceは機械学習モデリングにおける基本中の基本の技術ですが、フィナンシャルデータを扱う場合にはサンプリングや前処理に勘所が要求されます(ただし適当に分析してもそれなりの結果が得られることが多いです)。市場構造を正しく理解してサンプリングや前処理を行うことが質の高いサーベイの第一歩となります。
参考事例:Kaggleのコンペティション「Two Sigma Financial Modeling Challenge」の2位入賞者のWinner's Interviewより
(2)LASSO(特徴選択)
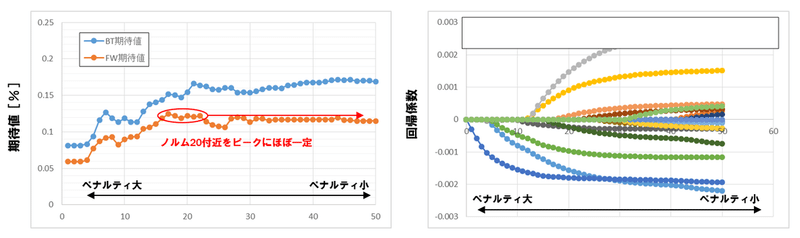
LASSOは線形モデルに正則化(罰則項)を与えたモデルであり、ペナルティを厳しくすることで特徴量を絞り込むことができます(特徴選択)。ツリー系の特徴選択と異なる点は交互作用が考慮されない点ですが、LASSOにはアウトオブサンプルでのパフォーマンス劣化を軽減する効果も報告されており、ツリー系と比べてより実践的な特徴選択技術となる可能性があります。
参考事例:変数選択とリターンの関係(筆者作成)
(3)クラスタリング(階層型)
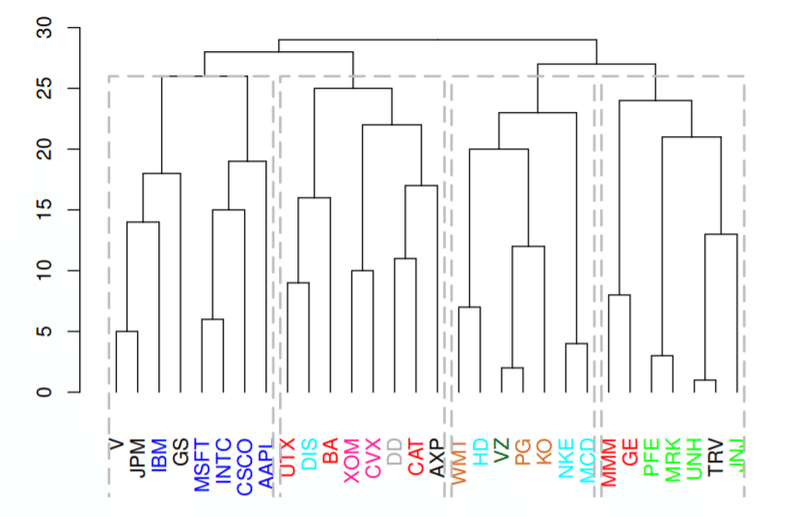
クラスタリングは教師なし学習手法です。目的変数はなく与えられた特徴のみを使ってサンプルを分類します。以下のように階層構造を持つものが代表的です。
クラスタリングの主要目的は、ツリー構造から仲間外れを検出し(通常、同じセクターの銘柄は同じ枝となるはずである)、その要因を追うことで市場構造に対する理解を深めることです。また、このツリー分割から得られたクラスタの平均リターンを予測モデルの目的変数とすることでモデルの分散を低減できる可能性もあります。
参考事例:「Portfolio Construction Using Hierarchical Clustering」より
(4)クラスタリング(マッピング)
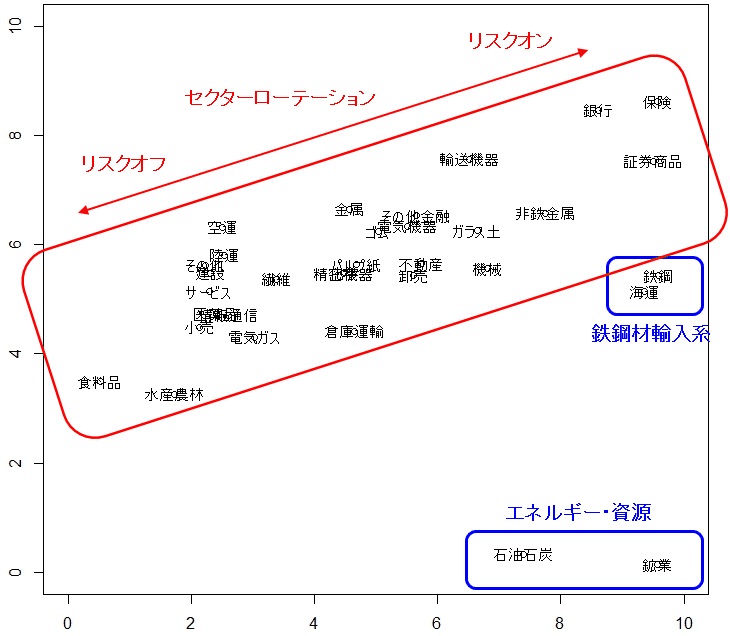
自己組織化マップ(SOM)はニューラルネットを用いて多次元のデータを低次元のデータに次元圧縮し、視覚的に分かりやすくマッピングする手法です。これをファンダメンタル指標や値動きに適用することで、類似度の高い銘柄やセクターをマッピングすることができます。階層型よりもさらに視認性が高く、普段は気付かない市場特性を発見できることがあります。以下の事例では、セクターローテーションに属さないセクターを特定できました。
その他のマッピング手法としてGraphical Lassoなどがあります。
参考事例:株式市場のセクターのマッピング(筆者作成)
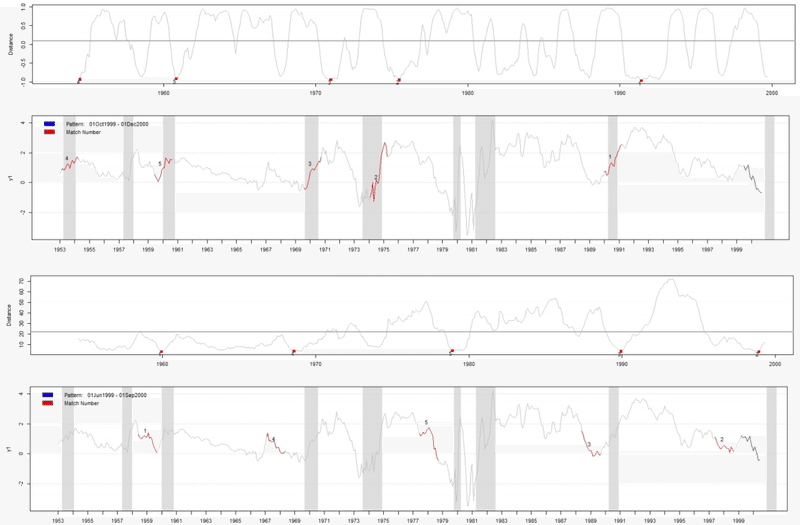
(5)クラスタリング(時系列)
Dynamic Time Warpingは、2つの時系列データ間の距離を求める手法です。これをパターンマッチングの指標としてクラスタリングを行います。例えばこれをインデックスを区間分割して適用した場合、ブル期間やベア期間をデータドリブンな形で分類することができます。これをレジームと考えて各々の期間毎に分析を行うことで、全体では見えなかった市場の特性が見えてくる場合があります。
参考事例:「Predicting US Recessions : A Dynamic Time Warping Exercise in Economics」より
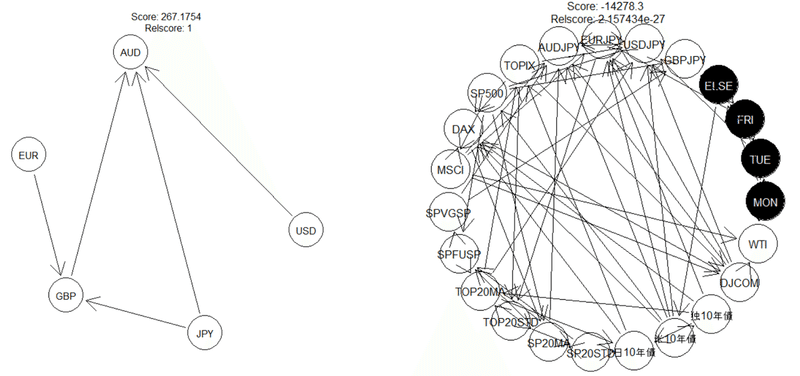
(6)因果分析(Bayesian Network)
ベイズの定理を用いると変数間の因果関係を推定することができます。この分析結果を用いて市場構造の仮説検証を有利に進めることができます。特にベイジアンネットワークは因果関係の確からしさを元に有効非巡回グラフを作ることができ、解釈性の観点からも非常に優れています。
筆者はこの手法を為替に適用して各通貨間の値動きの因果関係をマネーフローとして捉え、通貨の強弱の推定に利用していました。ただしこの手法はあくまでも構造解釈の目的が主であって、リターンに対して直接の予測力を持つとは限りません。あくまでもサーベイのための手法です。
参考事例:為替間のマネーフロー推定、マクロ指標の因果関係推定(筆者作成)
(7)センチメント分析
主に自然言語処理(NLP)を使ってニュースやツイッターなどの媒体を分析し、市場のセンチメントを判断する手法です。この分野はかなり研究が進んでおり、センチメントインデックスを提供しているベンダーも多く見られます。自身で技術開発を行うよりも、ベンダーから仕入れるほうが手っ取り早いかもしれません。
これも時系列クラスタリングと同様に市場のレジームとして分析に活用します。レジーム毎に市場構造が変わることは明白な事実なのです。
4.おわりに
繰り返しになりますが、これらのサーベイ手法の主目的はリターンを直接予測することではなく市場構造に対する解釈の取り掛かりを作ることです。
市場構造の可視化、仮説の設定、特徴選択による判定のプロセスを繰り返して地道にサーベイを進めていくと、その過程においてふと違和感を覚えることがあります。それこそがアルファ発見の第一歩だと考えています。