R言語:tuneパッケージを試してみる。

◆動機
これまでRでパラメーターチューニングをする時にはこちらのautoxgboostを使っていました。
かなり愛用しているのですが、こちらを使っていて困りごとをいくつか感じていました。
・日本語の変数名を受け付けない。
・変数重要度の算出にやたらと時間がかかる。
そんな中、2019/12/07に開催されたJapanRに参加した際にtuneパッケージという存在を知りました。
会場でもtwitterでも割とこのパッケージの存在は知られておらず、私自身も初耳でした。ということで個人的な備忘録を兼ねて色々触ってみたいと思います。
◆インストール
こちらを参考にインストールします。
devtools::install_github("tidymodels/tune")
Error: package or namespace load failed for ‘tune’ in loadNamespace(j <- i[[1L]], c(lib.loc, .libPaths()), versionCheck = vI[[j]]):
名前空間 ‘cli’ 1.1.0 は既にロードされましたが、>= 1.9.9.9000 が要求されています 早速エラーです。
ググると同じようなことで悩んでいる方がいて、解決方法が提示されていました。
cliというパッケージが1.1.0がインストールされているが、必要なのは開発中の1.9.9.9000が必要とのこと。git_hubからこちらをインストールしてtuneを再インストールしたところ、また同じエラー文が。なんとなくPCを再起動したところ、今度は無事にインストールできました。
◆パッケージのもつ関数一覧
library(help="tune")
autoplot.tune_results:Plot search results
collect_predictions :Obtain and format results produced by tuning
control_bayes :Control the Bayesian search process
control_grid :Control the grid search process
example_ames_knn :Example Analysis of Ames Housing Data
expo_decay :Exponential decay function
extract_recipe :Convenience functions to extract model or recipe
finalize_model :Splice final parameters into objects
fit_resamples :Fit multiple models via resampling
last_fit :Fit the best model to the training set
prob_improve :Acquisition function for scoring parameter combinations
show_best :Investigate best tuning parameters
small_fine_foods :Fine Foods example data
tune :A placeholder function for argument values that are to be tuned.
tune_bayes :Bayesian optimization of model parameters.
tune_grid :Model tuning via grid search
◆XGBしてみる
JapanRでのご発表はランダムフォレストでしたが、普段使うXGBで試してみます。ヘッダーが日本語でも問題ないかも確認してみたいと思います。
公式や上記morishitaさんの資料をほぼ写経させていただきました。
library(tidyverse)
library(tidymodels)
library(tune)
library(AmesHousing)
#データの準備
#日本語が可能か1列だけテスト
ames <- make_ames() %>% rename("ガレージの車の数"=Garage_Cars)
#split
set.seed(1)
split<-initial_split(ames,0.7) #70%:30%に分割
ames_train<-training(split)
ames_test<-testing(split)
df_cv=vfold_cv(ames_train,v=3)
#recipe
recipe<-recipe(Sale_Price~.,data=ames_train) ここからモデリング部分です。
XGBするにはboost_tree関数を使います。
今回は木の深さと木の数を探索したいと思います。
#model
model <- boost_tree(mode="regression",
learn_rate = 0.05,
tree_depth=tune(),
trees=tune()
) %>%
set_engine("xgboost")
#tune
params <- list(tree_depth=tree_depth(range=c(5,10)),
trees=trees(range=c(5,50))) %>%
parameters()
XGB_tuned<-tune_bayes(
object = recipe,
model = model,
resamples = df_cv,
param_info = params,
initial = 5,#最初何回か
iter = 50,#最大何回か
metrics = metric_set(rsq),
control = control_bayes(no_improve = 10,verbose = TRUE)#early_stoping的な?
)
x Fold1: model 1/3: Error in xgboost::xgb.DMatrix(x, label = y, missing = NA): 'data' has class 'character' and length 131200.ここでエラー。dataにclass'character'があるのが良くないのかと思い、
とりあえずrecipeの部分を修正したところ一応実行できました。(後日確認)
recipe<-recipe(Sale_Price~.,data=ames_train) %>%
step_dummy(all_nominal()) %>%
prep()#パラメータサーチの可視化
autoplot(XGB_tuned, type = "performance", metric = "rsq")
#bestの結果を保存
best_result <- XGB_tuned %>% show_best("rsq",n_top=3)
best_param <- XGB_tuned %>% select_best("rsq")
best_model <- model %>% update(best_param)
#trainとtestにrecipesを適用
prep_recipe <- recipe %>% prep()
baked_tarin <- prep_recipe %>% juice()
baked_test <- prep_recipe %>% bake(ames_test)
#predict
fitted_model <- best_model %>% fit(Sale_Price~.,data=baked_tarin)
pred_test=predict(fitted_model,baked_test) %>% bind_cols(baked_test)
#結果の可視化
pred_test %>% ggplot(aes(.pred,Sale_Price))+geom_point()
pred_test %>% metrics(Sale_Price,.pred)こちらまでが昨日の内容でした。
この流れで変数の重要度と部分従属プロットを確認したいと思いますが、ここからはtidymodelだけではできなさそうでxgboostやpdpパッケージが必要そうです。
こちらのブログを参考にさせていただき、こちらも写経させていただきました。
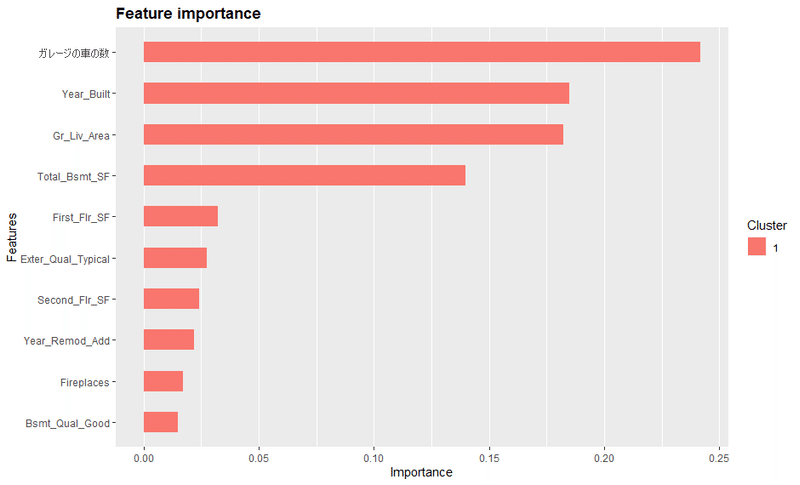
#重要度の可視化
fitted_model$fit %>%
xgboost::xgb.importance(model = .) %>%
xgboost::xgb.ggplot.importance(n_clusters = 1,top_n = 10)#クラスターってなんだ?無事に日本語でも表示されました。時間もかかりません。
#部分従属プロット
pdp::partial(
fitted_model$fit, train = baked_tarin %>% select(-Sale_Price),
pred.var = "ガレージの車の数",
ice = TRUE,
plot = TRUE,
plot.engine = "ggplot"
)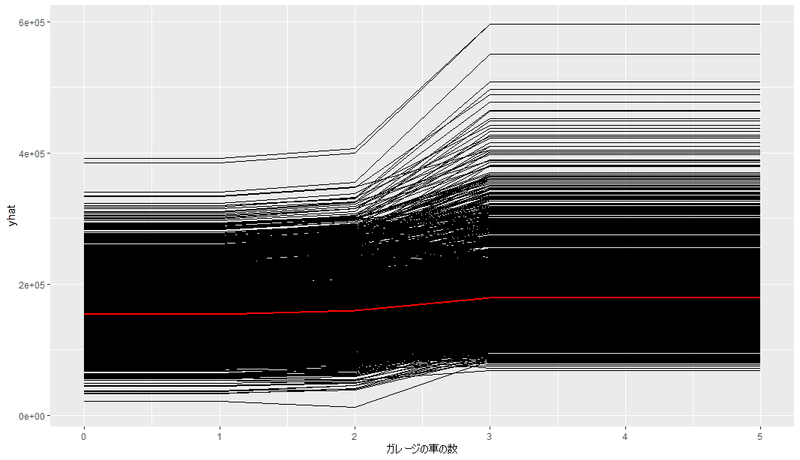
こっちも日本語問題なさそうですね。
◆後回しにした課題
・tuneのところのエラー。factorを受け付けないわけではないと思うので。。。
・tidymodelの枠組みで重要度や部分従属プロットが出せるとスマートなのに、ここだけ他のパッケージ使うのが何とも。以下の関数がありそうな気がしましたが、使い方があまりわからず、これも今度。
この記事が気に入ったらサポートをしてみませんか?