何か有益な仮想通貨投資情報が得られないか、賢者のtwitterをNLP分析してみたら?

もともと医学文献情報のワードクラウドをbotでtwitterに投稿していたのですが、最近フォロワーの方にトピックス分析を加えたら面白いのじゃないだろうかというアドバイスいただきました。
そこでトピックス分析を利用したtwitter分析として一般の方に興味をもっていただけそうな仮想通貨関連の投資に関するテーマを試みました。
仮想通貨といえばアフロ印じゃね?
どのtwitter分析をすれば有用かを考えている際に、Defiといえばアフロ印という仮想通貨界のインフルエンサー方ののtwitterが目にとまりました。
SolanaのDeFi周り、浮かれモードがあるので運用者は必読ですね。人の集まるところに詐欺ありです。
— DEG (@DEG_2020) August 22, 2021
Solana DeFi用護身術 - アフロ印 -|albert #note https://t.co/MAol6GSGof
これは外見から通称アフロ、若干29歳のMIT卒の天才にして富豪サム・バンクマンフリードの率いるFTX、Solana、アラメダリサーチの関わるプロジェクトが軒並みうまくいっていることが多いことを指摘するものです。
中でもFTX、Solanaなどに関わるプロジェクトのうち有望なのは、”アフロ印”と上記ツィッターが呼ぶ、サムからツイッターで絶賛されていたり、サムの関係者の複数からtwitterでフォローされているプロジェクトから推測されるという指摘が面白く
アフロ関係者の範囲の解釈には人それぞれにゆだねられますが、私の中では、Alameda Research関係者(例えばSam Trabucco氏)、Solanaの中核的Developer(例えば、skynet氏)、S級以上のアフロ印を獲得したプロジェクトの公式アカウント(例えば、RaydiumやMango Market)が含まれています。
twitter分析してみる価値を感じました。
そこでサム氏
Solanaのエンジニアskynet氏
solanaのco-founder rajgokal氏
の3人のtweetを分析をしてみました。
以下コードの説明を行います。
Pythonコード:Twitter分析部分
まずプログラミングの前にtwitter development accountを申請し、CONSUMER_KEY, CONSUMER_SECRET, ACCESS_TOKEN, ACCESS_TOKEN_SECRETを入手してください。
入手には数時間から数日時間がかかるとおもいます。詳しくは以下のブログです。
次に本体のプログラミングを順を追ってみていきます。
ライブラリのimport
# -*- coding: utf-8 -*-
import tweepy
import csv
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
from wordcloud import WordCloud
from datetime import *
import ostwitter APIを利用したのインスタンスの作成(おまじない的に)
CONSUMER_KEY = "XXXX"# ご自身で取得してください
CONSUMER_SECRET="YYYY"# ご自身で取得してください
ACCESS_TOKEN = "ZZZZ # ご自身で取得してください
ACCESS_TOKEN_SECRET = "AAAA" # ご自身で取得してください
#上記キー、トークンをつかいAPIインスタンスを作成します。
auth = tweepy.OAuthHandler(CONSUMER_KEY, CONSUMER_SECRET)
auth.set_access_token(ACCESS_TOKEN, ACCESS_TOKEN_SECRET)
api = tweepy.API(auth)twitter情報の取得
ここでは情報を取得するアカウントを定義したのち、それぞれのアカウントについてリプは除く、最大限(直近半年分)のtweet抽出し、それぞれのtweetから、id, tweet時間, 本文, いいねの回数、RTの回数といった情報をdfというデータファイルに格納します。
# 情報を取得するアカウントの定義
solana = ["@SBF_FTX", "@skynetcap", "@rajgokal"]
#ツイート取得
tweet_data = []
for account in solana:
for tweet in tweepy.Cursor(api.user_timeline,screen_name = account,exclude_replies = True).items():
tweet_data.append([tweet.id,tweet.created_at,tweet.text.replace('\n',''),tweet.favorite_count,tweet.retweet_count])
df = pd.DataFrame(tweet_data,columns=["id","created_at","text","fav","RT"])次に本文の情報から、”,”, "FTX", "Solana”,RT”, ”http:"など情報量の少ない要素を除いて、一つの文字列オブジェクト、text, もしくはtweetごとの本文の情報からなるlist, texに格納します。
text = ""
tex=[]
for i in range(len(df)):
abs=df["text"][i].rsplit("https",1)[0].replace(",","").replace("FTX","").replace("SBF","").replace("Alameda","").replace("_Official","").replace("RT","").replace("solana","").replace("Solana","").replace("https://t.co/","").replace("\n","")
text = text + abs
tex = tex + [abs]textを表示させると
text
texを表示させると
tex
のようになります。
Wordcloudの作成
これはtextオブジェクトとwordcloudライブラリを用いて簡単に
wordcloud = WordCloud(background_color="white",
width=800,height=600).generate(text)とつくることができ、
表示させてみると
plt.imshow(wordcloud)
plt.show()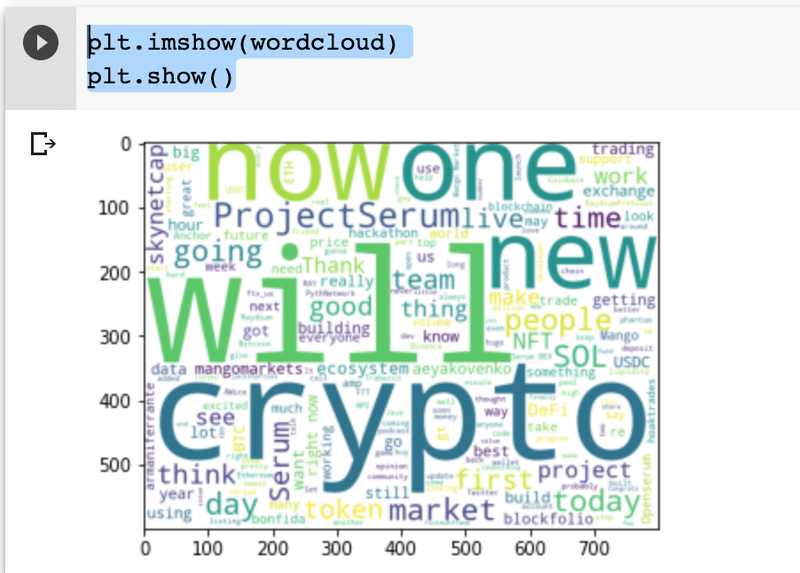
このようなwordcloudがえられます。
twitterへの投稿
これは、いったん現在のディレクトリ内に画像を書き込むtest.pngファイルをつくったのち、twitter APIを利用して、画像付き、日付いりコメントで投稿します。
投稿はupdate機能により、また投稿が終わるとtest.pngファイルは消します。
now = datetime.today() - timedelta(0,60)
ti = str(now.year) + u"年" + str(now.month) + u"月" + str(now.day) + u"日: "
content = ti+"solana関係者 をテキストマイニングしてみました。\n"
filename = "./test.png"
wordcloud.to_file(filename)
api.update_with_media(filename, status = content)
os.remove(filename)すると以下のような投稿ができます。
word cloudによる運用
2021年8月27日: solana関係者 をテキストマイニングしてみました。 pic.twitter.com/7QqB2HiJ44
— Toshi@MD,PhD 🇺🇸 (@tokitky) August 27, 2021
Pythonコード:LDA分析編
つぎに上記でえられたtexオブジェクトを用いてトピックス分析してみます。ここでやることは機械学習ライブラリ一つ、scikit-learnライブラリをもちいて、テキスト情報をトークン化して、そのトークンごとの頻度を数えたのち、LDAという仕組みによってトピックスごとに分類する作業を行います。
トークン化についての詳細は次のブログをご覧ください。
トークン化がおわると、pyLDAvisというライブラリによってLDAによる分析を可視化する作業を行い、その内容を目で見て確認できるようにします。
import部分
from sklearn.feature_extraction.text import CountVectorizer, TfidfVectorizer
from sklearn.decomposition import LatentDirichletAllocation
import pyLDAvis
import pyLDAvis.sklearnトークン化、LDA、visualizationの関数定義部分
トークン化はCountVectorizerとTfidfVectorizerの二つがあります。TfidfVectorizerの方がnormalizeされたcounting手法のようなのでより正確なのかもしれませんが、基本的には同じような結果になります。
The TfidfTransformer transforms a count matrix to a normalized tf or tf-idf representation. So although both the CountVectorizer and TfidfTransformer (with use_idf=False) produce term frequencies, TfidfTransformer is normalizing the count.
またpyLDAvisについては
が詳しいです。
実際の関数定義のコードは次のとおり
def create_lda_vis(docs_raw):
docs_raw # list of text
tf_vectorizer = CountVectorizer(strip_accents = 'unicode',
stop_words = 'english',
lowercase = True,
token_pattern = r'\b[a-zA-Z]{3,}\b',
max_df = 0.5,
min_df = 10)
# TF(word count)
dtm_tf = tf_vectorizer.fit_transform(docs_raw)
print(dtm_tf.shape)
# TFIDF (normalized word count)
tfidf_vectorizer = TfidfVectorizer(**tf_vectorizer.get_params())
dtm_tfidf = tfidf_vectorizer.fit_transform(docs_raw)
print(dtm_tfidf.shape)
# LDA for TF(word count)
lda_tf = LatentDirichletAllocation(n_components=20, random_state=0)
lda_tf.fit(dtm_tf)
# LDA for TFIDF (normalized word count)
lda_tfidf = LatentDirichletAllocation(n_components=20, random_state=0)
lda_tfidf.fit(dtm_tfidf)
# visualization to html
pyLDAvis.save_html(pyLDAvis.sklearn.prepare(lda_tf, dtm_tf, tf_vectorizer), "test_lda_solana_tf.html")
pyLDAvis.save_html(pyLDAvis.sklearn.prepare(lda_tfidf, dtm_tfidf, tfidf_vectorizer), "test_lda_solana_tfidf.html")実際の解析
うえで定義した関数にtexオブジェクトを渡してあげることで完成です。
create_lda_vis(tex)
ここまでくると、現在のディレクトリにtest_lda_solana_tf.html, test_lda_solana_tfidf.htmlができているとおもいます。
一つ目がノーマライズなし、二つ目がノーマライズありのデータになります。それぞれファイルはchromeなどのブラウザで開くことができインタラクティブに利用することができます。
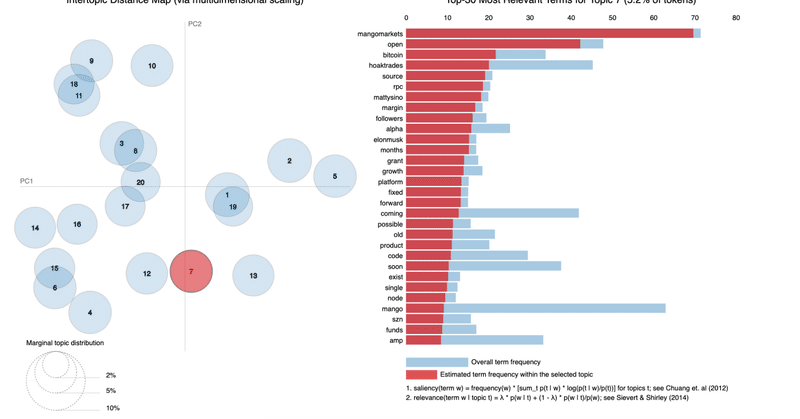
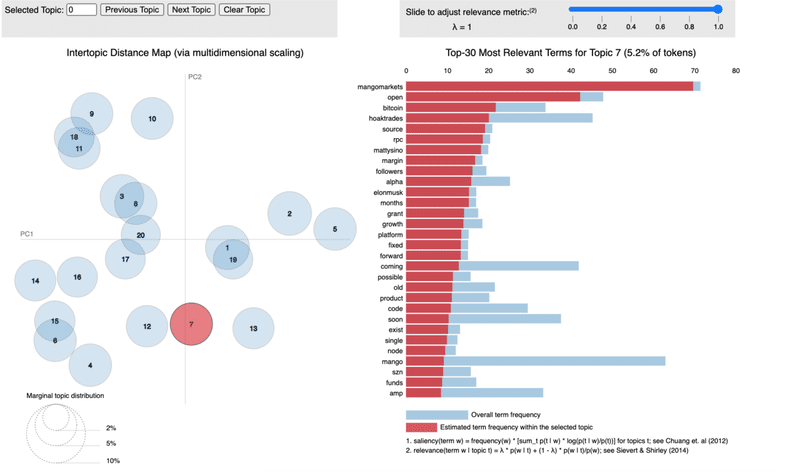
一つ目データの例
実際のファイルはリンクをクリックしていただくとご覧になれます。
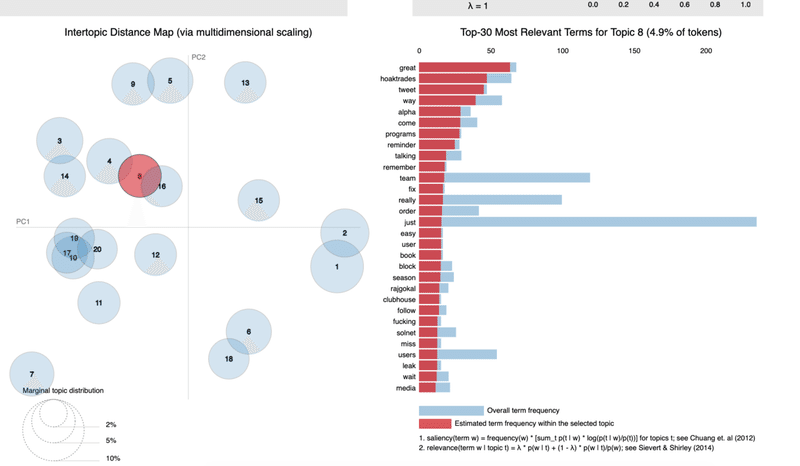
二つ目のデータの例
実際のファイルは次のリンクをクリックしていただくとご覧になれます。
結局何がわかったのか
1. まずsolana関連のプロジェクトに関するキーワードが得られたこと
bonfida, pythnetwork, metaplex, mango, Mercurial Fi
などですね。
2. 次にsolana関連グループの重要人物がさらにリストアップできたこと
3. 最後に意味深なトピックスとして、精査が必要なものがあったこと
solana関係者のtweetのNLP
— Toshi@MD,PhD 🇺🇸 (@tokitky) August 26, 2021
ちなみにこのトピックスきになるなあ笑笑
huge alpha leak....???#Solana #Python #NLP https://t.co/zUNE64F7CX pic.twitter.com/a28cGqQzQq
このトピックスはツイートのようにalpha, leak,great, hugeなどの用語が含まれ、何らかの興味深い情報が含まれていた可能性がありました。
上記ツィートの情報は今回上でシェアしたトピックスとは異なるのですが、おそらく一つ目のデータのトピックス8 、二つ目のデーターのトピックス7がそれに当たるものと思われます。
なお情報をとるアカウントの数を増やしたり、telegramなどのメディアでも同様のことをやってみると非常に興味深いともいます。このnoteを参考にいろいろと試していただければ幸いです。
またなにかございましたら、コメント頂けると幸いです。
この記事が気に入ったらサポートをしてみませんか?