
非エンジニアがGoogle Analytics 4とBigQueryを使って3時間でSQLをマスターする(クエリサンプル、練習問題付き) ※2022年1月22日再編集

※前置きはいいから早く本題へ!という方は「事前準備」まで飛ばしてください。
以前こんなツイートをしました。
優秀なインターン生にSQL ZOOだけぶん投げたらほんとに1日でSQL書けるようになった。多少手直しは必要だけど。ほんとにこの記事の通り。https://t.co/yh872H6KrY
— Takahiro Ishiwata / 石渡貴大 (@takahirostone) March 3, 2020
このツイートは非常に反響が大きく、非エンジニアのSQL学習欲を改めて感じました。
私はもともとマーケターでSQLは書けなかったのですが、前職のGunosyでは全社員が誰でもSQLを書いて分析できる環境が整っていましたし、データ分析部の方が優しく教えてくれたおかげでSQLが書けるようになりました。
ただ、そういう環境が自社に整っていないとなかなかSQLを覚えることは難しいのではないでしょうか。かと言って自分で環境構築をするにはサーバーやデータベースの知識が必要になるのでかなり手間と時間がかかってしまいます。
また、このツイートで紹介した「SQL ZOO」を使う方法は確かに環境構築が不要というメリットはあるのですが、用意されているデータセットは汎用的なもので、自社の分析に即使えるものではありません。
このnoteではそういった事情でSQLをマスターするのを諦めている方々に向けて、Google Analytics 4(GA4)とBigQuery(BQ)を使って簡単に環境を構築し、SQLをマスターするステップをご紹介します。
※最初の記事公開時はまだGA4が出たばかりの頃でしたが、1年ほど経って少しクエリの書き方が変わったのと、Google公式のサンプルデータセットなども出ているので2022年1月22日に再編集しました。
書いている人
株式会社マインディアというマーケティングテクノロジーを扱う会社でBtoC・BtoB両方のマーケティングをしています。
非エンジニアなので用語の説明やクエリの書き方など雑なところがあると思いますが、何か気になるところがあったら優しくご指摘くださいw
twitterアカウント @takahirostone
ぜひフォローしてくださいー!
このnoteのゴール
このnoteではコンバージョンしたユーザーがコンバージョン前にどのページを見ていたかを確認するためのクエリが書けるように話を進めていきます。その過程でSQLの基本的な文法や構造を学ぶことができます。
順調にいけば2〜3時間程度でこんなクエリの意味が分かり、自分でも書けるようになると思います。
CREATE TEMPORARY FUNCTION getDate() AS (FORMAT_DATE('%G%m%d', DATE_SUB(CURRENT_DATE('Asia/Tokyo'), INTERVAL 1 DAY)));
WITH
cv_sessions AS (
SELECT
value.int_value AS ga_session_id
FROM
`aaaaaaaaaaaaaa.analytics_xxxxxxxxx.events_*`
,UNNEST (event_params) AS event
WHERE
_table_suffix = getDate()
AND event_name = 'inquiry'
AND key = 'ga_session_id'
)
,sessions AS (
SELECT
value.int_value AS ga_session_id
,event_bundle_sequence_id
FROM
`aaaaaaaaaaaaaa.analytics_xxxxxxxxx.events_*`
,UNNEST (event_params) AS event
WHERE
_table_suffix = getDate()
AND event_name = 'page_view'
AND key = 'ga_session_id'
)
,events AS (
SELECT
event_bundle_sequence_id
,value.string_value AS page_url
,FORMAT_TIMESTAMP('%F %T', DATETIME(TIMESTAMP_MICROS(event_timestamp), 'Asia/Tokyo')) AS datetime
FROM
`aaaaaaaaaaaaaa.analytics_xxxxxxxxx.events_*`
,UNNEST (event_params) AS event
WHERE
_table_suffix = getDate()
AND event_name = 'page_view'
AND key = 'page_location'
)
SELECT
cv_sessions.ga_session_id
,events.datetime
,events.page_url
FROM
cv_sessions
JOIN
sessions
ON cv_sessions.ga_session_id = sessions.ga_session_id
JOIN
events
ON sessions.event_bundle_sequence_id = events.event_bundle_sequence_id
ORDER BY
2これが書けるようになったからと言って「SQLマスターした!」というのはもちろん言い過ぎです。でも、この内容が理解できるようになれば自分で書く際につまずいてもググれば何とかなる、というレベルには到達しているはずです。
なぜGA4+BQを使うのか
① 環境構築にサーバーサイドの知識など難しいことが必要ない
SQLが書けるようになるには実際にクエリをたくさん書くのが手っ取り早いですが、自社で非エンジニアが自由にクエリを叩ける環境がない場合はその環境を作るのが大変です。サーバーサイドのことから勉強を始めるとなるとそれだけで諦めてしまいたくなります。私もサーバーのことは全くわかりません。
一方でBigQueryはGoogle Cloud Platformからアカウントを作成していくだけで使えますし、GAの設定は慣れている方も多いと思います。連携も非常に簡単なので、手軽にクエリを叩く環境を整えることができます。
② 最初から実践的なクエリを学べる
SQLの練習サイトなどもありますが、使えるデータはあくまでも練習用のものです。
その点、GAのデータを使えば自社サイトのデータが入っているので身近なデータを使いながらすぐに実践できるクエリを学ぶことができます。また、GA4ではスクロール、クリック、セッションのスタートなど、さまざまなイベントを自動で収集してくれるため、特別な設定をせずにイベントのデータ取得が可能になります。
もし今は自分が自由に使えるGA環境がないという方でも、Googleが用意しているGA4のサンプルデータセットを使うことができます。もちろん自分でGAをセットアップしたときとほぼ同様のデータセットを使うことができます。
③ 答え合わせができる
GAは管理画面があります。そのため、クエリを書いて出した結果が正しいのかどうかすぐに答え合わせができます。もちろん管理画面で見れるデータだけなら最初から管理画面で見ればいいのでSQLを書いて抽出する必要はないですが、練習段階で答え合わせをしながらクエリを書けるのは非常に重要です。
直接DBからデータを抽出するだけでは、その結果が正しいのかどうか分からず、誰かに確かめてもらう必要があります。
④ (小規模なら)費用がかからない
旧GAは有料版でしかBQとの連携ができなかったのですが、GA4から無料で行えるようになりました。GAもBQも、ある程度の規模までは無料で使えるようになっています。
この記事で想定している対象者
GA(旧GAでもGA4でもどちらでも)に関する基本的な知識があり、これからSQLを書けるようになりたいという方を想定しています。
GAの用語や設定方法の説明などはこの記事ではしませんので、まだGAを触ったことがない方はまずは管理画面で触るところから始めてください。
事前準備
① GA4の導入
サイトに旧GA(Universal Analytics)しか入れていない場合はGA4を導入しましょう。GA4の導入は簡単で、GA管理画面の「管理」→「プロパティを作成」もしくは「GA4 Setup Assistant」から進んでください。分からない箇所があったらググればたくさん記事があります。
また、コンバージョンも設定しましょう。コンバージョン設定は旧GAとの違いが大きく戸惑うかもしれませんが、こちらの記事などを参考に進めてみてください。
② BigQueryの準備
Google Cloud Platformのプロジェクトを作成する必要があります。こちらの記事のステップ1などを参考にやってみてください。
また、この記事のステップ2の手順で進むと実際にクエリを書く画面に行けます。メニューが見つからない場合は上部の検索窓で「bigquery」と検索しましょう。まだクエリは書きませんが、設定でSQL言語が「レガシー」になっている場合は「標準」にしておいてください。方法はこちらの記事にあります(「なお、設定でデフォルト挙動のSQLとしてどちらを使うかは切替可能です。」という部分に記載があります)。
ちなみにですが、ひとくちにSQLと言っても実は種類がいくつかあり、基本は一緒なのですが細かい関数など異なる部分もあります。今回はBigQueryで使える標準SQLに則って書き方をご紹介していきます。
※会社によってはすでにGCPのアカウントがあったりプロジェクトがあったりすると思います。分からなければ管理してそうなエンジニアの方などに聞いてください。
③ GA4とBigQueryの接続
GA4とBQの接続はこちらの記事が詳しいです。プロジェクトの選択のところで、②で作ったプロジェクトが出てくるはずです。
「頻度」は基本は「毎日」をおすすめします。「毎日」は1日1回まとめてBQにデータが送信されます。「ストリーミング」を選択するとリアルタイムでデータが送信されるので便利なのですが、別途費用がかかります。費用がかかることを理解した上でリアルタイムに分析したいという方以外は「毎日」で良いです。
(参考)BigQueryの料金
(2023年3月30日追記)
BigQueryより料金体系の変更が発表になっています。
https://cloud.google.com/blog/products/data-analytics/introducing-new-bigquery-pricing-editions?hl=en
詳細が判明したら再度編集する予定ですが、以下の内容は以前の内容だという前提でご覧ください。
「なぜGA4+BQを使うのか」の章で記載した通り、小規模なら無料で使えます。 ※料金表はこちら
無料で使用できる範囲は「ストレージ10GBまで、クエリは毎月1TBまで」です。
「ストレージ」として計算されるのはGAから送信されて蓄積していくデータです。私が利用している1日に50セッション程度のサイトの場合は1日150KB前後が溜まっていきます。10GBになるには6万日以上かかりますね。安心です。
GA・BQの連携では日別でデータが分かれていて、この画像のところから日別のデータ量を見ることができます。
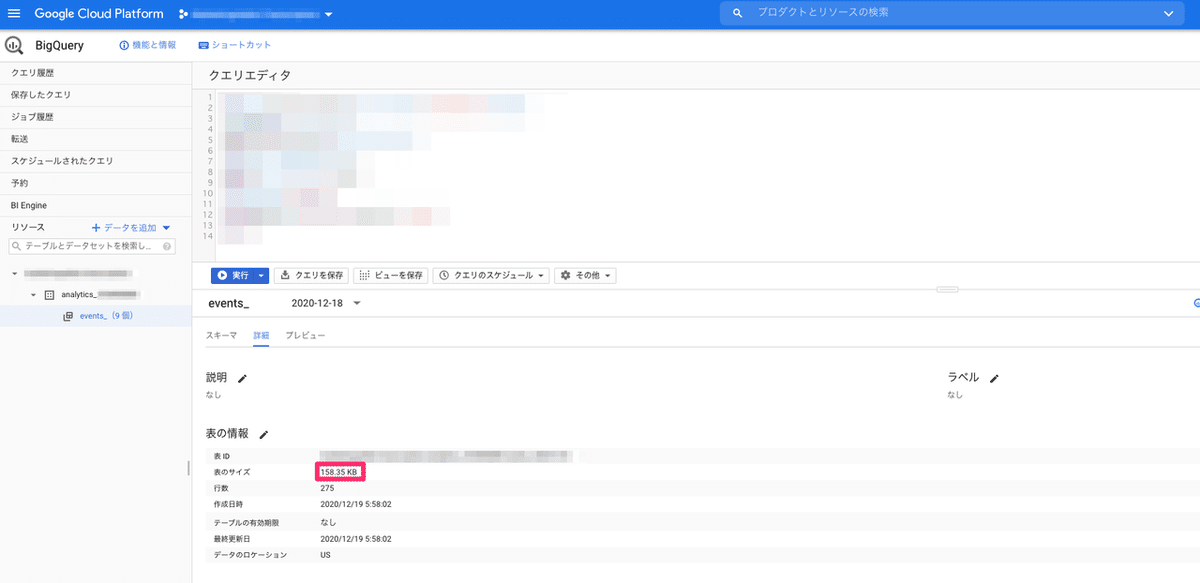
「クエリ」として計算されるのははSQLを書いてデータを抽出する際にかかったバイト数です。つまり、データ抽出の際は都度かかります。最小単位は10MBなので、1回クエリを叩くと最低で10MB消費します。上記のサイトでイベント抽出などを行うクエリは毎回10MBに収まっています(実際には100KBほど)。1TBを使い切るには1ヶ月で10万回ですね。安心です。
実際に自分がクエリを叩いたあとにかかったバイト数を見ることもできます(上が実際の処理にかかったバイト数で、下が課金対象のバイト数。この例では最小単位の10MBを下回っているため、10MBがカウントされます)。

このように小規模サイトの例ならほとんど何も気にしなくて無料で扱えるはずです。大規模なサイトを扱う方はこの方法やこの方法を駆使して費用を抑えてください。また、BQはあくまでも練習用と割り切って、数日分のデータを取り込んだらGAとの連携を切ってしまえばストレージとクエリのバイト数を抑えることができます。
ここでご紹介したバイト数や料金はあくまでも一例です。ご利用の際はご自身で料金表や自分の利用状況を見て、料金を調べながらお使いください。
SQLを書き始める前の基礎知識
SQLは、データベースを扱うための言語です。データを挿入したり、削除したり、検索したりするために使います。マーケターなど非エンジニアがデータ挿入・削除などを扱うことはほぼないと思うので、このnoteでは検索に絞った話をしていきます。
データベースは、Excelの表のようなものをイメージすると分かりやすいかなと思います。こんな感じです。 ※実際のGAのデータではありません。

表のことをテーブル、行(横)のことをレコード、列(縦)のことをカラムと呼びます。
このテーブルはユーザーの行動のデータになっていて、カラムが4つあります。「id」「created_at」「user_id」「event_name」の4つで、それぞれ「レコードの連番」「いつ」「誰が」「何をしたか」が記録されています。レコードは5つです。
この表の場合はカラムもレコードも少ないので集計しなくても見ただけで分かりますが、もっと大きなテーブルから必要なデータを抽出し、場合によっては複数のテーブルを組み合わせ、加工し、見やすくするためにSQLが必要になります。
クエリの書き方
BQでは上にある大きなボックスでクエリを書いていきます。

書いて「実行」を押すと下に結果が表示されます。
SELECT、FROM、LIMIT
まず覚えるのがSELECT、FROM、LIMITの3つです。
SELECT
*
FROM
`aaaaaaaaaaaaaa.analytics_xxxxxxxxx.events_*`
LIMIT
10◆ FROM
FROMはどのテーブルを参照するかを指定します。「aaaaaaaaaaaaaa」の部分はプロジェクト名が、「xxxxxxxxx」の部分はGAのプロパティIDが入ります。BQ画面の左側にも表示されています。

「*」は全て選択、ということです。BQは日別にデータ分かれていますので、1つ1つのテーブル名は「aaaaaaaaaaaaaa.analytics_xxxxxxxxx.events_20201210」「aaaaaaaaaaaaaa.analytics_xxxxxxxxx.events_20201211」のようになっています。これらを全てまとめて選択する場合に「*」を使用します。
1つ1つ個別に選択する場合は前後の「`」がなくても大丈夫ですが、「*」を使う場合は「`」をつけないとエラーになります。
◆ SELECT
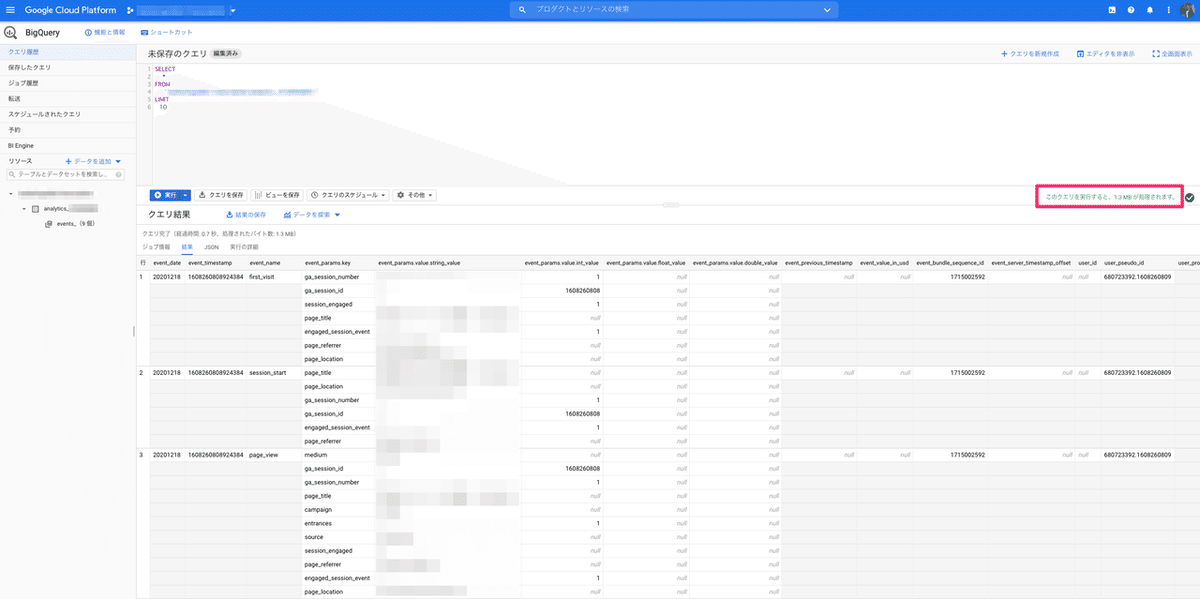
SELECTは、FROMで選んだテーブルの中から抽出するカラムを選択します。「*」はFROMのときと同じく全選択なので、全てのカラムを選択していることになります。特定のカラムのみを選択する場合は「event_date」のようにカラム名をそのまま記載します。「,」(半角カンマ)で区切ることで複数のカラムを選択できます。
※大規模なサイトの場合は「*」を使うと扱うデータ量が多くなり、クエリに必要なバイト数が跳ね上がる可能性がありますので、抽出するカラム名を指定するようにしてください。クエリを書いたあと、ボックスの右下に「このクエリを実行すると、1.3 MB が処理されます。」というような表示が出ますので、実行前に参考にしてください。
◆ LIMIT
結果として表示する件数を指定します。ここでは「10」としているので、10件分表示されます。結果に表示されるレコード数が多い場合は「LIMIT」をつけないと表示に非常に時間がかかることがあるので注意してください。※BQではなく自社DBを使ってSQLを書くとき、うっかりLIMITをつけ忘れてエンジニアにめちゃくちゃ怒られることがあります。例えば、月間100万PVのサイトのpage_viewログを分析しようと思うと、1ヶ月分のデータだけで100万行です。気をつけましょう。
このクエリを実行するとこうなります。
画面サイズの関係で一部しか表示されていませんが、このようなテーブルが表示されれば成功です。
まずはこのLIMITを1000などある程度大きな数にして、どんなカラムがあるのか、どんなイベントが計測されているのかを眺めてみましょう。管理画面からGAを触っている方であればある程度イベントの意味は理解できると思います。
一部のカラムのみを選択する場合はこのように書きます。
SELECT
event_date,
event_name,
event_params
FROM
`aaaaaaaaaaaaaa.analytics_xxxxxxxxx.events_*`
LIMIT
10SQLの書式や書き方の作法はいろいろ流派があるので細かい部分は好きなように書けば良いと思いますが、SELECTやFROMなどの中に記載する要素はtabキーを使ってインデントをしておくのがおすすめです。そうしないと自分が後から振り返って見るときや他人に共有するときに見づらいクエリになってしまいます。
ちなみに、基本的に全角を使うことはありません。記号やスペースなどが全角で入ってしまうとエラーになるので気をつけましょう。
WHERE
WHEREはデータの抽出条件を絞るためのものです。LIMITはテーブル全体の中から10件を抽出するというだけで、抽出するための条件を絞ることはできません。WHEREを使うと、例えば「page_viewのイベントが発生したときのみを抽出する」などの操作が可能です。
SELECT
event_date,
event_name,
event_params
FROM
`aaaaaaaaaaaaaa.analytics_xxxxxxxxx.events_*`
WHERE
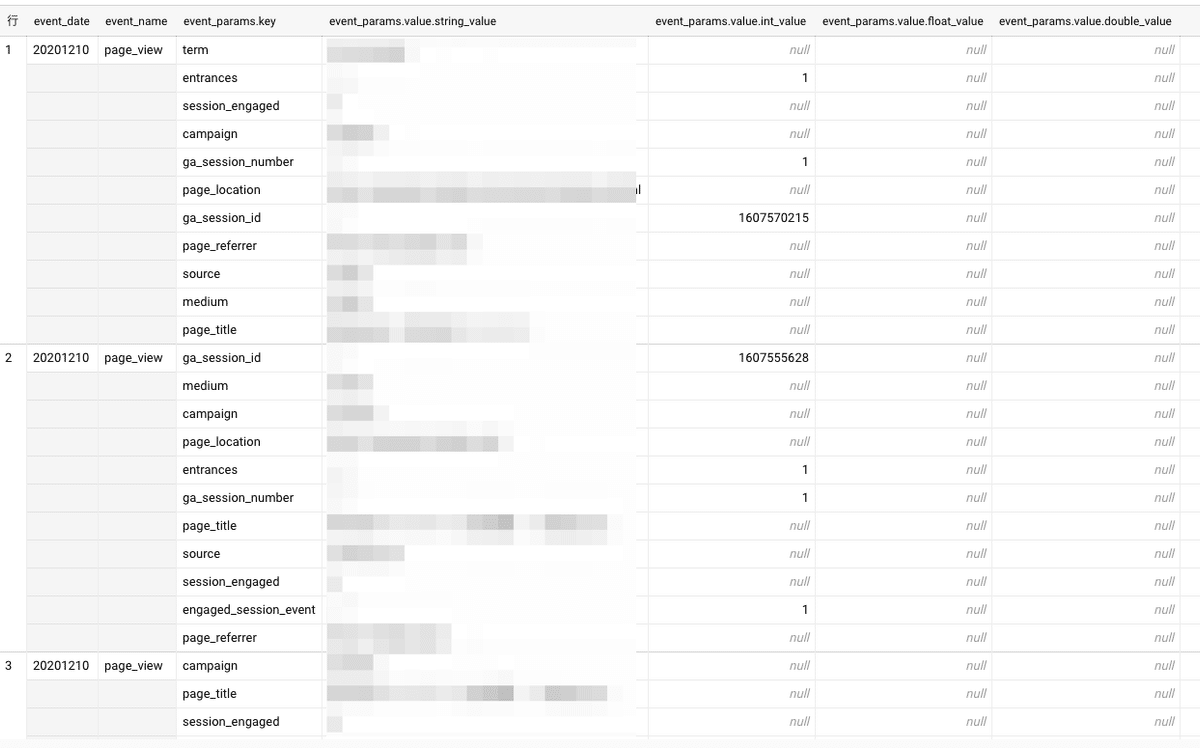
event_name = 'page_view'「page_view」のイベントというのは「event_name」のカラムが「page_view」という値になっているものです。なので「event_name = 'page_view'」として指定します。値は「'」(クォーテーション)で囲みます。
実行するとこのように、「event_name」が「page_view」のものだけが得られます。
また、値の比較に使えるのは「=」だけではなく、いろいろなものが使えます。
column = 'page_view' /*columnがpage_viewと等しい*/
column != 'page_view' /*columnがpage_viewとは異なる*/
column >= '20201211' /*columnが20201211以上。もちろん「>」「<=」「<」も使えます*/集計でよく使う関数、演算子
SELECT句やWHERE句の中では、カラムの値をそのまま表示するのではなく計算したり集計したり書き換えたりして操作することがあります。例えば、全件のローデータを表示するのではなく全体の件数が何件か知りたい、などです。
COUNT(column) /*columnの件数を数える*/
COUNT(DISTINCT column) /*重複したものは1件とし、columnの件数を数える*/
SUM(column) /*columnの数値を合計する*/
+ /*足し算*/
- /*引き算*/
* /*掛け算*/
/ /*割り算*/例えばevent_nameのデータ件数を数える、という場合はこのようになります。
SELECT
COUNT(event_name)
FROM
`aaaaaaaaaaaaaa.analytics_xxxxxxxxx.events_*`複数を組み合わせることもできますので、countで件数を数えたあとに割り算をしてCVRを出す、というようなこともできます。
時間処理の関数
GA・BQではイベントの発生時刻が「event_timestamp」のカラムに記録されています。ただし表示の形式が「1970-01-01 00:00:00 UTC からのマイクロ秒数」になっているため「1608031001282339」というような表記になっています。これではぱっと見ただけで何月何日か分からないですよね。そのため、見て分かるように変換します。
DATETIME(TIMESTAMP_MICROS(event_timestamp), 'Asia/Tokyo')これは「event_timestampをマイクロ秒形式のタイムスタンプとして扱い、それを日本時間に変換する」という処理を行っています。こうすると「2020-12-15T20:16:41.282339」というような形になります。実際の分析でマイクロ秒まで必要になることはほぼないので、適切なところで切ります。
DATETIME_TRUNC(DATETIME(TIMESTAMP_MICROS(event_timestamp), 'Asia/Tokyo'), DAY) /*日までで切ります。*/
DATETIME_TRUNC(DATETIME(TIMESTAMP_MICROS(event_timestamp), 'Asia/Tokyo'), SECOND) /*秒までで切ります。*/すると「2020-12-15T00:00:00」や「2020-12-15T20:16:41」のように、処理しやすいところまでで切ることができます。
例えば「2020/12/15」のような形式にしたいなど、もっと自由な形式で扱いたいという方はこちらが参考になります。
GROUP BY、ORDER BY
COUNTやSUMを使って集計をする際、全体の集計だけでなく日別の集計をしたい、ということがよくあると思います。そういったときに使うのがGROUP BYです。
SELECT
event_date, /*event_dateのカラム*/
COUNT(event_name) AS pv /*event_nameのカラムのデータ件数を数える*/
FROM
`aaaaaaaaaaaaaa.analytics_xxxxxxxxx.events_*`
WHERE
event_name = 'page_view' /*event_nameがpage_viewと等しい*/
GROUP BY
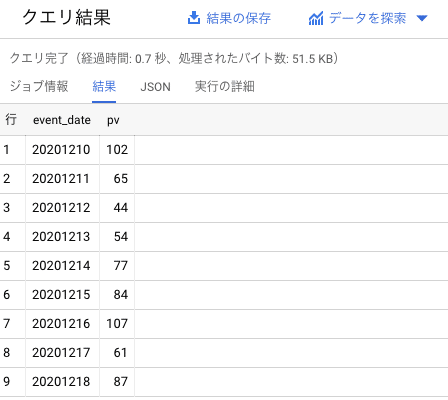
1 /*SELECTの1つ目のもの(このケースではevent_date)をグループ化して集計する*/このように使います。ちなみに、3行目の「AS」は結果を表示する際の項目名を指定するために使います(下の画像のevent_dateの隣の列がpvになっています)。カラムをそのまま表示する場合は特に指定しなくても分かりますが、集計を行った場合はカラム名が分かりづらくなってしまうのでできるだけ指定するようにしましょう。
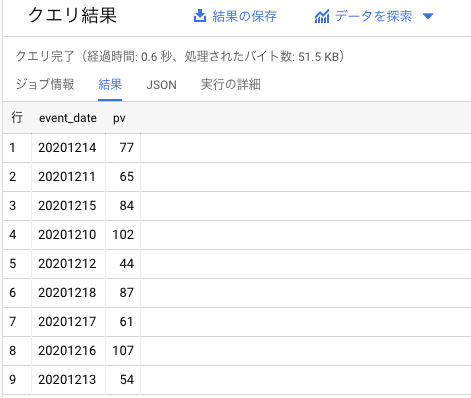
このように日別のPVを集計することができました。でもこれでは日がバラバラに並んでいて見づらいですね。そこで使用するのがORDER BYです。
SELECT
event_date, /*event_dateのカラム*/
COUNT(event_name) AS pv /*event_nameのカラムのデータ件数を数える*/
FROM
`aaaaaaaaaaaaaa.analytics_xxxxxxxxx.events_*`
WHERE
event_name = 'page_view' /*event_nameがpage_viewと等しい*/
GROUP BY
1 /*SELECTの1つ目のもの(このケースではevent_date)をグループ化して集計する*/
ORDER BY
1 /*SELECTの1つ目のもの(このケースではevent_date)を昇順に並べる*/こうすることで下の画像のように日がきちんと順番に並びます。
UNNEST
UNNESTはBigQuery特有の概念なので、これまで別のところでSQLを扱ってきた方にはあまり馴染みがないと思いますし、慣れるのに時間がかかると思います。私もまだ慣れていないです。「UNNEST」、つまり「ネストを解除する」ということなのですが、具体的に見てみましょう。
最初の「SELECT、FROM、LIMIT」で見たように、BQのテーブルはこのようになっています。
SELECT
*
FROM
`aaaaaaaaaaaaaa.analytics_xxxxxxxxx.events_*`
LIMIT
100
1番左の行は1, 2, 3となっているのに対し、event_params.keyやevent_params.value.string_valueは1つの行の中に複数のデータが入っています。これが「ネストされている」ということです。この状態だとWHEREでの条件指定などがうまくできません。例えば、「event_params.key = 'page_title'」などと記載してもエラーになってしまいます。そこで必要になるのがUNNESTです。
SELECT
*
FROM
`aaaaaaaaaaaaaa.analytics_xxxxxxxxx.events_*`,
UNNEST(event_params) AS params
LIMIT
100こうすることで実行結果の右の方にevent_paramsの内容が1行に1つになった状態でくっついてきます。

そのため、WHERE句の中で条件指定などを行うことができます。
SELECT
event_timestamp,
params.key,
params.value
FROM
`aaaaaaaaaaaaaa.analytics_xxxxxxxxx.events_*`,
UNNEST(event_params) AS params
WHERE
params.key = 'page_title' /*「params」はUNNESTの行でASで指定した名称*/
LIMIT
100
このように、1行に1つずつkeyやvalueを表示することができました。
UNNESTはちょっと分かりづらいので、もっと詳しく知りたい方はこの記事などを読んでみてください。
JOIN
SQL初心者の方が1番つまずきやすいポイントがこのJOINです。JOINは複数のテーブルを組み合わせてデータを抽出したいときに使います。イメージとしてはExcelのvlookup関数が近いです。
話を分かりやすくするために、このような簡単な表について考えてみます。

tableAには商品のIDと名称が、tableBには商品のIDと価格があります。この商品のうち、商品価格が150円以上の商品名だけを絞り込みたい、という場合にはどちらかのテーブルだけでは情報が足りないので、tableAとtableBを結合する必要があります。その結合に使用するのがJOINです。
SELECT
*
FROM
tableA
JOIN
tableB
ON
tableA.product_id = tableB.product_id今まで使ってきたFROMだけでなく、もう1つのテーブルを指定するために「JOIN」という句が登場します。JOINで2つ目のテーブルを指定し、「ON」で2つのテーブルを紐づけるためのキーを指定します。ここではtableAのproduct_idとtableBのproduct_idが同じものを紐づけるように指定しています。
これの実行結果は次のようになります。

このように、tableAとtableBが同じproduct_id同士で結合されました。こうなれば、150円以上の商品を絞り込むのは簡単ですね。
SELECT
*
FROM
tableA
JOIN
tableB
ON
tableA.product_id = tableB.product_id
WHERE
tableB.price >= 150
このようにWHEREで150円以上を指定するだけです。ここではSELECTは*にしていますが、もちろん特定のカラムのみを指定することもできます。
WITH
先ほどのJOINの例ではtableAもtableBもそのままの状態で結合しました。しかし、実践ではより大量のデータを扱うことが多く、そのままの状態で2つのテーブルを結合してしまうと計算に時間がかかったり、BigQueryのクエリが重くなり課金対象データが増えてしまう可能性もあります。そこで使われるのがWITHです。
例えば、次のようなテーブルを考えてみましょう。

tableAは先ほどと同じですが、tableBは日付と販売個数になっています。まずはこれをそのままJOINすると、このようなテーブルになります。
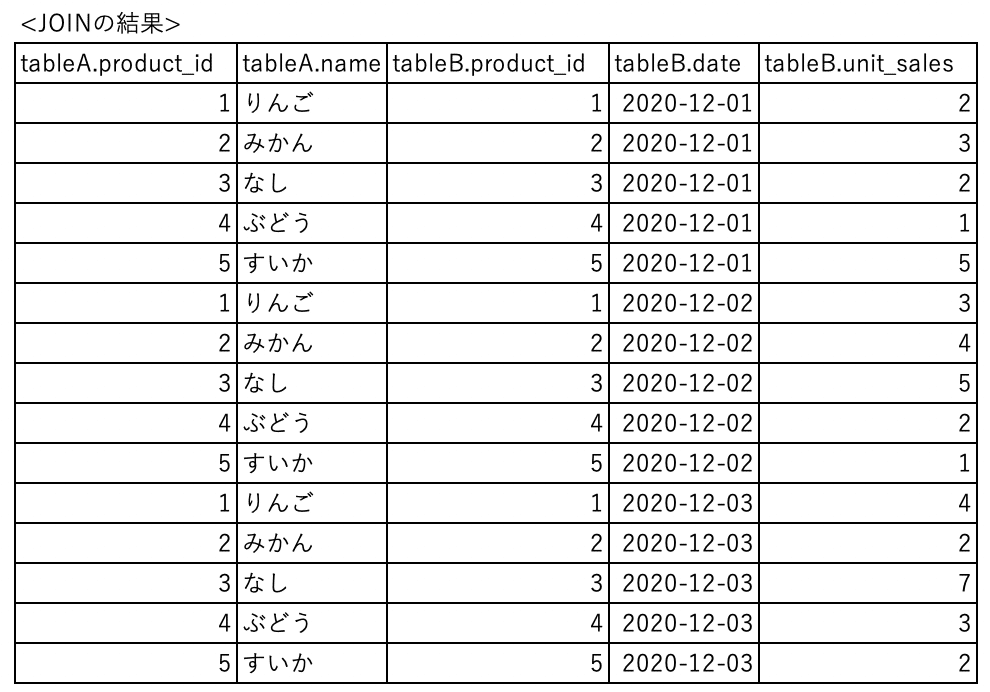
もっと日付が長くなったり、商品数が多くなるとめちゃくちゃデータ数が多くなるのは想像できると思います。そこで、JOINする前に各テーブルから必要なカラムやレコードのみを抜き出してから結合するという方法があります。そこで使うのがWITHです。
例えば、12月1日の販売個数のみを集計したいという場合はこのようになります。
WITH
name_table AS (
SELECT
product_id,
name
FROM
tableA
),
sales_table AS (
SELECT
product_id,
date,
unit_sales
FROM
tableB
WHERE
date = '2020-12-01'
)
SELECT
name_table.name,
sales_table.unit_sales
FROM
name_table
JOIN
sales_table
ON
name_table.product_id = sales_table.product_id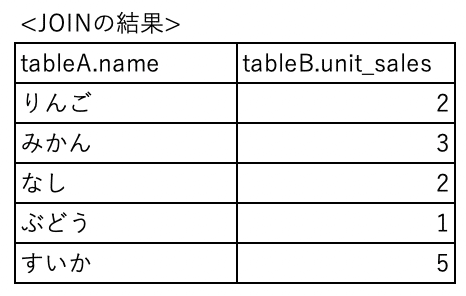
まず、WITHの中でテーブルの下処理を行います。「name_table」や「sales_table」は処理後に新しくできたテーブル名として指定します。「新しいテーブル名 AS ()」という形式になっており、()の中は今までと同じようにSELECT、FROM、WHEREなどが入ります。もちろんGROUP BYなどもそのまま使えます。複数のテーブルの下処理が必要な場合は「,」で区切ります。
下処理が終わったら、そのままSELECTから始めてクエリを書いていきます。FROMやJOINのテーブル名に指定するのは下処理後のテーブルの名前です。
ユーザー定義関数
ここまで集計に使う関数や時間に関する関数などをいくつか紹介しましたが、BiigQueryでは自分で定義した関数を作ってそれを使うことができます。
例えばこんな感じです。
CREATE TEMPORARY FUNCTION getDate() AS (FORMAT_DATE('%G%m%d', DATE_SUB(CURRENT_DATE('Asia/Tokyo'), INTERVAL 1 DAY)));
SELECT
*
FROM
`aaaaaaaaaaaaaa.analytics_xxxxxxxxx.events_*`
WHERE
_table_suffix = getDate()1行目のCREATE〜の部分で関数を定義しています。
ASの後ろを見ると、日本時間での現在の日付を取り、そこから1日を引いて、日付の表示形式を「%G%m%d」(つまりYYYYMMDD形式)にしています。
これを「getDate()」という関数として定義しているわけです。
こうすることで、クエリの中で実際にいちいち長い関数を書かなくても「getDate()」と書けば昨日の日付が取得できるようになっています。
実際にはこの程度の短いクエリならわざわざ最初に定義する必要はあまりなく直接クエリの中に書けばよいのですが、例えばWITH句を使って何度も同じ日付を参照するようなクエリの場合だと、最初に定義してその関数を使って書くようにすれば、違う日付のデータを見たいときはユーザー定義関数だけを直せば良いので非常に楽ですし、読みやすいクエリになります。
もちろん、日付関連だけではなく数値や文字列など、様々なものを関数として定義することができます。
コンバージョンしたユーザーがコンバージョン前にどのページを見ていたかを確認するクエリ
ここまでに登場したものを全て組み合わせると、冒頭でご紹介したコンバージョンしたユーザーがコンバージョン前にどのページを見ていたかを確認するためのクエリを書くことができます。改めて見てみましょう。
CREATE TEMPORARY FUNCTION getDate() AS (FORMAT_DATE('%G%m%d', DATE_SUB(CURRENT_DATE('Asia/Tokyo'), INTERVAL 1 DAY)));
WITH
cv_sessions AS (
SELECT
value.int_value AS ga_session_id
FROM
`aaaaaaaaaaaaaa.analytics_xxxxxxxxx.events_*`
,UNNEST (event_params) AS event
WHERE
_table_suffix = getDate()
AND event_name = 'inquiry'
AND key = 'ga_session_id'
)
,sessions AS (
SELECT
value.int_value AS ga_session_id
,event_bundle_sequence_id
FROM
`aaaaaaaaaaaaaa.analytics_xxxxxxxxx.events_*`
,UNNEST (event_params) AS event
WHERE
_table_suffix = getDate()
AND event_name = 'page_view'
AND key = 'ga_session_id'
)
,events AS (
SELECT
event_bundle_sequence_id
,value.string_value AS page_url
,FORMAT_TIMESTAMP('%F %T', DATETIME(TIMESTAMP_MICROS(event_timestamp), 'Asia/Tokyo')) AS datetime
FROM
`aaaaaaaaaaaaaa.analytics_xxxxxxxxx.events_*`
,UNNEST (event_params) AS event
WHERE
_table_suffix = getDate()
AND event_name = 'page_view'
AND key = 'page_location'
)
SELECT
cv_sessions.ga_session_id
,events.datetime
,events.page_url
,CASE
WHEN events.page_url = 'https://******.com/thanks' THEN '問い合わせ完了'
ELSE NULL
END AS inquiry_flag
FROM
cv_sessions
JOIN
sessions
ON cv_sessions.ga_session_id = sessions.ga_session_id
JOIN
events
ON sessions.event_bundle_sequence_id = events.event_bundle_sequence_id
ORDER BY
1, 2まずユーザー定義関数として「昨日の日付」を取る関数を作っています。
WITH句の中には3つのサブクエリがあります。
cv_sessionは「event_name = 'inquiry'」の部分でコンバージョンしたユーザーのみを参照し、ga_session_idを取得しています。※ここではコンバージョンのイベント名は「inquiry」としていますが、実際の環境に合わせて変えてください。
sessionsではpage_viewが発生しているセッションのga_session_idとevent_bundle_sequence_idを取得しています。
eventsでは各PVでのevent_bundle_sequence_id、閲覧ページのURL、PVイベント発生時の時刻を取得しています。
あとはga_session_idとevent_bundle_sequence_idを使ってこれらのテーブルをJOINしています。event_bundle_sequence_idというカラムは、一度に発生したイベントを1つにまとめるためのIDです。ここでは同じイベントのga_session_idとURLや時刻を紐づけるためのキーとして使用しています。あとはORDER BYを使い、ga_session_id順・時刻順に並び替えしています。
ちなみに、SELECT句の中ではCASEを使っています。この記事では説明していませんでしたが、分かりやすく言うとExcelのIF関数のようなものです。ここでは、「page_urlが 'https://******.com/thanks' だったら '問い合わせ完了' と記載する」という風になっています。
これを実行するとこのようにコンバージョンセッションごとのPVが確認できます。この例では、ga_session_idの末尾が4・5・8と、3つのセッションでCVが発生しています。トップページからスムーズにコンバージョンしている人や、サービス紹介ページや事例ページなどを見てからコンバージョンしている人がいることが分かります。

まとめと次の課題
この手順に沿っていけば、基本的なSQLのことは理解できると思います。ここまでできればあとは練習あるのみです。とにかく書いて、エラーが出て、エラーになった箇所を修正する、を繰り返していくことでどんどん複雑なSQLを書けるようになっていくと思います。
また、SQLの書き方は1つではありません。ここで紹介したものとは違う書き方でも同じ結果が出ることもありますし、もっと効率的な(書く文字数が少なかったり、クエリの実行が早かったり)クエリもあるかもしれません。そのあたりはパズル的に楽しんでください。
次のステップに進むために絶対に避けては通れない項目が「OUTER JOIN」と「INNER JOIN」の違いを理解することです。実はこのnoteでご紹介したJOINはINNER JOINの方で、OUTER JOINは説明していません。少しややこしいですが、絶対に理解をしないといけないポイントなので、ここの内容を理解した方はぜひ調べてみてください。
練習問題
・日別のコンバージョン数を集計してみましょう
・日別、流入経路別のコンバージョン数を集計してみましょう
・コンバージョンに至ったセッションのランディングページを調べてみましょう
練習問題はそのうち解答編を作ろうと思います。
最後に
このnoteでは、短時間でSQLの基礎を学ぶ方法をご紹介しました。最初に取り掛かるのはどうしても心理的なハードルがありますが、やってみると意外と簡単だな、と思われると思います。SQLはとにかく量を書かないと覚えないと思うので、ぜひ千本ノックのように自分に課題を出して書き続けてみてください。
クエリを書いていてどうしても行き詰まった方はtwitterまでご連絡ください。時間があるときであればご回答します。
今回の記事が参考になった方は、ぜひnoteのスキ、twitterのフォローしてください!!
Meetyも開けてますので、ご興味ある方いらっしゃればぜひお話しましょう!
また、ニーズあればアプリ編(adjustとBQの連携でSQLを書く)も書いてみようかと思っていますのでご希望あれば教えてください。
よろしければサポートお願いします!そのうちオリジナルドメインにしたいなと思っているのでその資金にさせていただきます!