米株プログラミング[2-3](スクレイピング編)

米株プログラミングサークルの皆様!こんにちわトミィ(@toushi_tommy)です!今回は必見、データ解析には必須な「Webスクレイピング」を紹介します。正直、このスクレイピングができれば、なんでもできます。ただし、サイトによってはスクレイピング禁止なものもありますので、気を付けてください。今まで、色んなサイトでデータを見て、自分で記録し、データを整理していたものが、すべて自動でできるのです。今回、コードの説明もしておりますが、ちょっと複雑(特に文字列の変換や取り出し方)なので、理解しなくても良いです。まずは動作から確認しましょう。
サークルは無料で運営しております。記事内容も無料です。トミィにジュースでもおごってあげようと思った方は投げ銭いただけると、今後の運営の励みになります。(最後にジュースいただいた方にプレゼントを用意しました。私がスクレピングしているサイトとコード例です。)
GoogleColabの環境設定がまだの方は、こちらをご覧ください。
Python を使ったWebスクレイピングを説明します。再度説明すると、Webスクレイピングとはインターネットからデータを拾ってくることで、さまざまなデータを人間が見る代わりに取って来る事ができる機能です。普段データを検索する際に様々なサイトを参考にしていると思いますが、これを自動で行い、データを加工し、使いやすいものにします。正直、このWebスクレイピングができれば、どんな情報でも好きに取り出すことが可能になるのです。株分析には必須の機能です。それでは、以下に紹介します。
株データのWebスクレイピング
まず、python でスクレイピングする際には、BeautifulSoupを使います。まず、以下のコードを実行してみてください。
from bs4 import BeautifulSoup
import requests
url = 'https://finance.yahoo.co.jp/'
site = requests.get(url)
data = BeautifulSoup(site.text,'html.parser')
title = data.find('title').get_text()
print(title)
print(data)HTMLが表示されます。これがWebページのソースコードです。このソースコードを加工して、分析しやすく変更します。
スクレイピングしたデータの加工
まずは、Yahooから「米国株の値上がり率ランキング」をスクレイピングしてみましょう。読み取るサイトは以下です。(注意:Yahooファイナンスはスクレイピングを禁止しておりますので、練習としてのみお使いください。)
以下のコードを実行します。
from bs4 import BeautifulSoup
import requests
url = 'https://stocks.finance.yahoo.co.jp/us/ranking/'
site = requests.get(url)
data = BeautifulSoup(site.text,'html.parser')
print(data)たくさんのHTMLが出力されたと思います。取り出したい情報は、
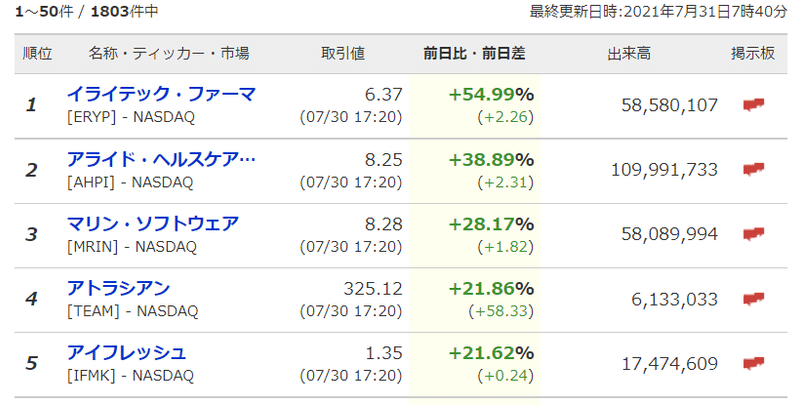
この中の順位、ティッカーコード、取引額、前日比、出来高になります。試しに、出力されたHTMLコードの中から1位のERYPを見つけると、こうなってました。取り出したいのは、以下の太字の部分です。
<tr data-href="/us/detail/ERYP">
<td class="rank textCenter"><span class="rankNum">1</span></td>
<td class="name"><dl><dt><a href="/us/detail/ERYP"><strong>イライテック・ファーマ</strong></a></dt><dd>[ERYP] - NASDAQ</dd></dl></td>
<td class="value textRight"><dl><dt><span>6.37</span></dt><dd>(07/30 17:20)</dd></dl></td>
<td class="ratio textRight isSelected"><dl><dt><strong><span class="greenFin">+54.99</span>%</strong></dt><dd>(<span class="greenFin">+2.26</span>)</dd></dl></td>
<td class="deal textRight">58,580,107</td>
<td class="textream"><a href="https://finance.yahoo.co.jp/cm/rd/finance/ERYP">掲示板</a></td>
参考に、順番を取り出すコードを説明します。たぶん、難しいと思いますので、分からない方は、コード部分まで進んでください。ここで説明するのは、BeautifulSoupのfind_all、replaceを使った置換、re.sub を使った正規表現、for ループの内包表記です。この中で一番複雑なコードの部分を説明します。一番複雑な出来高部分を説明します。(詳細はググって調べてください。)
こちらのサイトも参考にしてください。pythonを使った置換や正規表現に追加書かれてます。
<td class="deal textRight">58,580,107</td>
<td class="textream">
これを取り出すのですが、BeautifulSoupのfind_allで取り出します。
HTMLのtdタグの class="deal textRight"をリストとして取り出す為に、このようなコードになります。
deal = data.find_all("td", class_="deal textRight")
dealの中には、1位から50位までのすべての出来高がリストで取り出されます。こちらを実行してみてください。
from bs4 import BeautifulSoup
import requests
import re
import pandas as pd
# 値上がり率
url = 'https://stocks.finance.yahoo.co.jp/us/ranking/'
site = requests.get(url)
data = BeautifulSoup(site.text,'html.parser')
# 順位
deal = data.find_all("td", class_="deal textRight")
print(deal)
print(type(deal))
print(type(deal[0]))
# 後でコメントを外して実行してください
#print([str(i) for i in deal])
#print([s.replace(',', '') for s in [str(i) for i in deal]])
#print([re.sub('.*>([0-9]+)</.*', r'\1', s) for s in [s.replace(',', '') for s in [str(i) for i in deal]]])
#volume = [int(i) for i in [re.sub('.*>([0-9]+)</.*', r'\1', s) for s in [s.replace(',', '') for s in [str(i) for i in deal]]]]
#print(volume)このような出力になります。(下記図の①、②、③参照)

出来高のリストが表示され、それぞれの型はbs4.element.Tagだと言うことが分かります。replaceコマンドを使う為にリストの中身をstr型に変換します。for文で記載したいのですが、ここでforループの内包表記を使って1行で書くと、[str(i) for i in deal]になります。ちなみに、先ほどのコードの後に、
print([str(i) for i in deal])と入れて実行してみてください。出力がstr型('付の出力)になったことが確認できます。(下記図の④参照)これでもまだ余計なものがあります。まず、取り出す前に出来高は数字ですが、58,580,107とカンマが入っている為、replaceを使って削除してしまいます。それが s.replace(',', '') となります。ここまでをまとめてforで書くと、[s.replace(',', '') for s in [str(i) for i in deal]]になります。
print([s.replace(',', '') for s in [str(i) for i in deal]])で出力すると(下記図の⑤参照)、数字部分から、カンマが無くなったことが分かります。次に、HTMLの余計なタグを消したいので、同様にreplaceを使ってもいいですが、せっかくなので正規表現を使ってみます。(正規表現が分からない方はググってください。)正規表現を使う為にreモジュールのsubを使います。数字を取り出す為の正規表現は、re.sub('.*>([0-9]+)</.*', r'\1', s)になりますので、以下のコードを実行してみてください。
print([re.sub('.*>([0-9]+)</.*', r'\1', s) for s in [s.replace(',', '') for s in [str(i) for i in deal]]])出力をみると(下記図の⑥参照)これでやっと余計な情報が無くなりました。最後にそれぞれの出来高をstr型からint型に変換したいので、追加すると、最終的なコードはこのようになります。
volume = [int(i) for i in [re.sub('.*>([0-9]+)</.*', r'\1', s) for s in [s.replace(',', '') for s in [str(i) for i in deal]]]]
上記⑦でやっと取り出したいリストに変換されたのが分かります。
Yahoo値上がりランキングのコード
同様に、他の部分を取り出した最終コードは以下のようになります。上の説明が分からない場合は、ここから初めていただいて結構です。コードをコピーして実行してみてください。
# Yahoo ランキング [値上がり率]
from bs4 import BeautifulSoup
import requests
import re
import pandas as pd
# 値上がり率
url = 'https://stocks.finance.yahoo.co.jp/us/ranking/'
site = requests.get(url)
data = BeautifulSoup(site.text,'html.parser')
# 順位
num = data.find_all("span", class_="rankNum")
number = [int(i) for i in [re.sub('.*">(.*)</span>.*', r'\1', s) for s in [str(i) for i in num]]]
# ティッカー、銘柄名
name = data.find_all("td", class_="name")
ticker = [re.sub('.*\[(.*)\].*', r'\1', s) for s in [str(i) for i in name]]
jname = [re.sub('.*<strong>(.*)</strong>.*', r'\1', s) for s in [s.replace('&', '&') for s in [str(i) for i in name]]]
# 株価
values = data.find_all("td", class_="value textRight")
value = [float(i) for i in [re.sub('.*<span>(.*)</span>.*', r'\1', s) for s in [str(i) for i in values]]]
# 前日比
ratios = data.find_all("td", class_="ratio textRight isSelected")
ratio = [float(i) for i in [re.sub('.*">([+-]?\d+(?:\.\d+)?)</span>\%.*', r'\1',s) for s in [s.replace('>-<', '>0.00<') for s in [str(i) for i in ratios]]]]
# 出来高
deal = data.find_all("td", class_="deal textRight")
volume = [int(i) for i in [re.sub('.*>([0-9]+)</.*', r'\1', s) for s in [s.replace(',', '') for s in [str(i) for i in deal]]]]
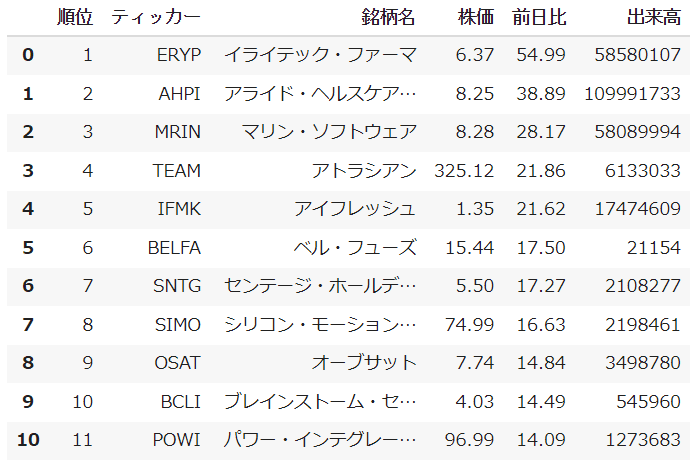
df_data = pd.DataFrame({'順位': number,'ティッカー': ticker,'銘柄名': jname,
'株価': value,'前日比': ratio,'出来高': volume})
df_data実行するとこのような出力になります。
こんな感じで、色んなWebページをスクレイピングできます。コードが難しいと思いますので、ゆっくり後でご確認ください。ググってしらべるか、サークル内で質問してみてください。
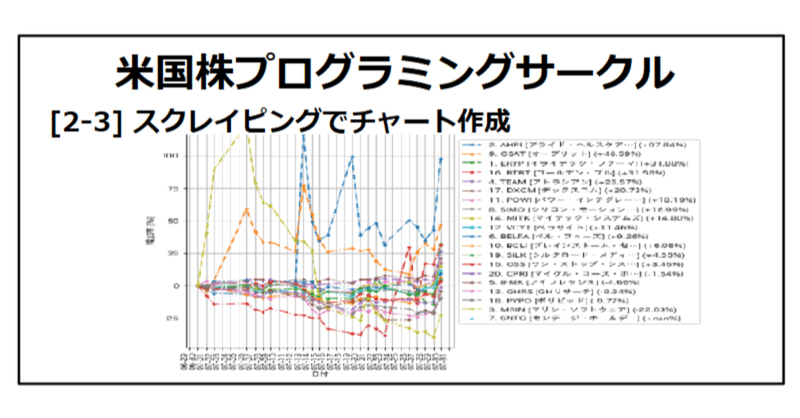
値上がり上位銘柄比較チャート
せっかくなんで、値上がり上位20銘柄の1か月の比較チャートを作ります。note [1-2] で作ったチャートを応用して、作ってみます。[1-2] はこちらです。
コードはこちらです。(スクレイピングは必要なデータだけに絞りました)今回、前回と違って、日本語化しているのと、日付のメモリを毎日つけております。また、1か月の指定も現在から31日前で設定しているので、コードをご確認ください。
import sys
sys.path.append('/content/drive/MyDrive/module')
from bs4 import BeautifulSoup
import requests
import re
import pandas as pd
import datetime as datetime
import matplotlib.pyplot as plt
import matplotlib.dates as mdates
import yahoo_fin.stock_info as si
import numpy as np
import japanize_matplotlib
import warnings
warnings.simplefilter('ignore')
url = 'https://stocks.finance.yahoo.co.jp/us/ranking/'
site = requests.get(url)
data = BeautifulSoup(site.text,'html.parser')
# 順位
num = data.find_all("span", class_="rankNum")
number = [int(i) for i in [re.sub('.*">(.*)</span>.*', r'\1', s) for s in [str(i) for i in num]]]
# ティッカー、銘柄名
name = data.find_all("td", class_="name")
ticker = [re.sub('.*\[(.*)\].*', r'\1', s) for s in [str(i) for i in name]]
jname = [re.sub('.*<strong>(.*)</strong>.*', r'\1', s) for s in [s.replace('&', '&') for s in [str(i) for i in name]]]
df_data = pd.DataFrame({'順位': number,'ティッカー': ticker,'銘柄名': jname}, index = ticker)
# 20銘柄
tickers=ticker[:20]
df = pd.DataFrame()
for i in range(len(tickers)):
try:
data = si.get_data(tickers[i], start_date=(datetime.datetime.now().date()+datetime.timedelta(days=-31)))['adjclose']
df=pd.concat([df, data], axis=1)
df.rename(columns={'adjclose': tickers[i]}, inplace=True)
except:
print("ERROR:", tickers[i])
pass
fig = plt.figure()
ax = fig.add_subplot(111)
df=(df/df.iloc[0]-1)*100
df.sort_values(df.index[-1],axis=1,ascending=False,inplace=True)
# ラベルに上昇率を追加
for i in range(len(df.columns)):
per='%.2f'%((df[df.columns[i]].iloc[-1]))+"%"
per='+'+per if (per[:1]!='-') else per
df.rename(columns={df.columns[i]: str(df_data.loc[df.columns[i],'順位'])+'. '+df.columns[i]+' ['+df_data.loc[df.columns[i],'銘柄名']+'] ('+per+')'}, inplace=True)
df.plot(ax=ax,grid=True,figsize=(5,8),style='.-.').legend(bbox_to_anchor=(1, 0.9))
ax.set_xlabel('日付')
ax.set_ylabel('増加率 [%]')
days = mdates.DayLocator()
daysFmt = mdates.DateFormatter('%m-%d')
ax.xaxis.set_major_locator(days)
ax.xaxis.set_major_formatter(daysFmt)
plt.xticks(rotation=90)
plt.show()こんな出力になりました。

課題
それでは、以下のページをスクレイピングしてみます。値上がりランキングではなく、値下がりランキングを使います。
https://stocks.finance.yahoo.co.jp/us/ranking/?kd=2
実際に必要な情報はティッカーと銘柄名、順位だけです。一度HTMLソースコードを出して見て中身がどの様に書いてあるか解析してみてください。(実は共通コードでデータが取れます)
本日はここまでです。色んなサイトをスクレイピングして見ると良いと思います。
お疲れ様でした。
それではジュースいただいた方にプレゼントです。
私がスクレイピングしているサイトと読み込む為のコードを公開します。サイトの仕様が変わりましたら読めなくなる可能性がありますが、ご自由にお使いください。またスクレイピング禁止サイトの可能性もありますので自己責任でお願いします。
スクレイピングサイト及びコード集
以下現在私が使っているスクレイピングコードです。自己責任でお使いください。仕様が変わって動かない場合は是非ご連絡ください。すぐに変更します。
ここから先は
¥ 150
サポートいただけますと、うれしいです。より良い記事を書く励みになります!